Keboola Storage
This data source connector loads single or multiple tables from a Keboola project and stores them in a bucket in your current project. The component can be used in situations where Data Catalog cannot, e.g., when moving data between two different organizations or regions.
Prepare API Token
Section titled “Prepare API Token”The connector requires an API Token with read-only access to a single bucket. This limits the potential risks of token misuse.
To create such a token, go to Users & Settings in the source project and create a new token. Use a name that will help you identify the token later, and set the read access to the desired bucket.
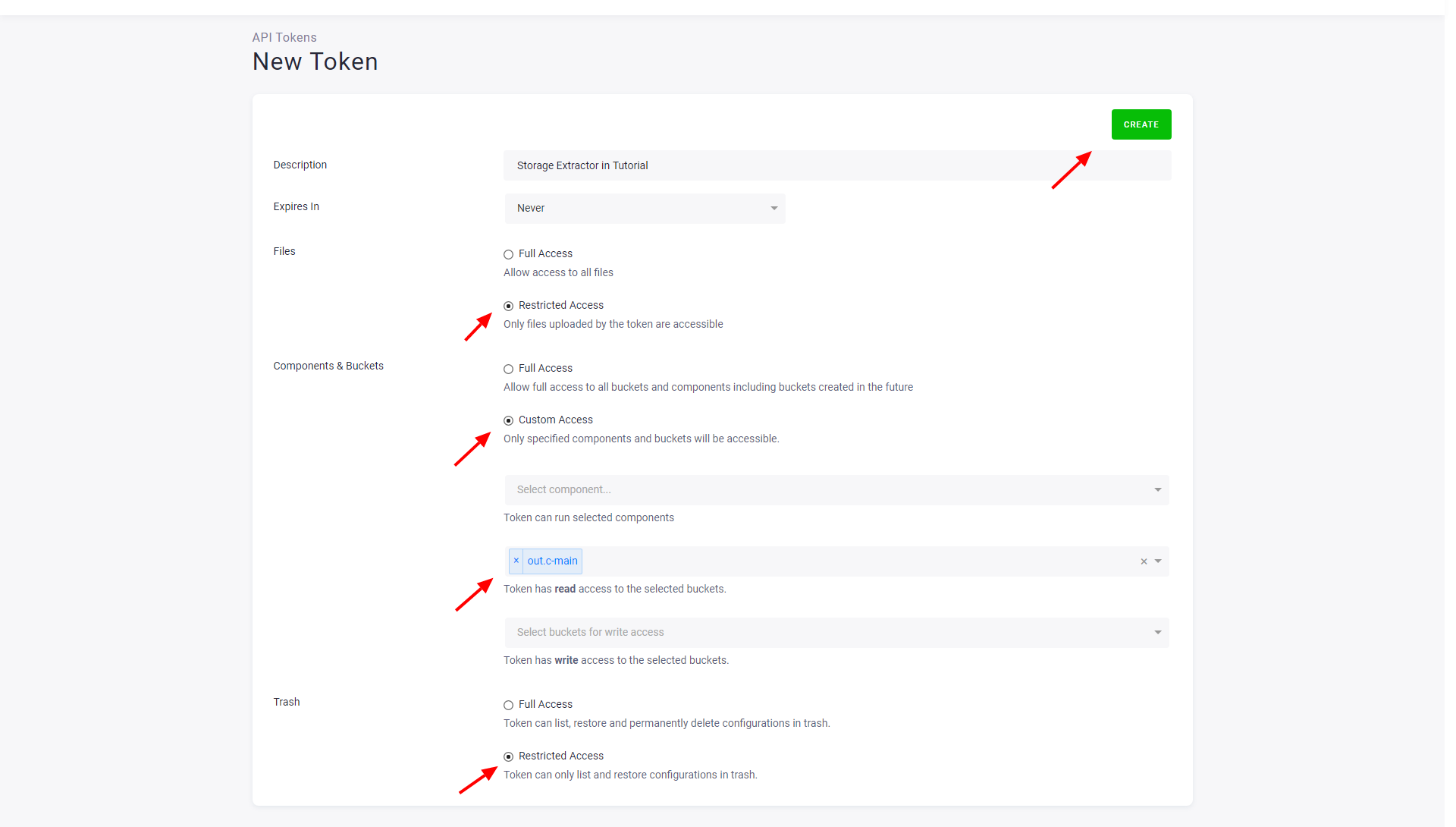
After creating the token, copy it somewhere safe as you won’t be able to see it again. If you lose the token, you can refresh it — the current token will be deactivated and a new token will be issued.
If you want to extract from multiple buckets, you’ll have to create multiple tokens and multiple configurations.
Configuration
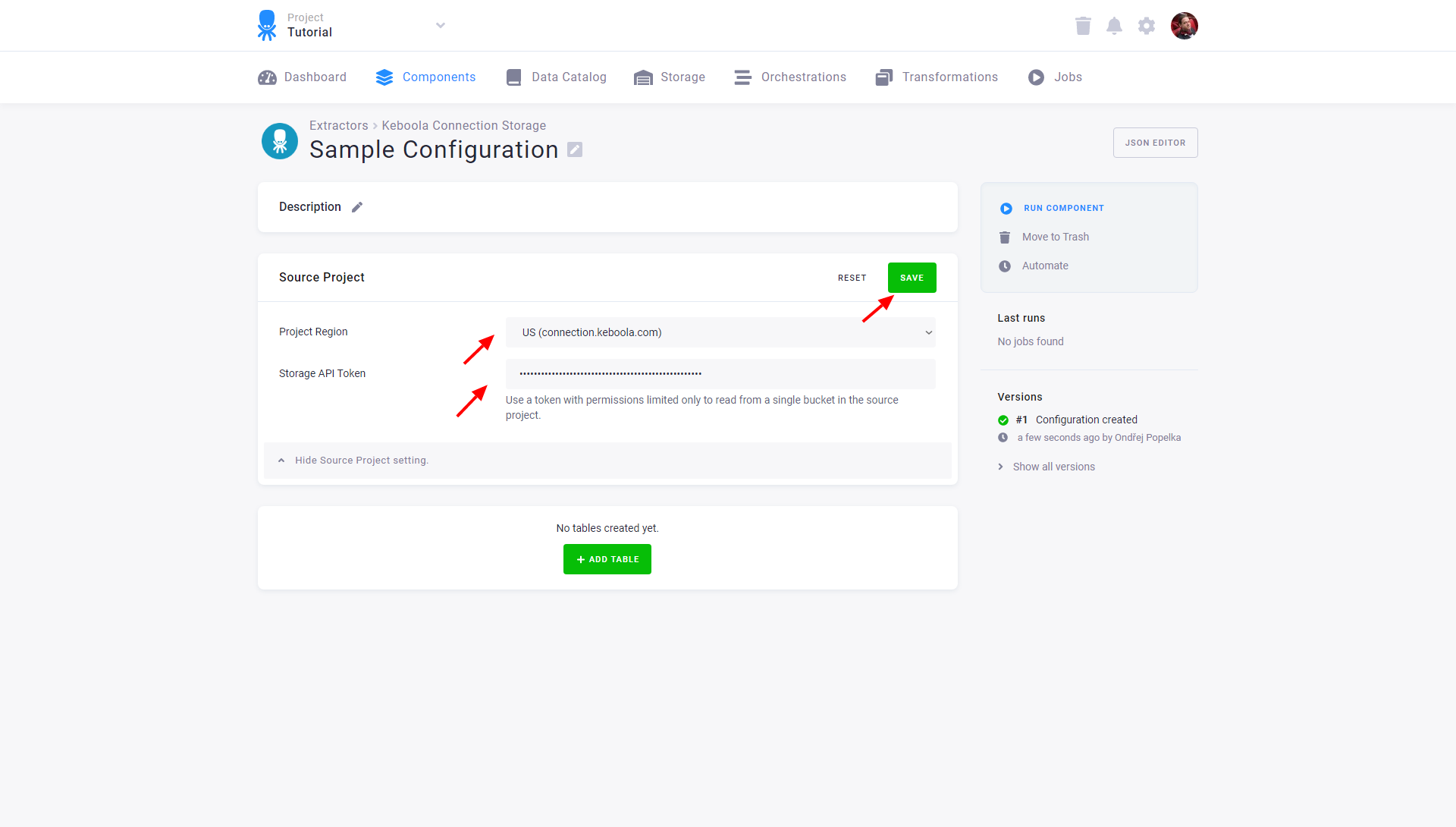
Section titled “Configuration”Create a new configuration of the Keboola Storage connector. Select the region of the source project, and paste the token you generated in the source project.
Add Tables
Section titled “Add Tables”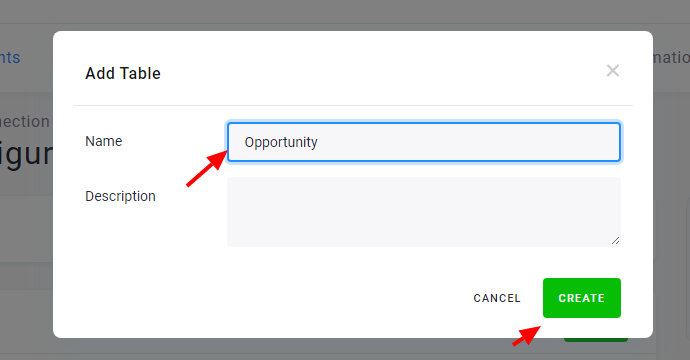
To copy a table from the source project to the current project, click Add Table. Then assign the table a name that will be used in your project. If the table name is not the same in the source and in the destination project, you can change the source table name on the next page.
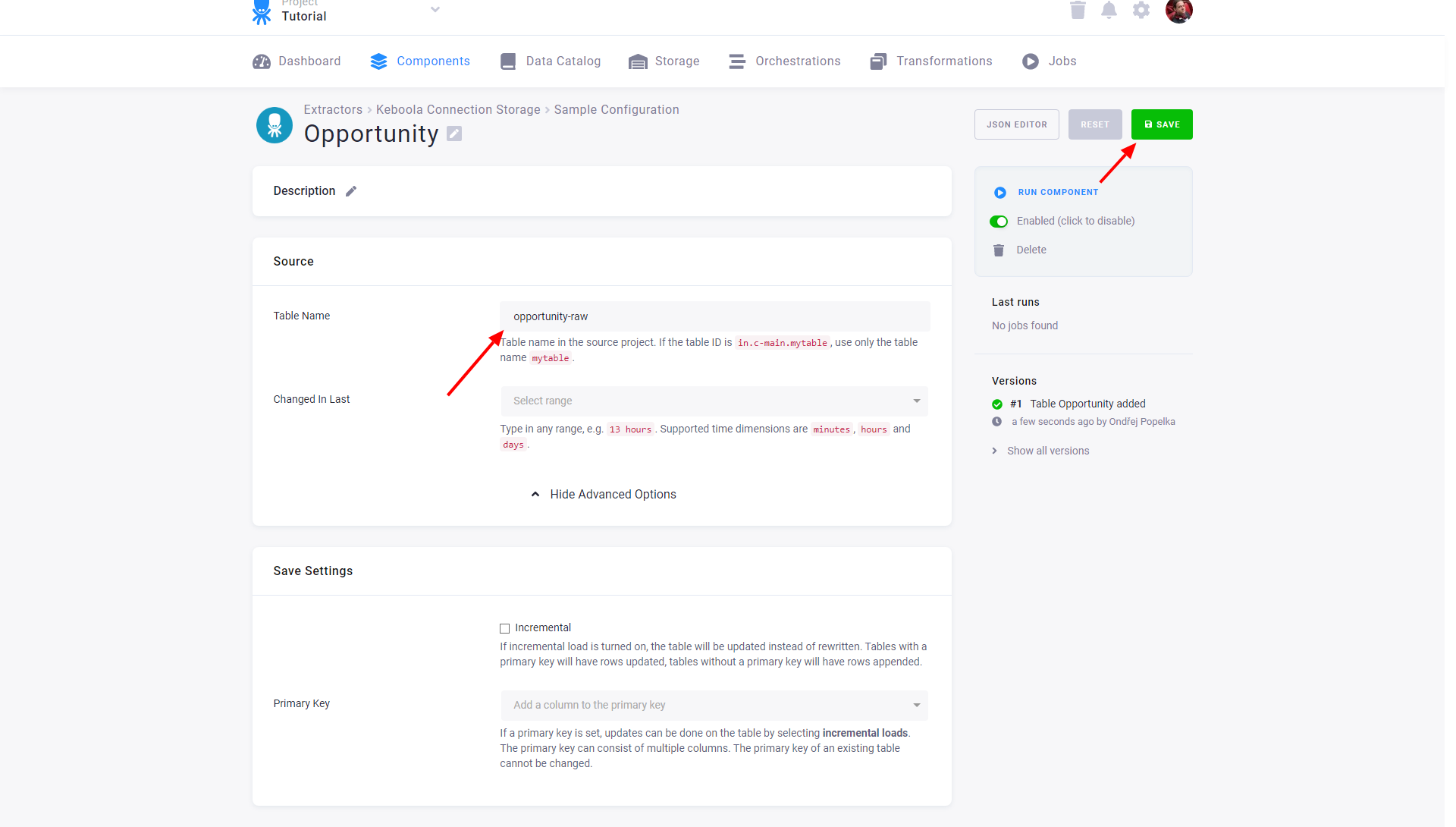
Configured tables are stored as configuration rows. Each table has different settings but they are all extracted from the same project and bucket.
Modify Table Extraction Settings
Section titled “Modify Table Extraction Settings”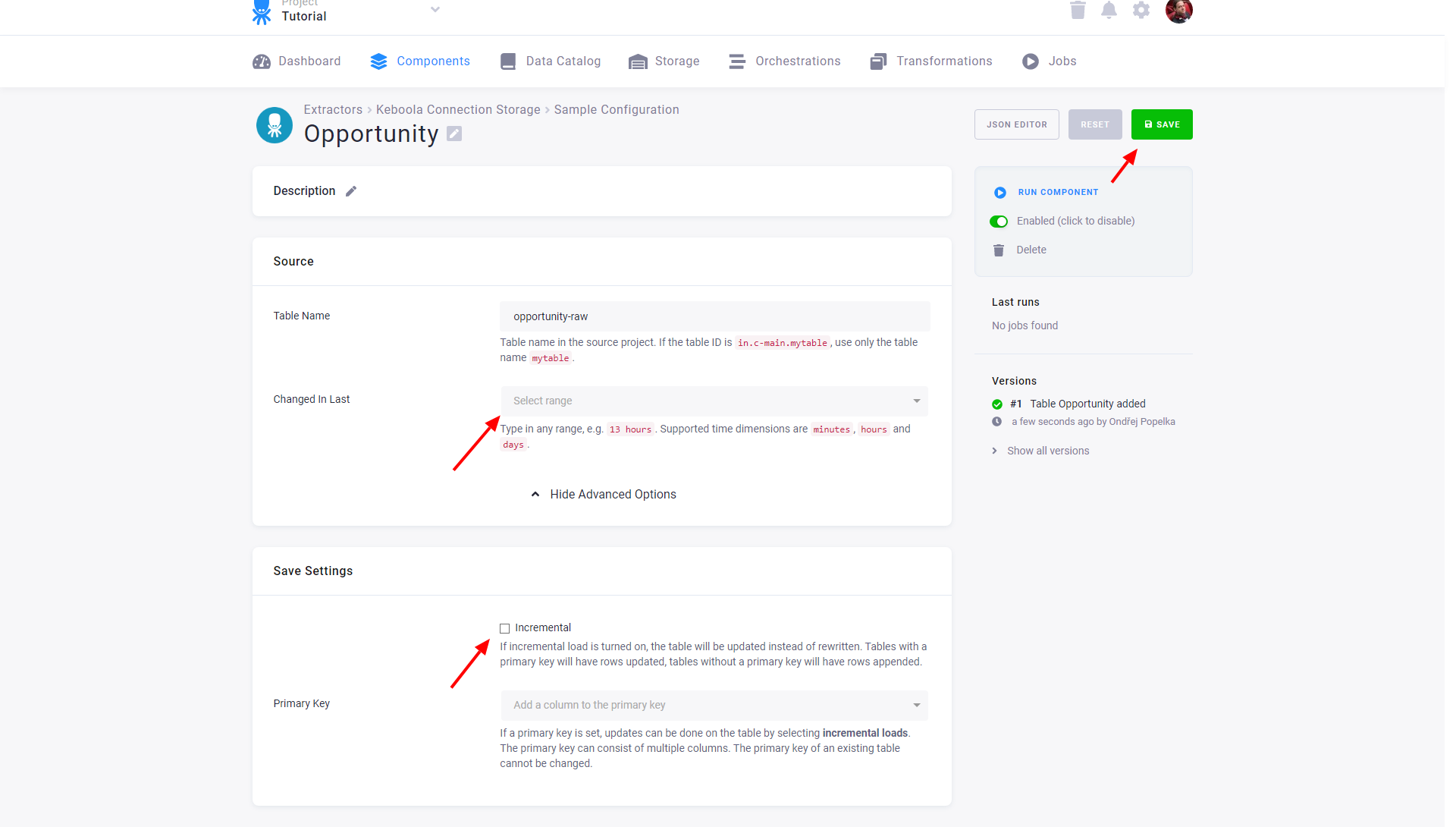
Source
Section titled “Source”- Table Name specifies the table name in the source project within the bucket to which the token has access. As the token has access to a single bucket only, you do not need to specify the bucket.
- Changed In Last allows you to extract only the recent part of the data.
Save Settings
Section titled “Save Settings”- Incremental — enables incremental loading in the current project. If the Primary Key is not set, the data is appended. Otherwise the rows with an existing primary key are updated.
- Primary Key — sets the primary key of the table in the current project. The primary key does not have to be the same as in the source project.