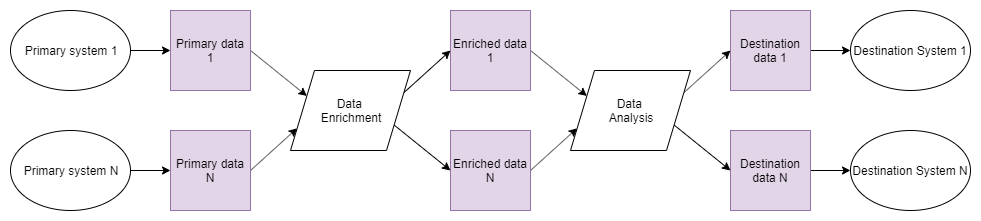
Multi-Project Architecture
Keboola is a very versatile platform and can be used in many different ways. When you deal with a larger number of source and destination systems, or when some of them are very complex or difficult to set up, you might consider splitting the traditional extract-load process into isolated projects.
Let’s say that you have a large source database and you want to provide that to data scientists. While it is very easy for a data scientist to set up a database data source connector and get all the data, it might not be a good long-term solution — for example:
- The database has some cryptic names that are hard to understand and need to be described.
- The database structure is constantly changing due to a migration process in progress.
- The database is large, and the extraction should be optimized so that it doesn’t load a 1TB table every hour all over again.
- The extraction should be synchronized with database updates or backups.
- The database contains some secure or semi-secure data which even the data analysts shouldn’t have access to.
- etc.
The multi project architecture is a solution to these kinds of problems. It is not really any sort of architecture, it is only a usage pattern of the Keboola platform. The idea is to create separate projects for receiving, analyzing and writing data. The projects structure can follow the organization structure, technological structure, or anything else really.
Example Scenario
Section titled “Example Scenario”Let’s say that you have an existing Keboola project that contains:
- Oracle database data source connector with the following configurations:
ora-history— The source database is over 2TB; the largest table isop_history, which can be easily loaded incrementally as records are only added; it is updated every 10 minutes.ora-crm— Tables from a CRM system. Major updates are being made to the CRM, so the structure of the tables changes often. Every two weeks, a column is renamed or a table is split into two.ora-common— Auxiliary tables with addresses and product names that are updated 4 times a year with data from the parent company.ora-is— ExtractsORA_IS_XXXbunch of tables which represent a port of a legacy information system, where column names had to fit into a 6 character limit.ora-clients— The tableapp_clientsis updated every working day at 2:30 UTC by a script that checks all connected clients.
- SQL Server data source connector with the following configuration:
sql-main— Contains the entire database of the information system; it can be extracted at any time without problems, but it contains auser_sessionstable with session cookies that can be used to steal a user session. Security requires that the table must not leave the SQL Server.
- Google Analytics data source connector:
- There are three Google Analytics accounts. One — for the main site — is managed by the IT department, the other two are managed by the marketing department (The IT department does not want to allow the marketing department to access the main site.).
- A bunch of transformations generating reports and writers.
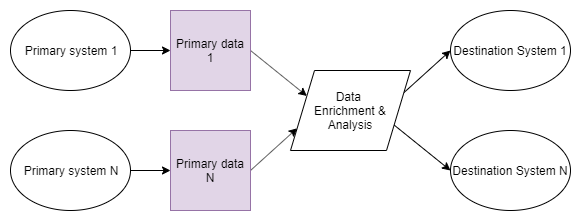
Single Project
Section titled “Single Project”The following schema shows the configurations and data exchanged between them:
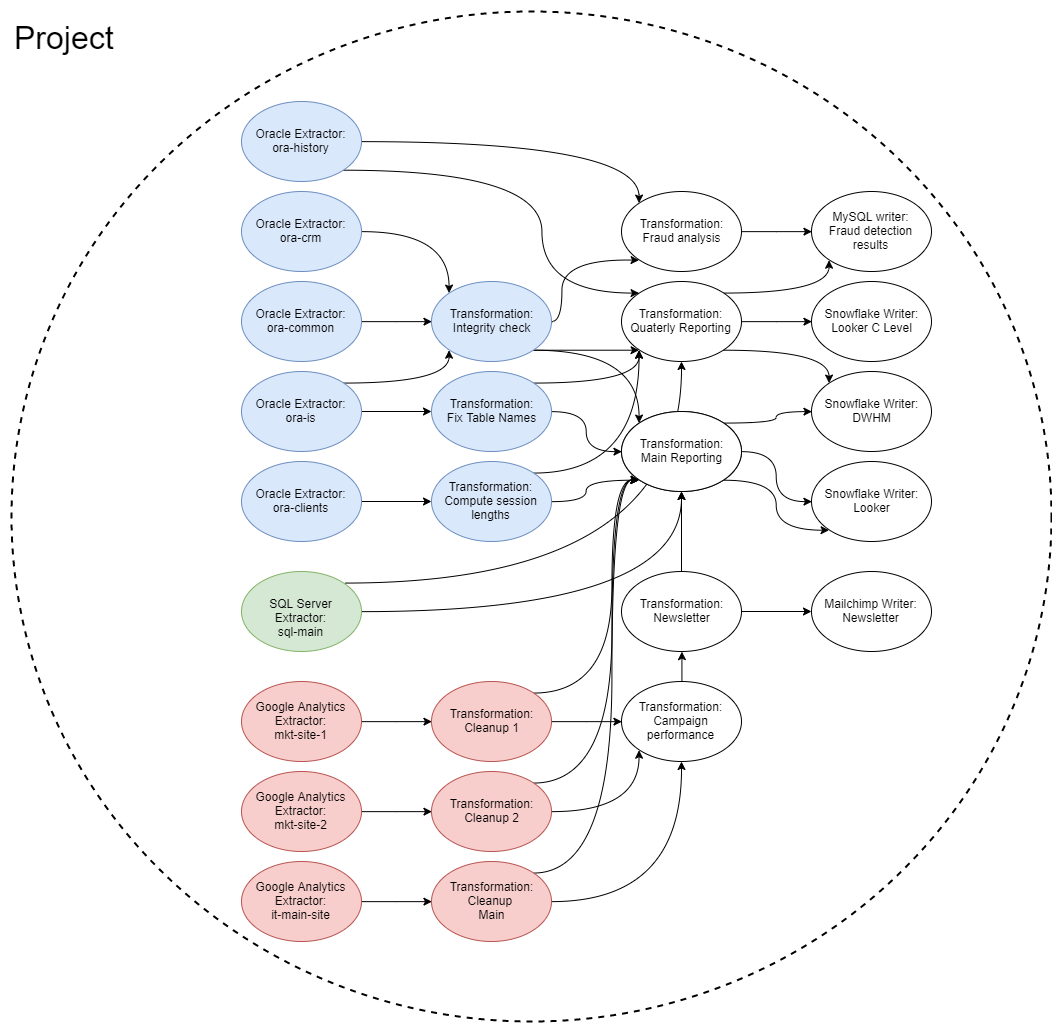
The above scenario is a simplified example of various requirements one might encounter when connecting various systems together. The important part is that nothing prevents you from setting up all those components in a single project. In the long run, however, you don’t want everyone to be responsible for everything. Multi-project architecture is just that — a way to divide responsibilities, separate concerns and build interfaces.
Multi Project
Section titled “Multi Project”The following image illustrates the usage pattern change:
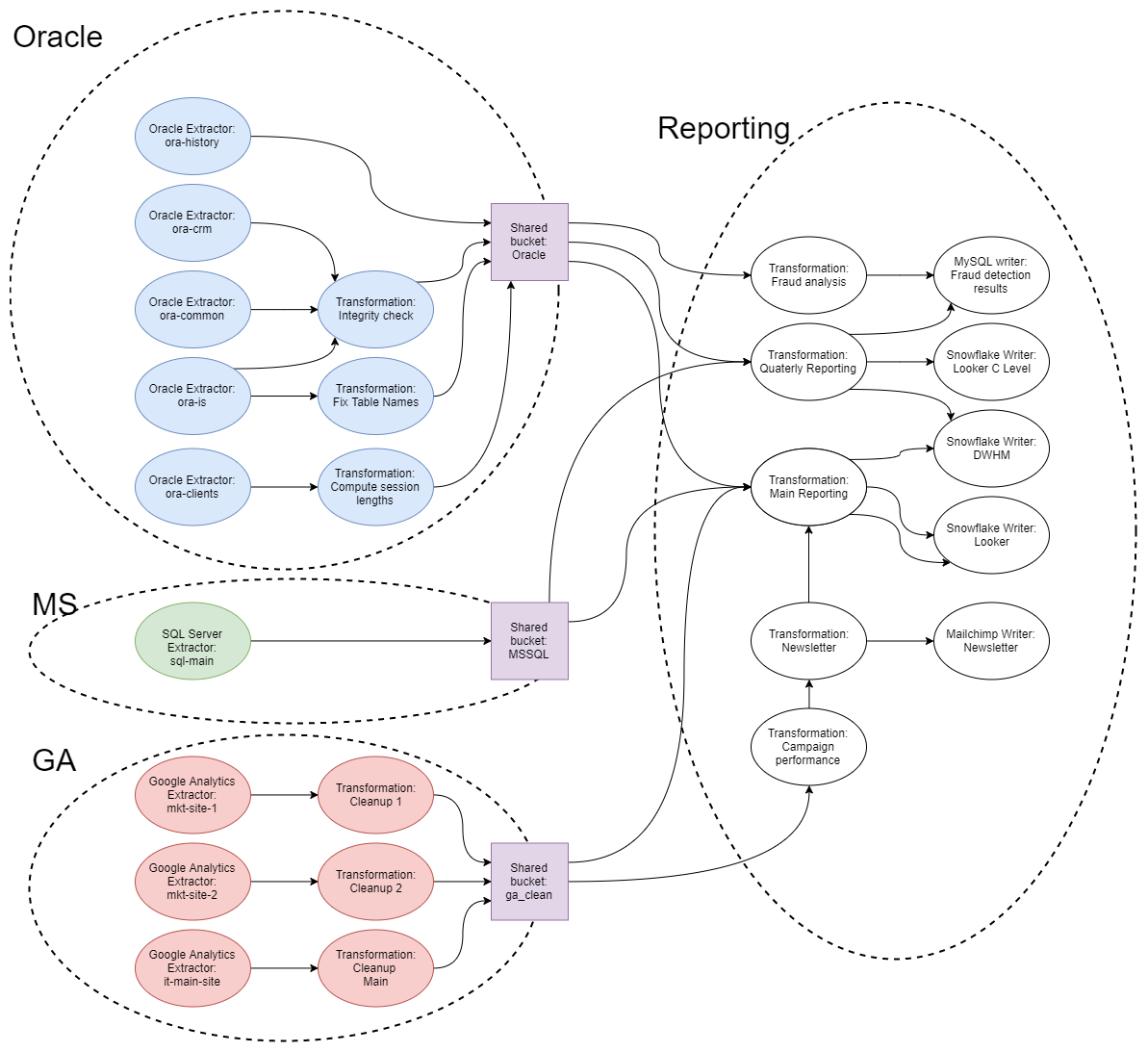
- All Oracle data source connectors have been isolated into a separate project ---
Oracle:- The Oracle DBAs take care of that project and share outside the
Oraclebucket. - Most tables are shared as they are extracted, with some transformations compensating for the changes in CRM tables. The
ora-istables are processed via transformations where the useful columns are renamed from their 6 character names to meaningful names, and the more obscure columns are omitted. The Oracle DBAs decided that it’s actually easier than to document the legacy tables. All of the Oracle tables are formally considered to be current at least every 4th hour. However, they’re updated more often, which the data scientists exploit in their event triggered flows.
- The Oracle DBAs take care of that project and share outside the
- The SQL Server data source connectors are in the
MSproject. All the tables are shared as they are extracted using aMSSSQLbucket. There are no transformations or other components. The project is only accessible to SQL Server DBAs. Formally the tables must be up to date at least every 4th hour. In reality, they are updated every hour. - Google Analytics data source connectors are all in a single project
GAmaintained by the marketing department. The data source connector for the main site (managed by the IT) is there too; it was only externally authorized by the IT department. The marketing department is responsible for basic cleaning of the data — the project contains some cleaning transformations and thega_cleanbucket is shared to the organization. The tables in the bucket are updated every 10 minutes, though the formal requirement is that they are updated at least every 4th hour. - Everything else is in the project
Reporting. It is possible to further split it to, e.g., a project taking care of newsletters and reporting.
While the above schema may look more complex and difficult to set up, it actually simplifies things a lot. It leads to a very simple statement: Everyone in the company can now access the source data and these are updated every 4th hour. When new data scientists come to the company, they can simply create a new project, use the shared data with the knowledge how often they’re updated and start working immediately. If the word “everyone” in the above statement is undesired, then the access can be tied down by using a different sharing type. The multi architecture setup also creates an interface. If the Oracle DBAs need to change anything in the database schema, they can do that in an unlimited number of arbitrarily sized steps, provided that the shared data remains same. For that they can use the entire power of SQL, Python, and R transformations combined. This is a much more flexible solution then the traditional way of creating views. Then there is, of course, the advantage that you can work with the Oracle data even when the server is down; but that’s integral part of Keboola.
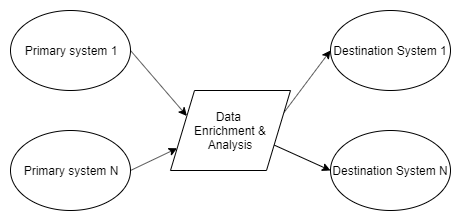
On a very high level, the following schema represents a single project setup:
The multi-project setup described in the above scenario is depicted in the following schema (the coloured parts represent the data catalog):
Because multi-project architecture is a usage pattern (enabled by a business contract for the organization), it is completely unconstrained. For a smaller company, having only the major sources (or destinations) in their own projects might be sufficient. A large corporation might need a deeper separation, so the following schema might be more appropriate: