Input and Output Mapping
To configure input and output mappings in the process of creating a transformation, go to our Getting Started tutorial.
When manipulating your data, there is no need to worry about accidentally modifying the wrong tables. Mapping separates the source data from your transformation script. It creates a secure staging area with data copied from specified tables and brings only specified tables and files back to Storage. While the concept of mapping is most important for transformations, it actually applies to every single component.
Two mapping types must be set up before running a transformation:
- Input Mapping --- This is a list of Storage tables used in your transformation.
If an input mapping does not fit well to your use case, then a read-only input mapping offers straightforward access to the data, and will drastically reduce the execution time.
This feature is useful in the following scenarios:
- Slow transformations where a clone is not used (input mapping)
- Complex flows that move data from a data source to the workspace where they are accessed by other apps
- Cases where updating data in Storage via output mapping causes multiple data movement operations
- Output Mapping --- This is a list of tables written into Storage after running the transformation. Tables not listed are neither modified nor permanently stored (i.e., they are temporary). They are deleted from the transformation staging area when the execution finishes.
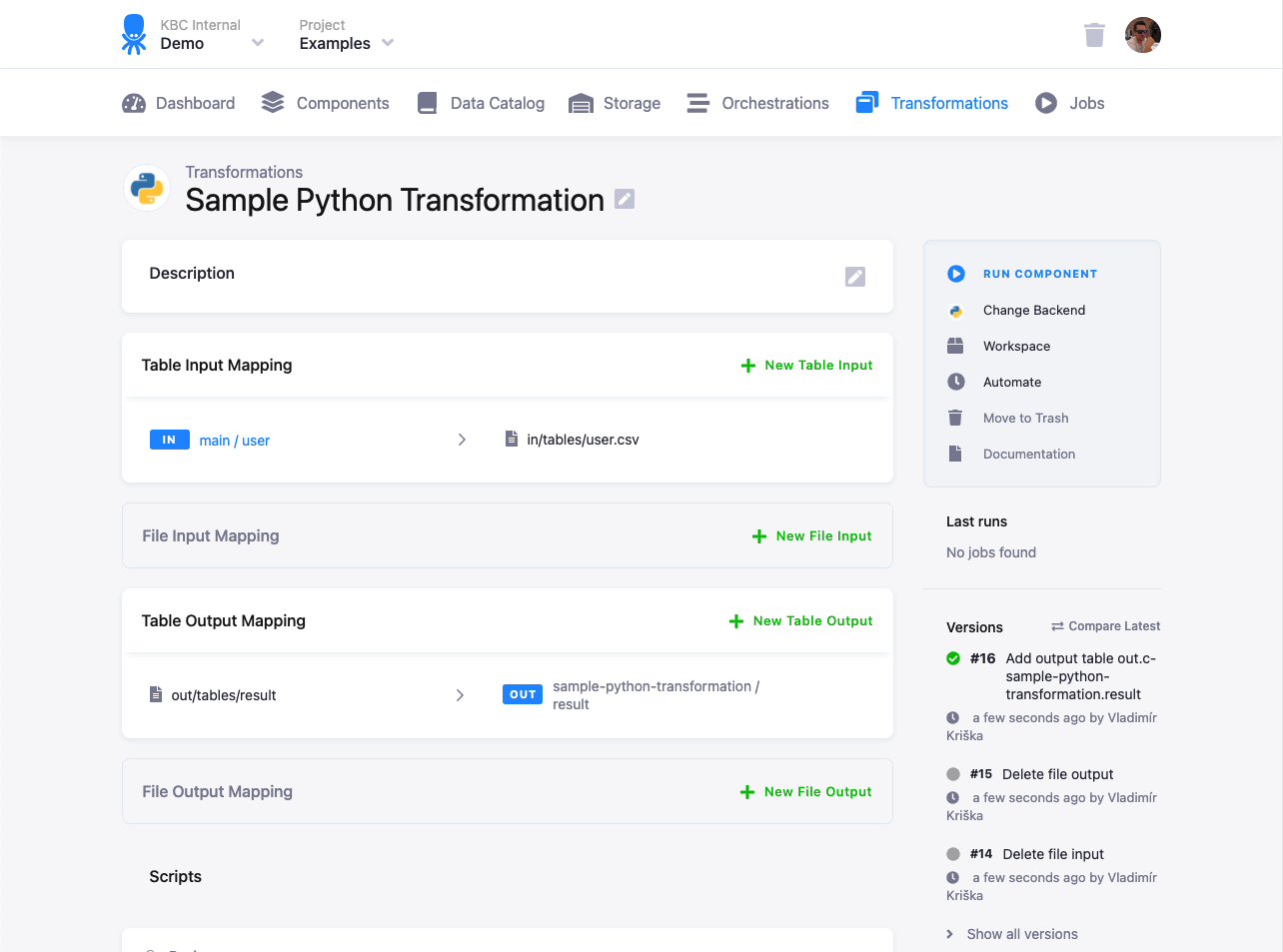
Table names referenced by mappings are automatically quoted by Keboola. This is especially important for Snowflake, which is case sensitive.
The concept of mapping helps to make the transformations repeatable and protect the project Storage. You can always rely on the following:
- Having an empty staging Storage (no need to clean up before transformations)
- Having an isolated staging Storage (no need to worry about interference with other transformations)
- Having a stateless transformation (no need to worry about having left-over variables and settings from something else)
- Resource cleanup (no need to worry about cleaning up temporary data after yourself)
- Resource conflict (no need to worry about naming data in the staging Storage)
While this makes some operations seemingly unnecessarily complicated, it ensures that transformations are repeatable and you can’t inadvertently overwrite data in the project Storage. For ad-hoc operations, we recommend you use workspaces. For bulk operations, consider taking advantage of variables and programmatic automation.
Input Mapping
Section titled “Input Mapping”Both Storage tables and Storage files can be used in the input mapping of a transformation. The common first choice is to use an input mapping with tables.
Table Input Mapping
Section titled “Table Input Mapping”Depending on the transformation backend, the table input mapping process can do the following:
- Database Staging: Copy the selected tables to tables in a newly created database schema. If you have not selected any tables and read-only input mappings are enabled, you can access them automatically in the workspace. In this case the tables are not copied.
- File Staging: Export the selected tables to CSV files and copy them to a designated staging Storage (not to be confused with a file mapping, as we’re still working with tables).
Depending on the transformation types, you can either build your transformations working with database tables or with CSV files. Furthermore, the CSV files can be placed locally with the transformation script or they can be placed on a remote storage such as Amazon S3 or Azure Blob Storage. The supported database type is Snowflake.
See an example of setting up an input mapping in our tutorial.
Options
Section titled “Options”- Source --- Select a table or a bucket in Storage as the source table for your transformation. If you select a bucket, it is the equivalent of selecting all tables currently present in the bucket. It does not automatically add future tables to the selection.
- File name / Table Name --- Enter the destination name of the mapping that is the Source table/file
name to be used inside the transformation. This is an arbitrary name you’d like to use as a reference for the table
inside the transformation script (it fills in automatically, but it can be changed). For File Staging, it is a good
idea to add the
.csvextension. For Database Staging, the table name is automatically quoted, which means you can use an arbitrary name. It also means that they may be case sensitive, for instance, if the destination is in Snowflake staging. - Columns --- Select specific columns if you do not want to import them all; this saves processing time for larger tables.
- Changed in last --- If you use incremental processing,
this comes in handy; import only rows changed or created within the selected time period.
The supported time dimensions are
minutes,hours, anddays. - Data filter --- Filter source rows to the rows that match this single-column multiple-values filter. When used together with Changed in last, the returned rows must match both conditions.
- Data types --- Configure data types.
If the terms source and destination look confusing, consult the image below. We always use them in a specific context. That means input mapping destination is the same file as the source for a transformation script.

Data types
Section titled “Data types”The data types option allows you to configure settings of data types for the destination table. Data types are applicable only for destinations in database staging. Select User defined to configure data types for individual columns. The types are pre-configured with data types stored in the table metadata. The Type, Length, and Nullable options define the destination table structure in the staging database.
The option Convert empty values to null adds additional processing which is particularly important for non-string columns.
All data in Storage tables are stored in string columns, and empty values (be it true NULL values, or empty strings) are stored
as empty strings. When converting such values back to, for example, INTEGER or TIMESTAMP, they have to be converted to true
SQL NULL values to be successfully inserted.
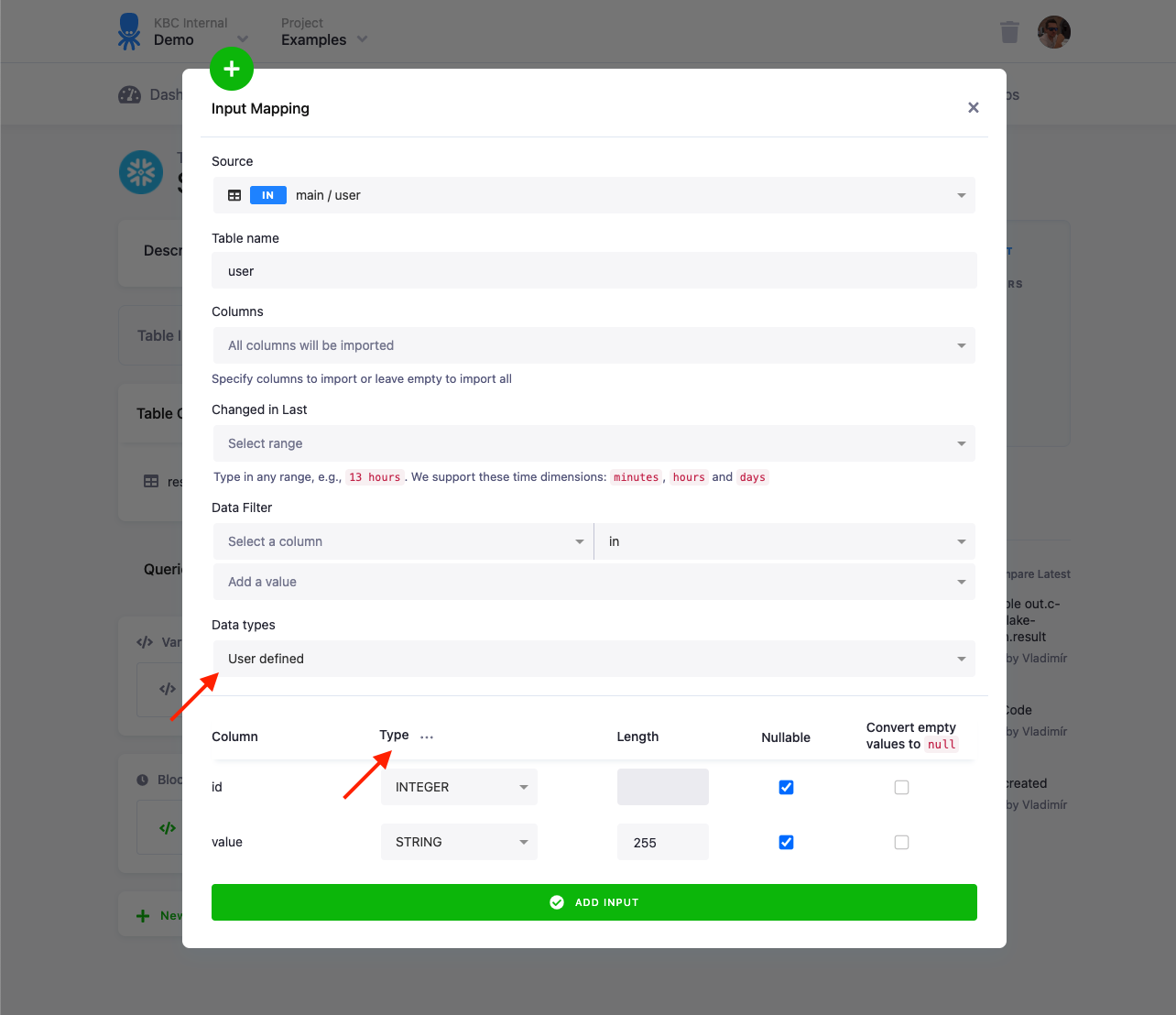
The pre-set data types are only suggestions, you can change them to your liking. You can also use the three dots menu to bulk set
the types. Beware, however, that if a column contains values not matching the type, the entire load (and transformation) will
fail. In such a case, it’s reasonable to revert to VARCHAR types — for example, by setting Data types to None.
