Airtable
Airtable is an easy-to-use yet powerful database service that allows you to quickly create, organize, and collaborate on any project.
This data source connector allows you to fetch data from any Airtable base tables.
Prerequisites
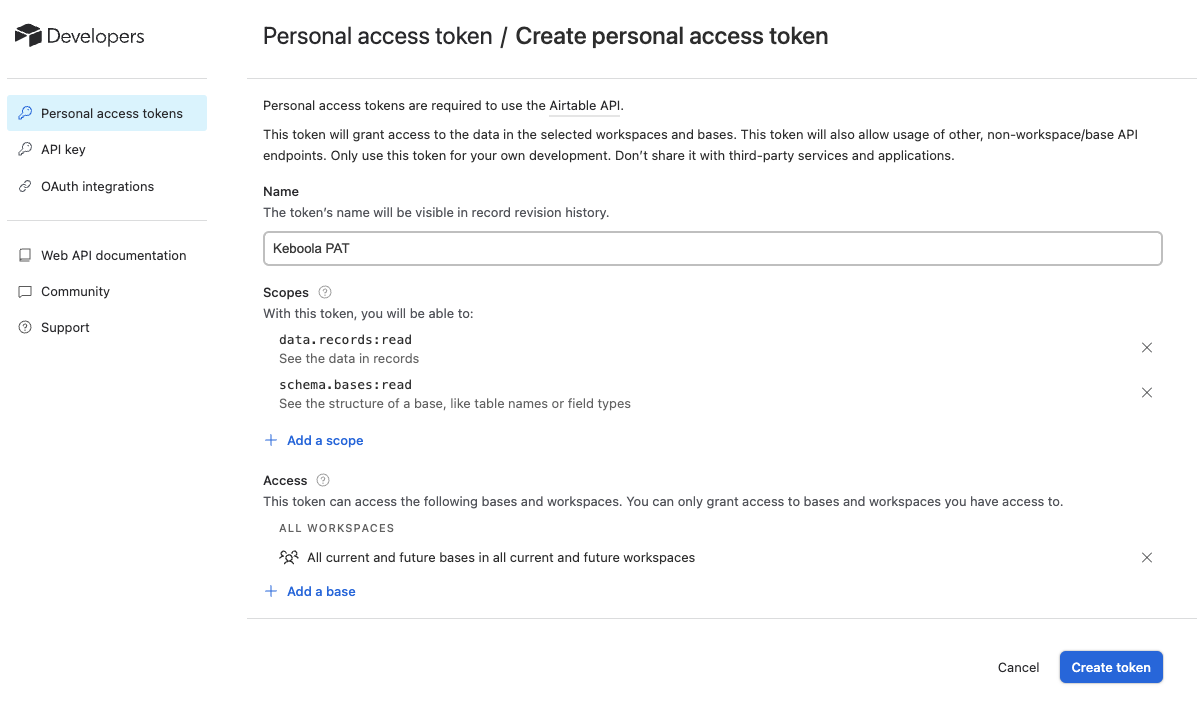
Section titled “Prerequisites”Create an Airtable PAT token:
- You can create a PAT token in the Airtable developer hub. Create read-only access for the following scopes:
data.records:readandschema.bases:read. - For more information about PAT tokens, see the documentation.
Configuration Guide
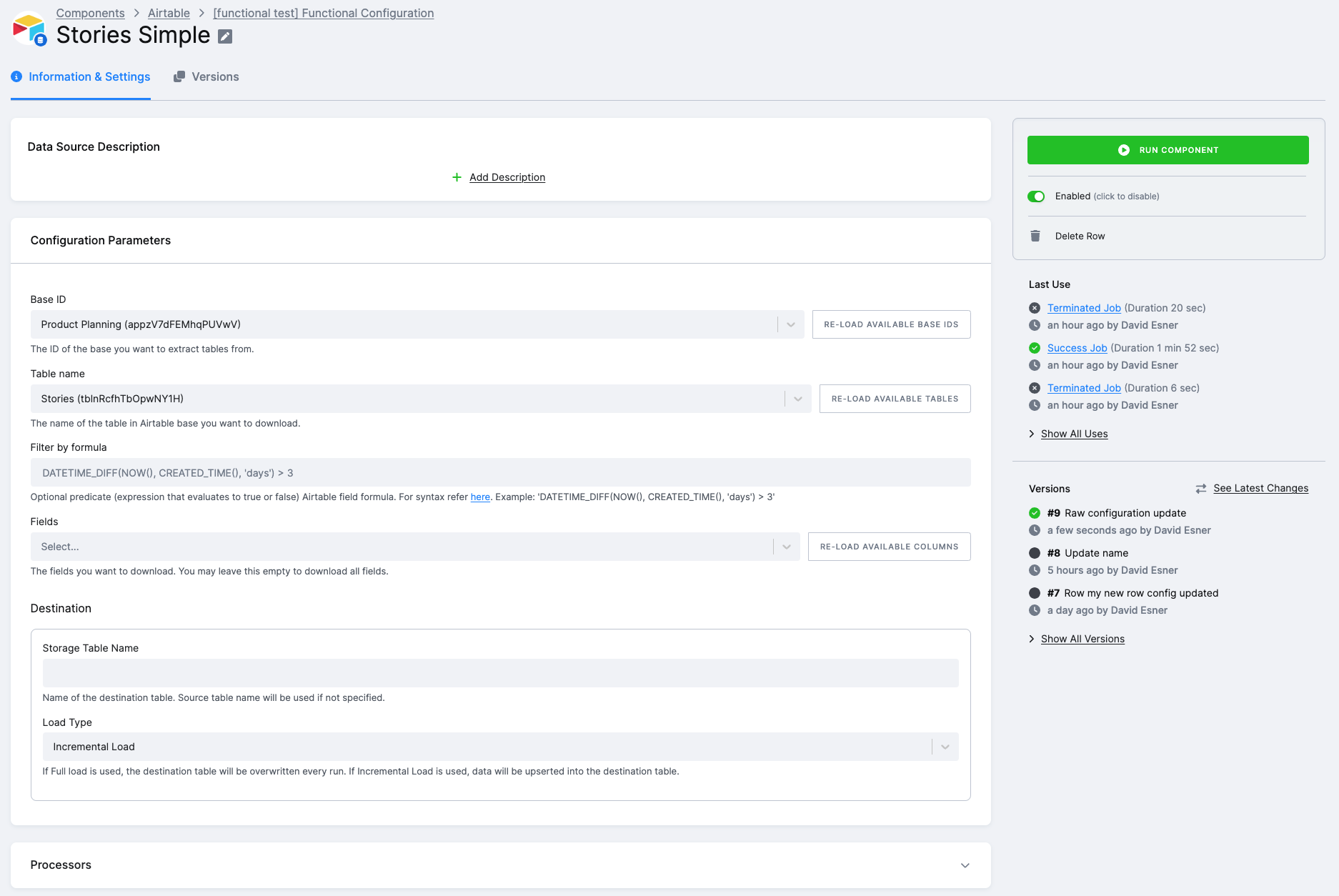
Section titled “Configuration Guide”- Create a new configuration of the Airtable data source.
- In the authorization section, enter the obtained PAT token. See the Prerequisites section.
- Create a new configuration row.
- Select a base ID. To reload available bases, click the Reload Available Base IDs button.
- Select the table you wish to sync. To reload available tables for the selected base, click the Reload Available Tables button.
- Optionally, insert a custom filter formula. For syntax, please refer here, e.g.,
DATETIME_DIFF(NOW(), CREATED_TIME(), 'minutes') < 130 - Optionally, select a subset of fields you wish to sync. If left empty, all fields are downloaded.
- Configure the Destination section:
- Optionally, set the resulting Storage Table Name. If left empty, the name of the source table will be automatically used.
- Select Load Type. If full load is used, the destination table will be overwritten with every run. If incremental load is used, data will be “upserted“ into the destination table.
Output
Section titled “Output”The output of every configuration row is always a single table in Keboola storage. If you specify a storage table name in the Destination configuration section, this name will be used; otherwise, a default name is generated based on the source table.
The output for each configuration row will consist of the main table being extracted, and, in some cases, of child tables created from certain fields of the main table.
The various field types will be parsed in the following manner:
- If the field is a list of objects, it will be omitted from the main table, and instead a row for each such object will be created in a child table named
{table_name}__{field_name}. - If the field is a list of simple values, it will be represented as a JSON string in the output table, e.g.,
["a", "b"]. - If the field is an object, it will be flattened into its table as columns named
{table_field_name}_{object_key}.