Database Data Source Connectors
Data source connectors import and integrate data from external sources into the Keboola environment.
SQL Databases
Section titled “SQL Databases”Multiple connectors are available for SQL databases:
- Cloudera Impala
- Firebird
- IBM DB2
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- Redshift
- Snowflake
- Teradata
Several variants of connectors may exist for each database type, depending on the strategy used. In general, there are two types of connectors:
Query-Based Connectors
Section titled “Query-Based Connectors”These connectors work on a relational level, performing queries against the source database to synchronize data. This straightforward approach suits most use cases and supports Timestamp-based CDC replication.
All are configured similarly and offer an advanced mode.
Their basic configuration is also part of the Tutorial - Loading Data from Database.
Log-Based Connectors
Section titled “Log-Based Connectors”These connector perform log-based replication and may offer a different set of features and UI options depending on the database type. They are ideal for more advanced use cases requiring high performance and minimal load on the source DB system.
Typically, these connectors are useful in the following scenarios:
- Users require synchronization of every change to the source, including deletes.
- The source database does not contain any suitable timestamp column to enable incremental fetching and contains extremely large tables.
- The source cannot be queried directly to eliminate any additional load.
NoSQL Databases
Section titled “NoSQL Databases”Unlike the connectors for SQL databases, connectors for NoSQL databases require a different configuration (except the BigQuery data source connector for the BigQuery database, which is quite similar to SQL databases and also supports the advanced mode):
- MongoDB connector for the MongoDB database and the CosmosDB for MongoDB API.
- CosmosDB connector for the CosmosDB SQL API.
- Azure Storage Table connector for the Azure Table storage and the Cosmos DB Table API.
Connecting to Database
Section titled “Connecting to Database”The connection to your internal database must be well secured. If you or your system administrator want to avoid exposing your database server to the Internet, we highly recommend setting up an SSH tunnel for the connection.
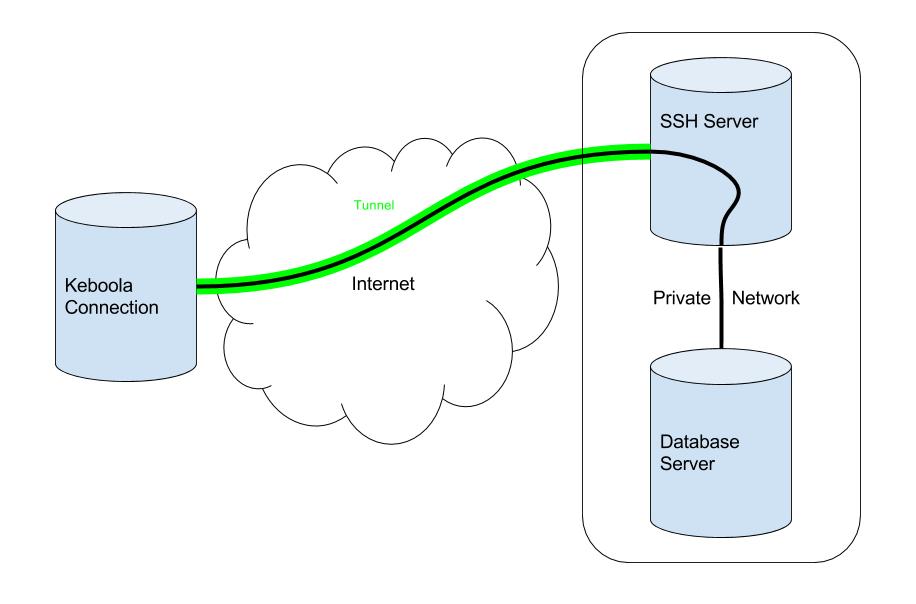
A Secure Shell (SSH) tunnel consists of an encrypted connection created through an SSH protocol connection. You can set up this tunnel to connect to your database server located in your private network that you do not want to be accessed directly from the Internet. The SSH connection is encrypted and uses a public-private key pair for user authorization.
Find detailed instructions for setting up an SSH tunnel in the developer documentation. While setting up an SSH tunnel requires some work, it is the most reliable and secure option for connecting to your database server.
Change Data Capture (CDC)
Section titled “Change Data Capture (CDC)”Change data capture (CDC) refers to the process of identifying and capturing changes made to data in a database and then delivering those changes to the destination system. In short, CDC identifies the rows in source tables that have changed since the last replication and propagates them to the Storage.
Different approaches CDC may exist. Keboola database connectors support a variety of these approaches, so you can choose the most suitable one.
- Timestamp-based: Using the last_updated timestamp or other incremental column, the database can be queried to retrieve only the latest changes each run.
- Trigger-based: DBAs may create a set of triggers that replicate change on each INSERT, UPDATE, DELETE. These tables can then be queried, and changes replicated in the destination.
- Log-based: Reading the database low-level proprietary transaction log directly to replicate the changes.
| CDC Type | Pros | Cons | Keboola Implementation |
|---|---|---|---|
| Timestamp-based | Low cost. Simple to use. | May increase the load on the database. Can only process soft-deletes, not DELETE statements. The source tables must have appropriate columns available. | Incremental Fetching |
| Trigger-based | Can capture DELETES. Customizable. | Executional overhead and higher load on the production. Implementation overhead. Events may need to be replicated in downstream logic. | Using standard DB data source connectors. |
| Log-based | No computational overhead on production. Can detect hard DELETEs. Fast | Higher costs. May be overkill for small use cases. | Binlog-type data source connectors like MySQL Binlog CDC. |
Incremental Fetching
Section titled “Incremental Fetching”Some database connectors support the feature Incremental Fetching. This is an implementation of the timestamp-based replication. Incremental fetching dramatically reduces the amount of data loaded
from the source database server if the nature of the database permits. It can be used when the source table contains an ordering (ordinal) column and no rows are deleted (or the deletions are unimportant).
There are two typical scenarios:
- A table to which rows are only added, and the rows have numeric and raising IDs.
- A table in which rows are added and modified contains a column with the last modification time.
To enable incremental fetching, you have to specify the ordering column. When incremental fetching is enabled, the rows in the table are extracted in the order determined by the ordering column. The last fetched value is recorded in the configuration state. Only new rows are fetched from the sourced database when the extraction runs again. To configure incremental fetching, go to table details:
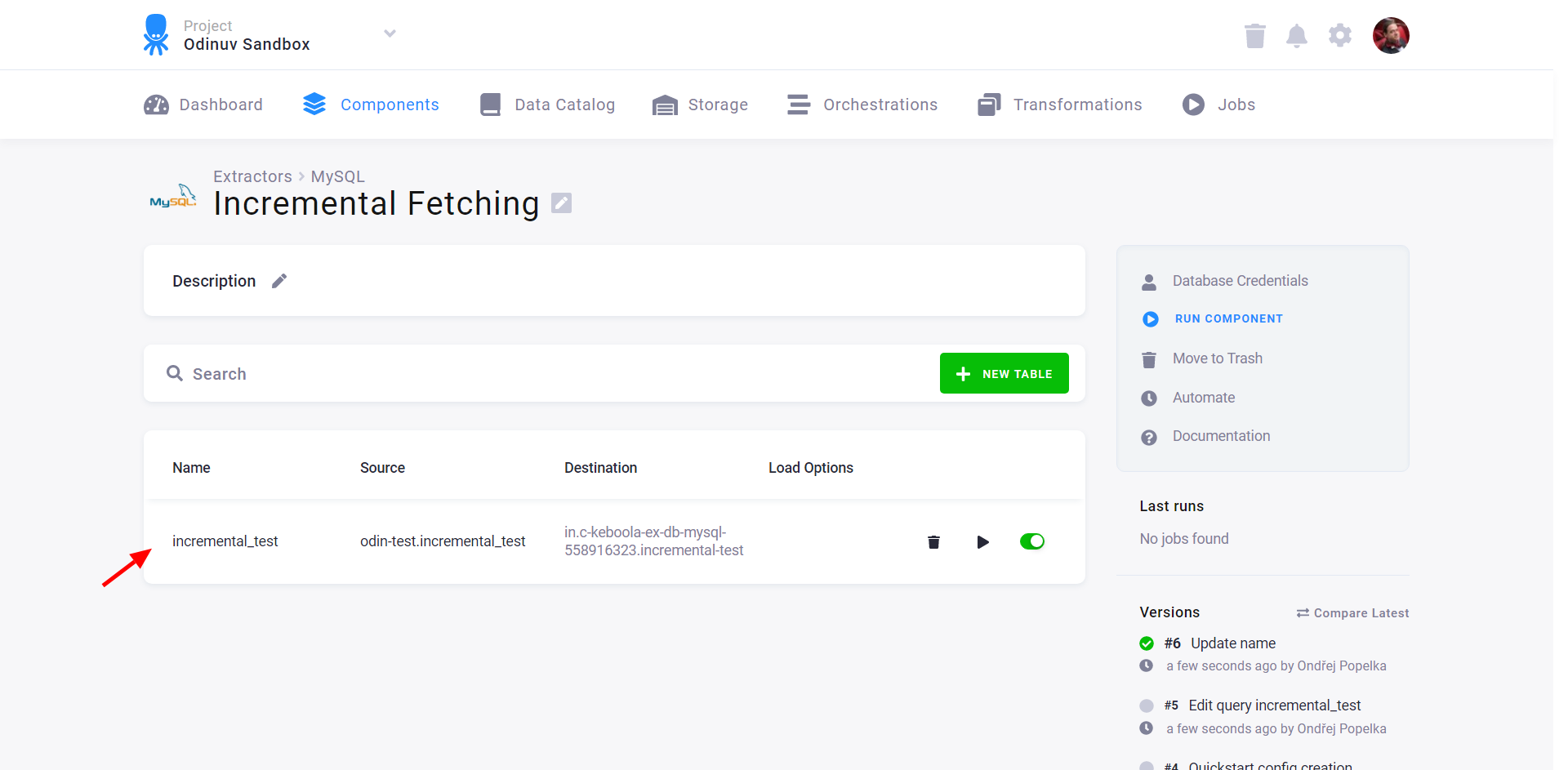
Then select the ordering column:
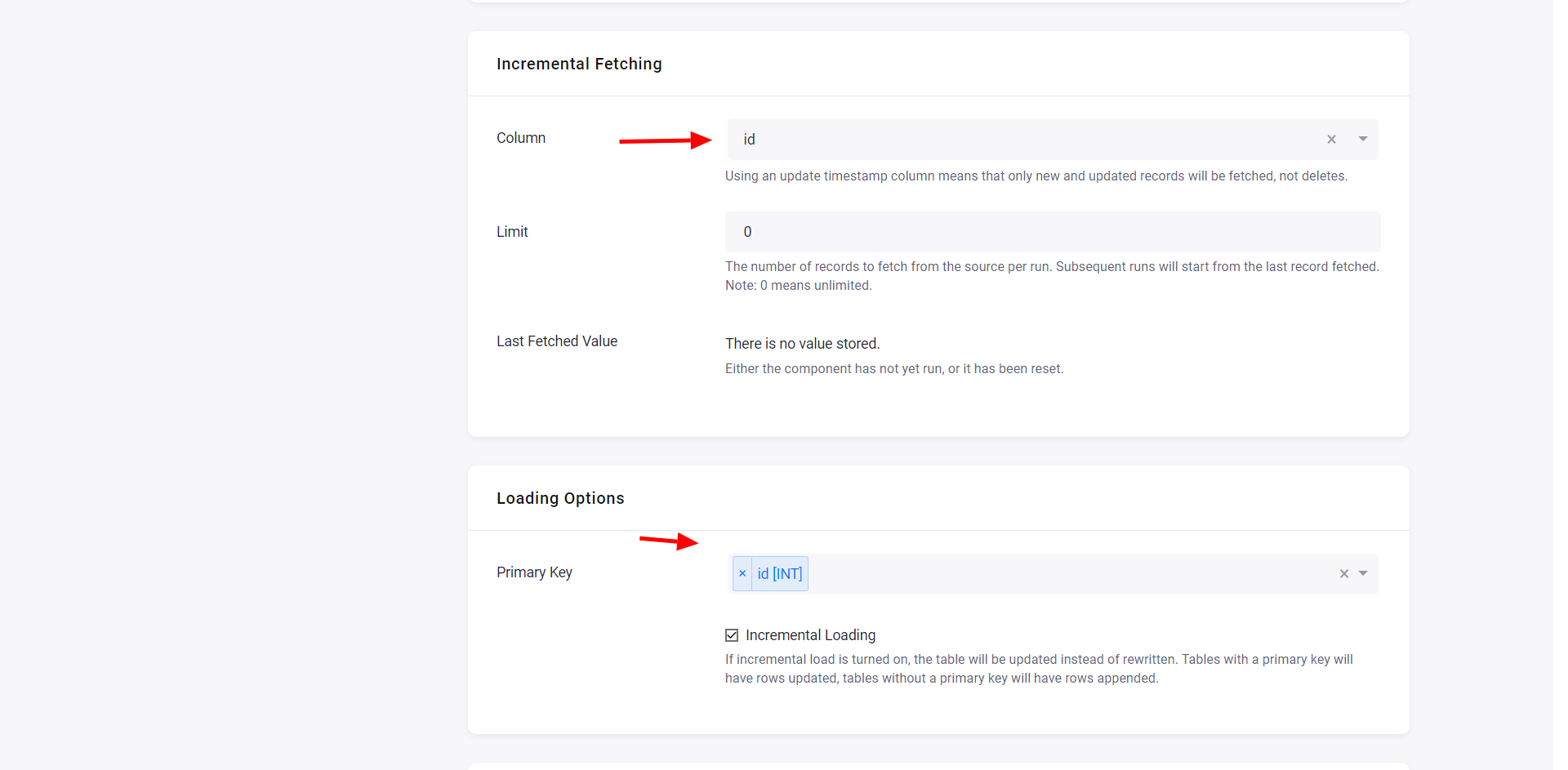
The last fetched value is displayed in the configuration:
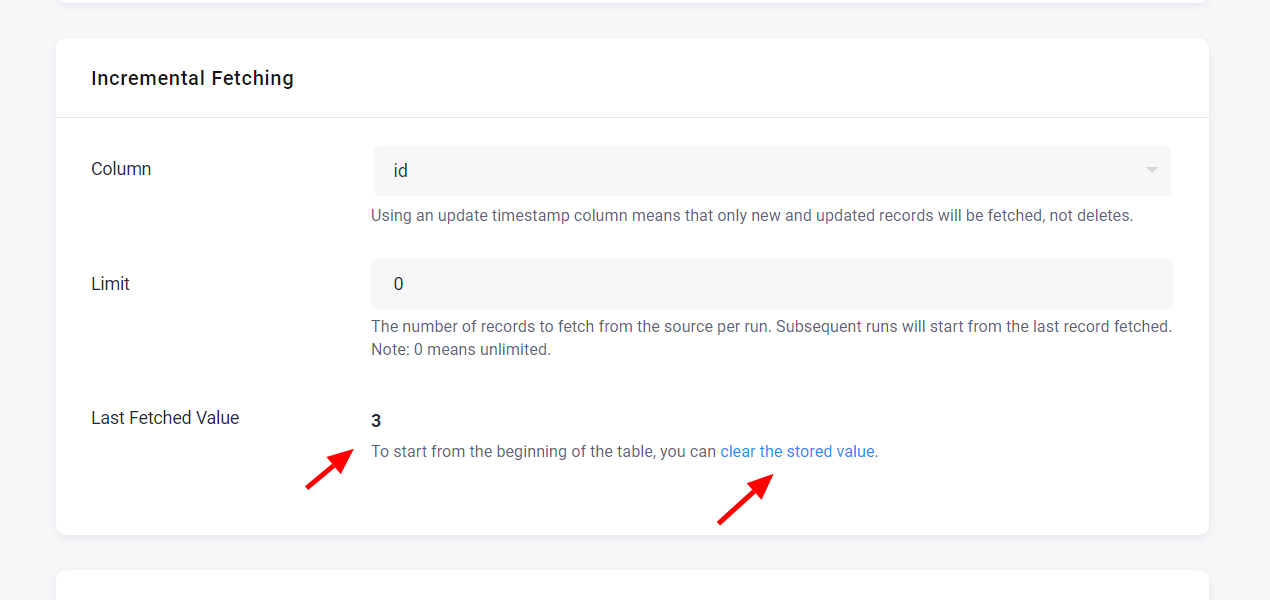
The rows are fetched from the source table, including the last fetched value. Therefore, it is ideal to set the ordering column as a primary key so you don’t receive duplicated rows in the Storage table. You can clear the stored value if you need to fetch the entire table.
This incremental fetching feature is related to incremental loading. While not required, it is recommended to turn on incremental loading when fetching data incrementally; otherwise, the table in Storage will contain only newly added rows. This may sound like a good idea when you want to process only the newly added rows. In that case, however, you should do so using incremental processing. The advantage of using incremental processing over having only newly added rows in a Storage table is that the table contains all loaded data, and it is not necessary to synchronize extraction and processing.
Log-Based Replication
Section titled “Log-Based Replication”Due to the differences in log replication implementation in different systems, our log-based connectors may differ in configuration options and behavior based on the source database.
Our log-based connectors are based on the widely used Open-Source project Debezium, providing a reliable and efficient way to replicate data from the source database.
In general, the log-based connectors function in this way:
- The frequency of updates depends on the user (e.g., every 5 minutes), hence running in micro-batches.
- The initial load is performed as full sync using chunked direct queries.
- Each consecutive load is performed from the database log incrementally.
- Load Types:
- Append modes (Incremental, Full) -> capture every change and append (or replace) to the destination table. The result table might need to be processed further to replicate the source.
- Deduplicated modes (Incremental, Full) -> deduplicate each batch (keep only the latest event) and upsert (or replace) to the destination. The result table is a replica of the source.
- Most of our connectors can handle Schema changes without enforcing full sync.
The currently supported log-based connectors: