Running
When you’re done with your configuration of the orchestration tasks, you probably want to test it. You can run the orchestration manually:
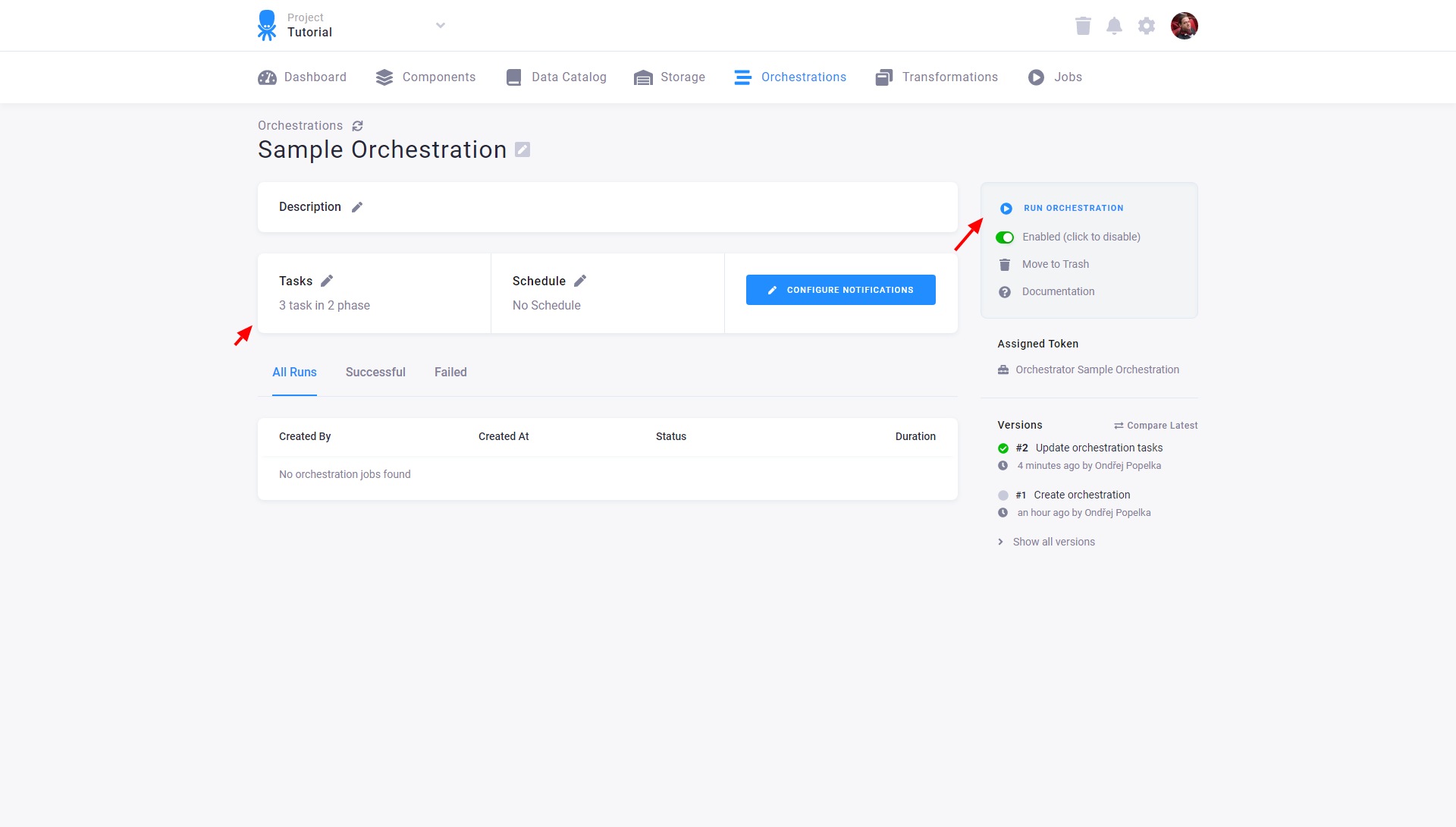
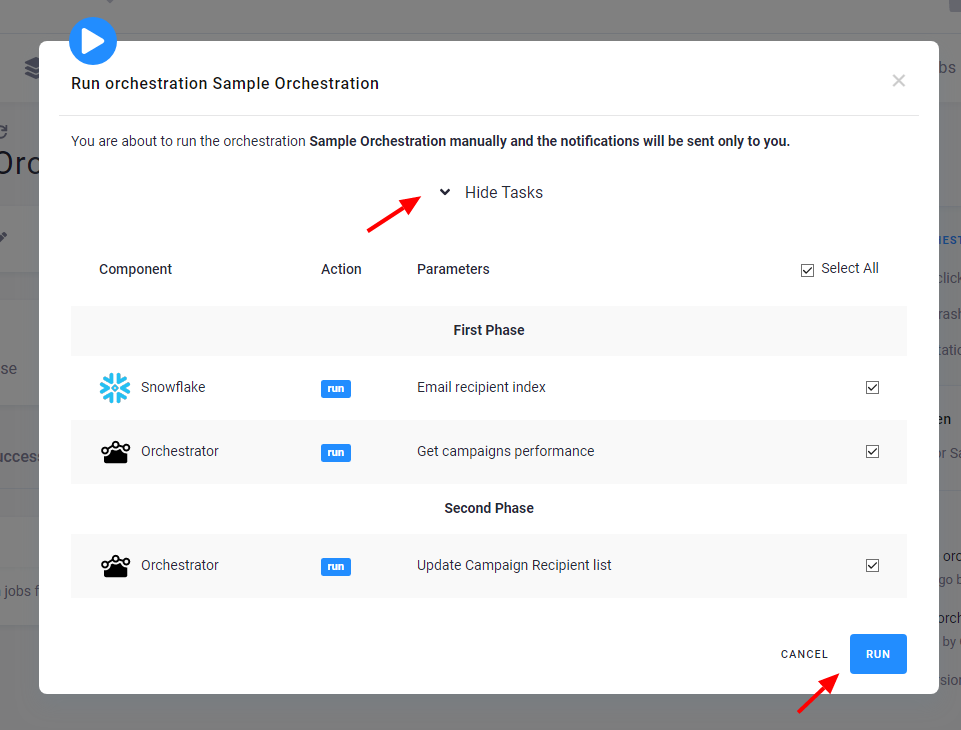
Before running the orchestration, you can review what tasks (configured components) will be executed. You can also (de)select individual tasks to exclude:
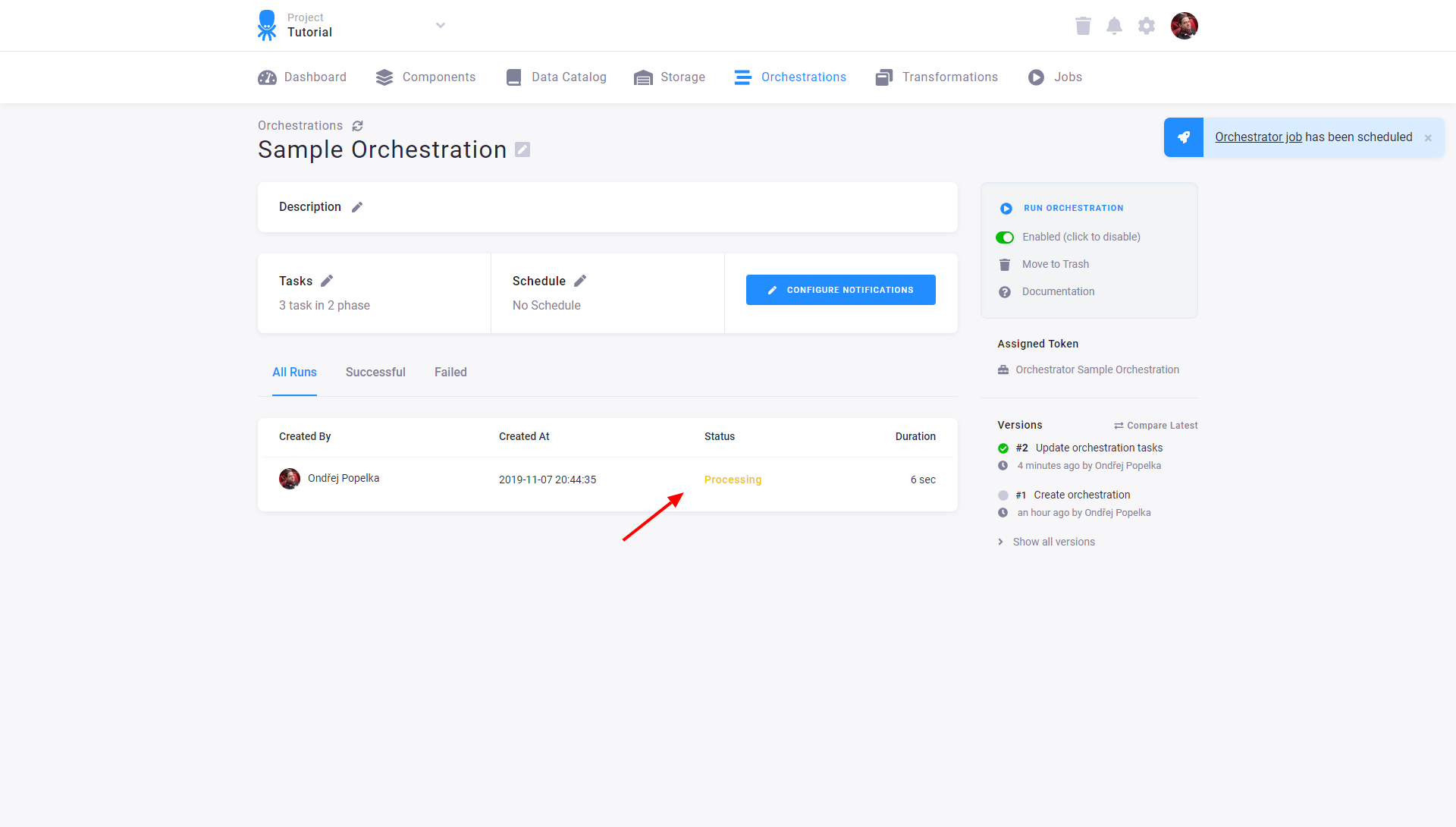
Each execution of the orchestration is shown in the Last Runs section of the orchestration:
Clicking on the job row takes you to the orchestration job details:
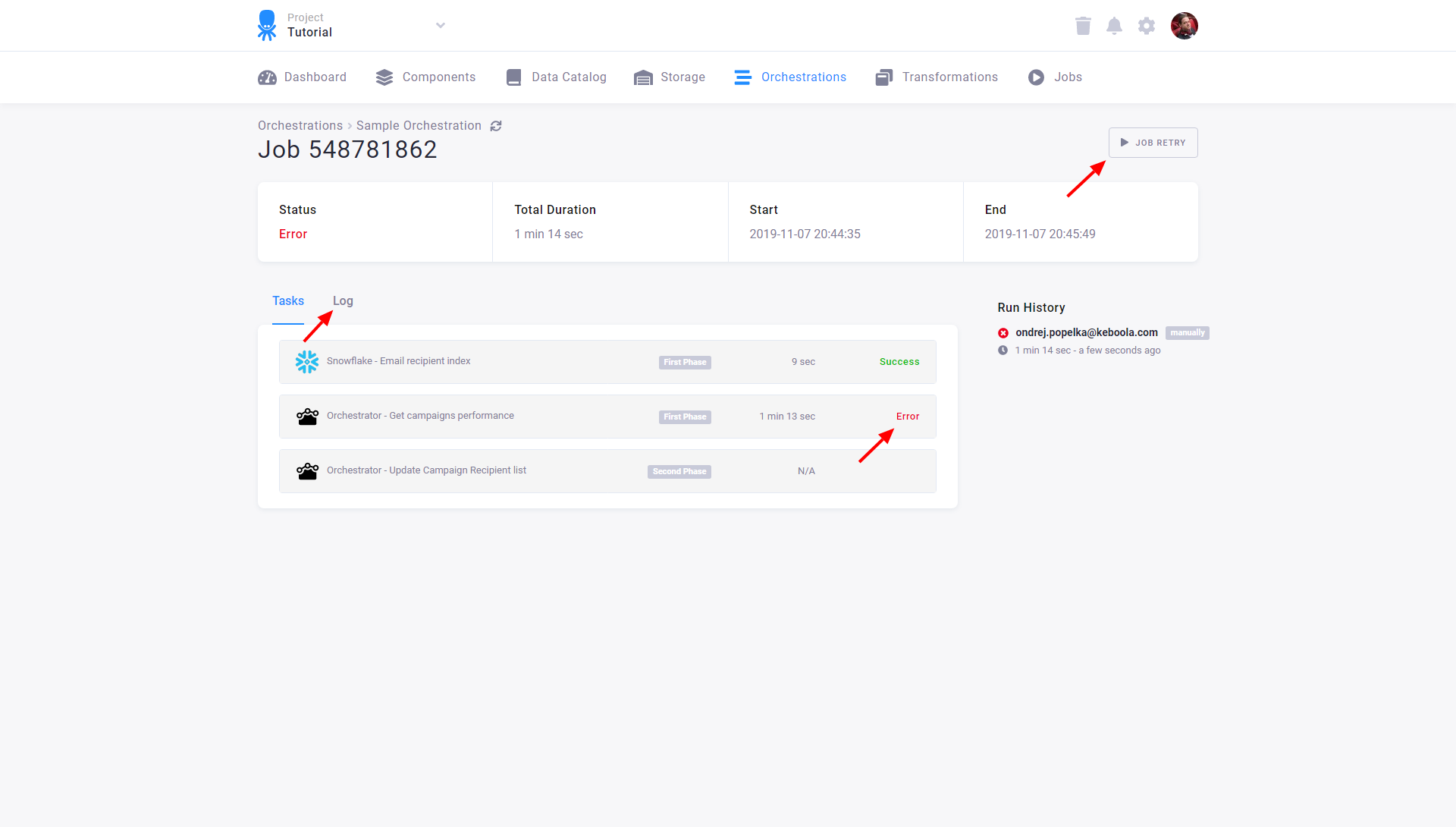
Here you can see which jobs were executed and which jobs failed. Notice that because the tasks within a phase run in parallel, the
Snowflake - Email recipient Index was started at the same time as the Adform - Campaigns task
(though it is displayed after it in the list). However, the orchestration did not continue to the second phase (transformation phase)
because the first phase had failed. You can directly retry the failed orchestration jobs by clicking Job Retry:
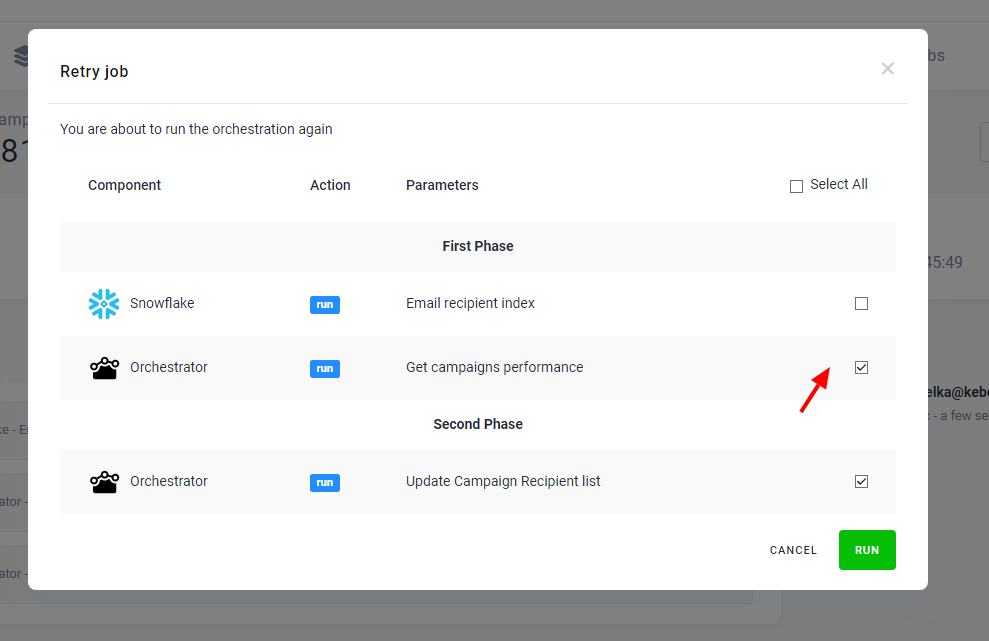
Only failed tasks and failed and not executed phases will be checked by default. Additional properties control the execution of tasks within an orchestration:
- Task can be marked as Active/Inactive. Marking the task as inactive means that it won’t be run with the orchestration. It is useful for temporarily skipping something.
- Enabling Continue on Failure on a task means that even if that task fails, the orchestration will continue running to the following
phases (and will end with a
warningstate). This feature is useful when a data source becomes temporarily unstable and you still want to try your best to extract it. - It is also possible to set Task Parameters. This is a low-level feature that modifies the parameters sent to the underlying API call.
- Action is always
run.
Automation
When you are content with the orchestration setting, it’s time to automate its execution. This is done simply by setting the orchestration Schedule:
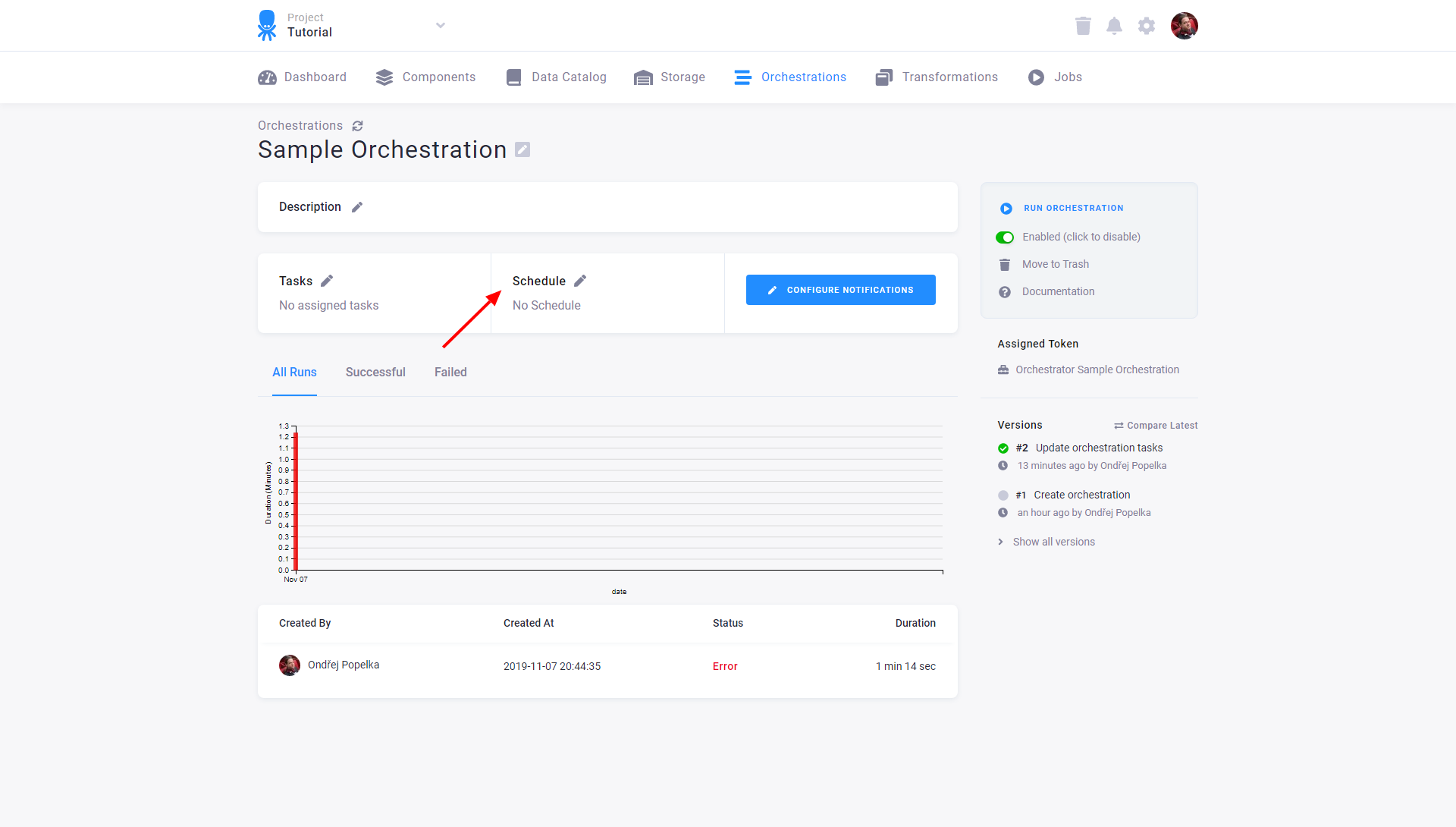
You can select from two types of scheduling:
- Time Schedule
- Event Trigger
Time Schedule
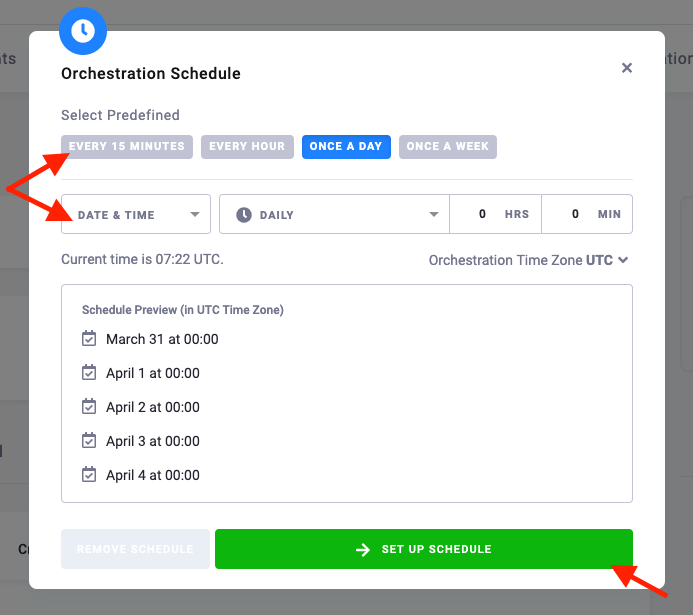
Orchestration always runs in a single unambiguous point in time. By default, the orchestration schedule is set in Coordinated Universal Time (UTC).
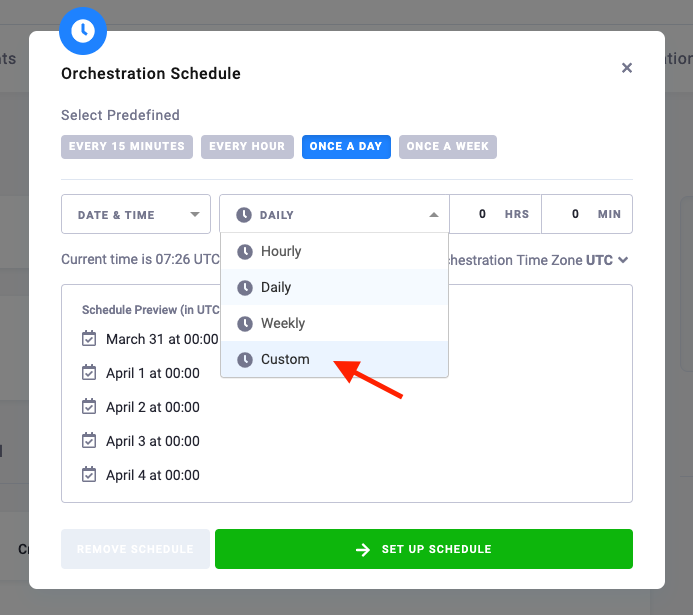
Custom Schedule
If you don’t find the predefined options useful, select a custom schedule.
Custom Time Zone
You can also set a specific time zone to be used for scheduling your orchestration. There are always two predefined time zones you can choose from: UTC and your local time zone. Keep in mind that other users may see different time zones. If the predefined options don’t fit your needs, select a custom time zone.
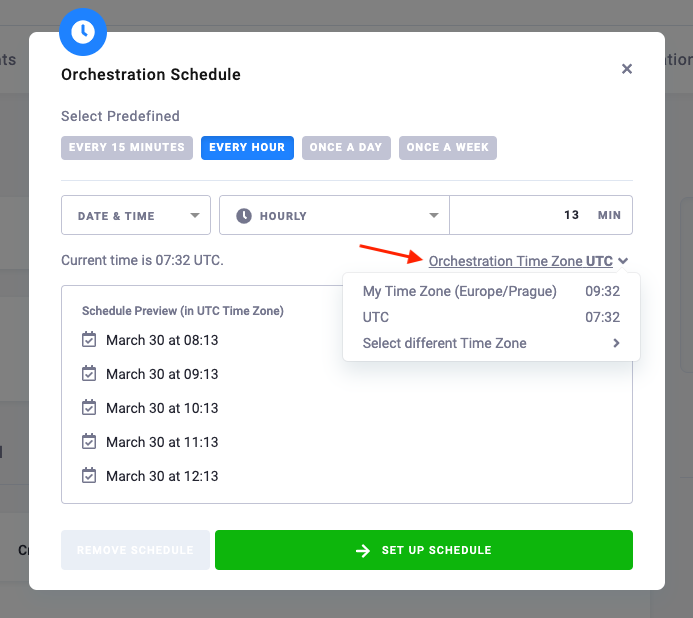
Before scheduling an orchestration, be sure to run it first to see what schedule would work best. An orchestration itself is considered a component configuration and it will not run in parallel. When you trigger an orchestration job while the previous orchestration job is still running (some of the configured tasks), the new job will be waiting until the previous one finishes. This means that if your orchestration runs for one hour and you schedule it to run every 30 minutes, you’ll still have your tables updated only once in an hour. Plus, you’ll also clog the project with waiting jobs.
Event Trigger
Instead of setting your orchestration execution for an exact time, you can wait for selected tables to be updated and run the orchestration after it happens.
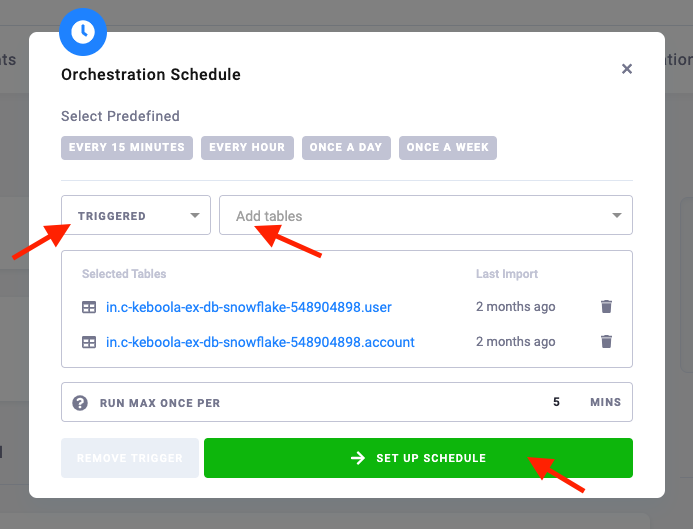
When a selected table is updated, the scheduler checks all other selected tables for updates. Once all selected tables are updated since the last orchestration execution, the orchestration will run again.
If your tables get updated very often, use a cool-down period to avoid too frequent executions. All updates will be ignored and won’t trigger an orchestration job within this period. For example, if your tables are updated every 10 minutes and you are good with 1 hour old data, set the cool-down period to 50 minutes. Your data will be updated approximately every 50-60 minutes instead of every 10 minutes.
The biggest advantage of the Event Trigger scheduling is that it can be used inside projects where you use data from shared buckets. There is no need to know when data in a shared bucket is going to be updated (unlike with Time Schedule). You can just wait for an update of the tables inside a shared bucket, and as soon as they are updated, you can run your own orchestrations.
Orchestration Execution
An orchestration is designed to run unattended. That means that a new API Token is created automatically when you create an orchestration.
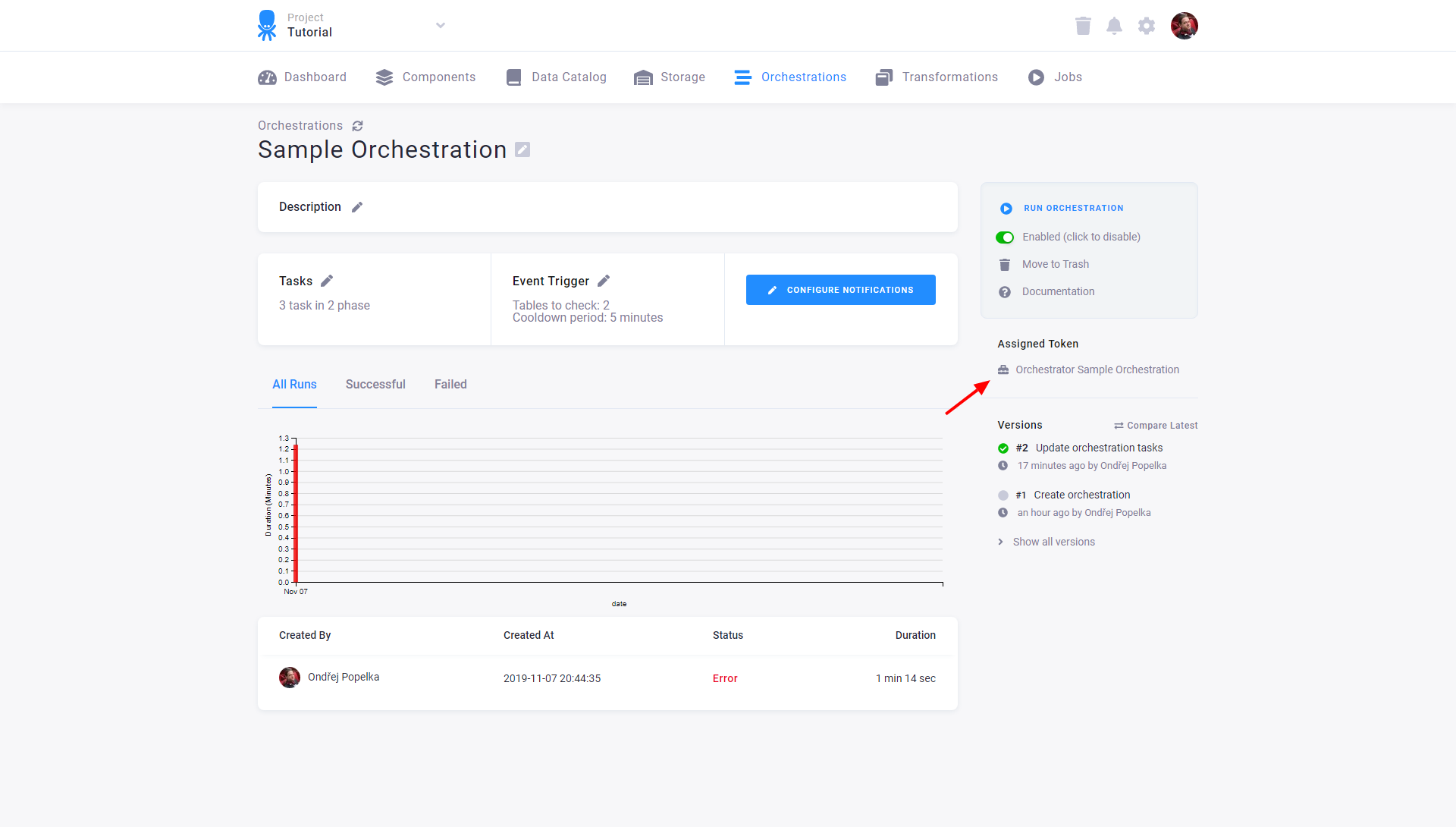
When you run an orchestration manually, the notifications are sent only to you (the user who triggered the orchestration) — the notification setting is ignored. When an orchestration runs unattended by the defined schedule, it runs as if the specified orchestration token triggered the execution. In that case, the notifications settings are honored. In either case, all the jobs created by the orchestration (data source and destination connectors, etc.) are run using the orchestration token. That is true even if you trigger the orchestration manually. There is no need to know or manually use the orchestration token.
Important: Do not delete, refresh or otherwise modify the orchestration token. There is a special API for that.
If you need to trigger an orchestration programmatically, create a new token just for this purpose. The token needs only permissions for the Orchestrator component:
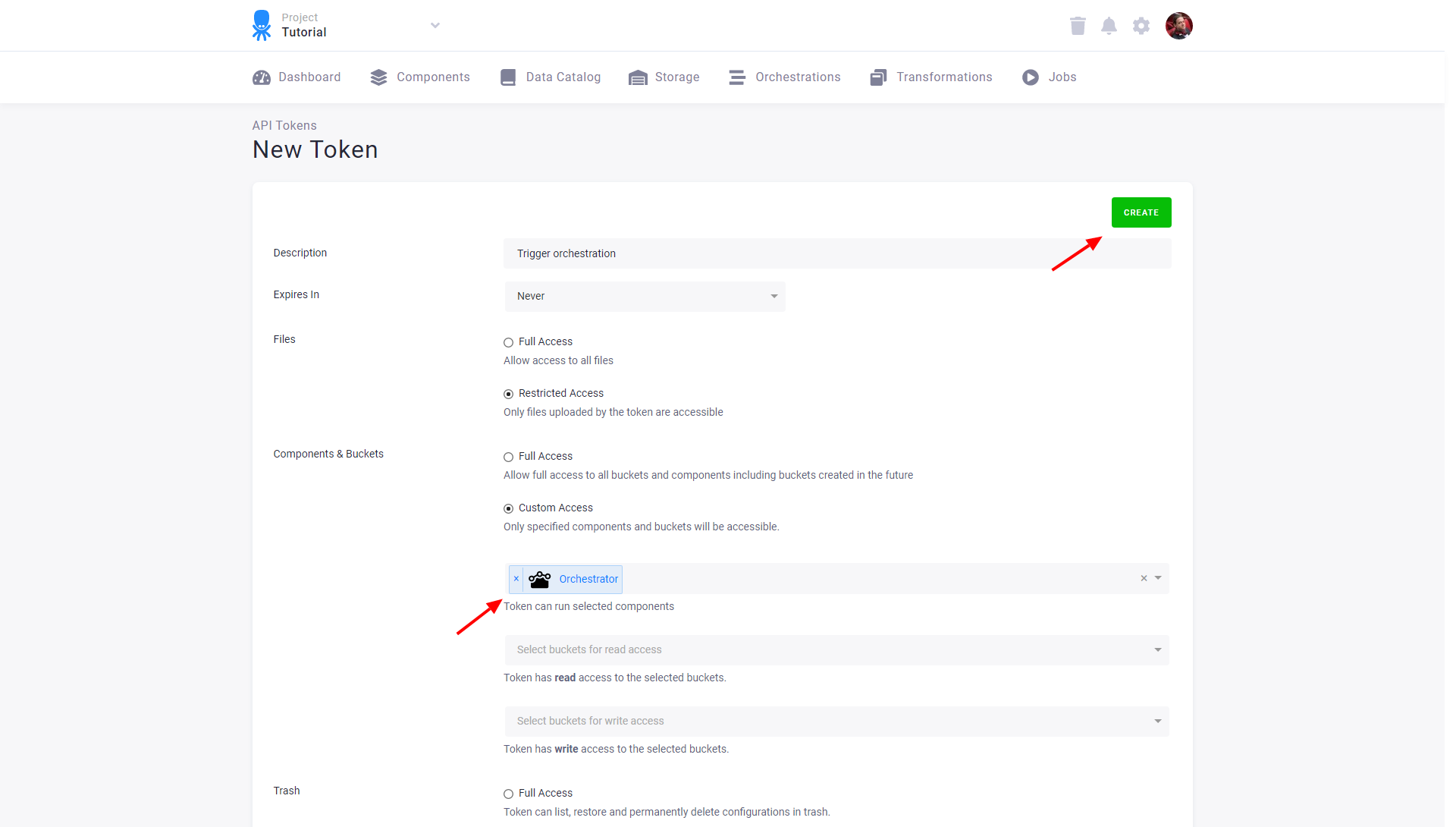
Because the actual orchestration runs with the token stored within that orchestration, the trigger token needs no access to any buckets or tables.
Note: For historical reasons, specifying the Orchestrator component in component permissions is optional. It means that the token will also work if it has access to no components.
Parallel Jobs
Running things in the Keboola platform is designed around the concept of background jobs. One of the key properties is that the same configuration of the same component cannot run in parallel. This is primarily a safety measure to maintain consistency of the output data produced by that configuration. In a more technical way, we can say that jobs running the same configuration are serialized.
The above can be added to the basic rule of orchestrations:
Phases execute sequentially, tasks within phases execute in parallel.
Which means that
- orchestration phases are serialized (and run in a defined order),
- jobs of the same configuration are serialized (and run in an arbitrary order), and
- everything else runs in parallel.
We use the word Parallel in its (usual) meaning — not serialized. Task execution is queue-based, non-deterministic, and it depends on other things happening in the project. When you run two jobs of different configurations at the same time, they will run in parallel. There is no guarantee that they will execute simultaneously or in the same order, or that shorter jobs will finish before longer jobs (i.e. the jobs may not start immediately — for example, because the shorter job was already run manually). If that happens, it does not imply that it is going to be like that every time. Never rely on coincidental or time synchronization of jobs, even if it works sometimes.
If one task relies on the results of another task, it must always be put in another phase (be serialized). For example, it is incorrect to build an orchestration on the assumption that a 5 minute task finishes well before a 2 hour task, so the 2 hour task can use the result of the 5 minute task during its execution. While this will work 99% of the time, there is no guarantee that the result of the short job will become available during the long job.
That being said, we do our best to execute jobs as quickly as possible and utilize the maximum allowed amount of parallel jobs.