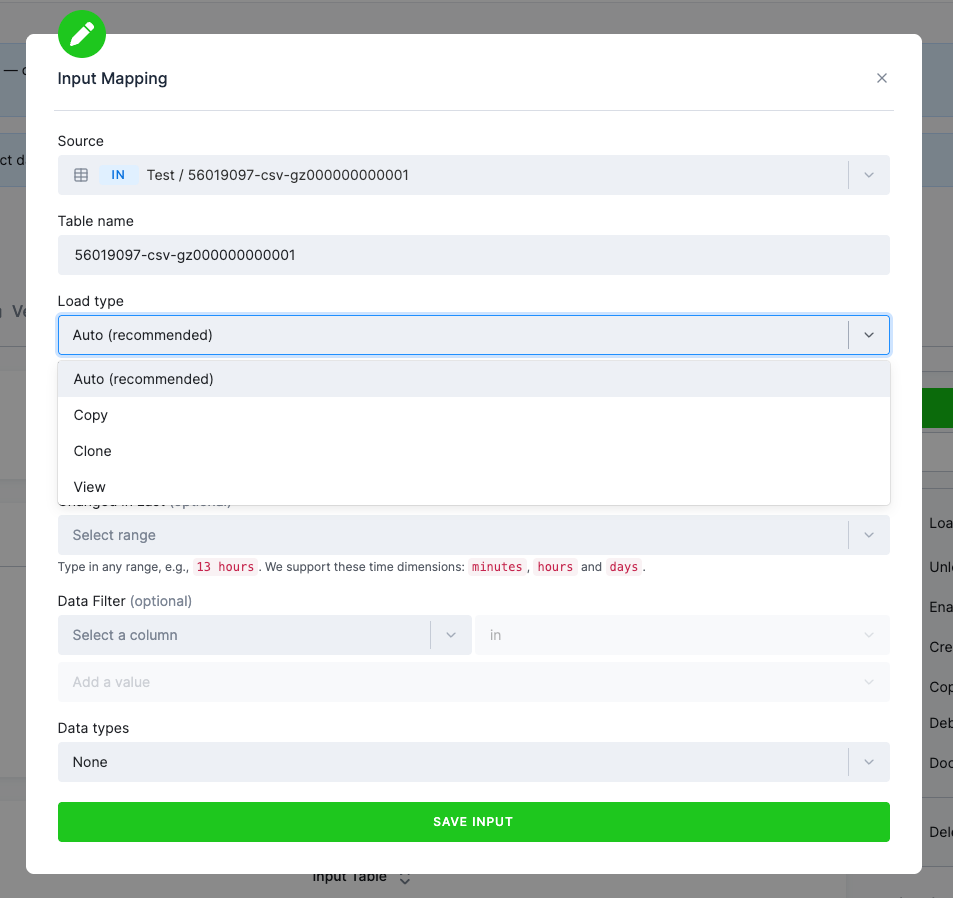
Loading type (Snowflake and BigQuery)
Section titled “Loading type (Snowflake and BigQuery)”When working with large tables, it may become important to understand how the tables are loaded into a staging
database. Keboola uses three loading strategies --- COPY, CLONE, and VIEW --- plus an AUTO mode (the default)
that picks the best available strategy for each table:
CLONE--- a highly optimized operation that loads an arbitrarily large table in near-constant time, because it physically moves no data.CLONEcan’t be combined with filters, data type configurations, or incremental loading. It is supported on Snowflake and BigQuery backends.COPY--- a full physical copy of the data into the staging database. Always available; used when neitherCLONEnorVIEWcan be applied (for example, when filters or data types are configured).VIEW--- loads the table as a read-only view instead of copying any data; the data is read live from its source location. Used for linked, external, and alias tables.
You can set the strategy per table with the Load type option in the input mapping (Auto, Copy, Clone, or View):
How AUTO decides. AUTO prefers CLONE whenever the table can be cloned. On BigQuery, tables that can’t be
cloned --- linked, external, and alias tables --- are loaded as a read-only VIEW. When filters, data type
configurations, or incremental loading are used (which neither CLONE nor VIEW supports), AUTO falls back to COPY.
If you explicitly request CLONE for a table that can’t be cloned (for example, a linked-bucket table on
BigQuery, or any table with incompatible options such as incremental), the request fails.
In the input mapping, tables that will be loaded as a read-only view are marked with a view icon:

This might present a dilemma when loading huge tables. A logical approach when trying to speed up loading a large table would
be setting data types and adding filters to copy only the necessary ones. You might find out, however, that at some point, it’s
actually faster to remove the filters and data types, take advantage of the CLONE loading type, and apply the filters
inside the transformation. Also, when you need more complex filters (filtering by multiple columns or ranges), it’s best to
remove the filter completely from the input mapping, take advantage of the clone loading, and do the filtering inside of the
transformation.
You can verify the table loading type in the events --- copy table:

Clone table:

The CLONE mapping will execute almost instantly for a table of any size (typically under 10 seconds)
as it physically does not move any data.
On the other hand, you can use a read-only input mapping which makes all the buckets and tables available with read access, so there is no need to clone the tables into a new schema. You can simply read from these buckets and tables in the transformation. This function is automatically enabled in transformations.
Read-only input mapping
Section titled “Read-only input mapping”Note: You must be using new transformations to see this feature.
When read-only input mappings are enabled, you automatically have read access to all buckets and tables in the project (this also applies to linked buckets). Alias tables are materialized as database VIEWs and are fully accessible via read-only input mappings — including filtered aliases and aliases from linked buckets.
There is no need to set anything for a read-only input mapping in transformations, all tables in Storage are automatically accessible in the transformation. This also applies to linked buckets. Note that buckets and tables belong to another project, so you need to access the tables using the fully qualified identifier, including the database and schema, in the source project.
Users can enable or disable read-only access to the storage in user workspaces and the Snowflake data destination. If read-only access is disabled, users must define an input mapping as they typically do.
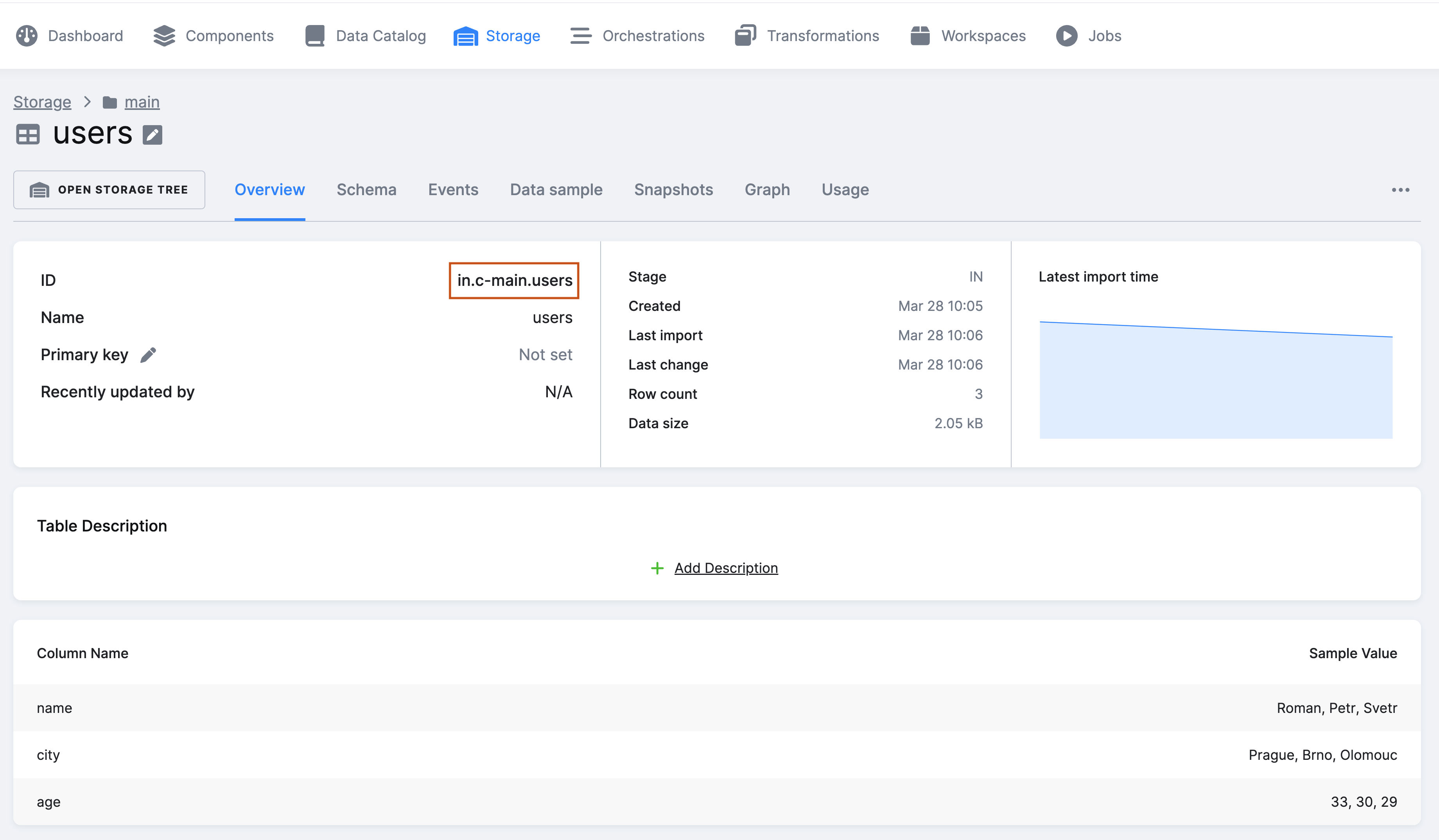
You have read access to all the tables in your project’s Storage directly on the underlying backend. However, this means you need to use the internal ID of a bucket (in.c-main instead of main as you see in the UI).
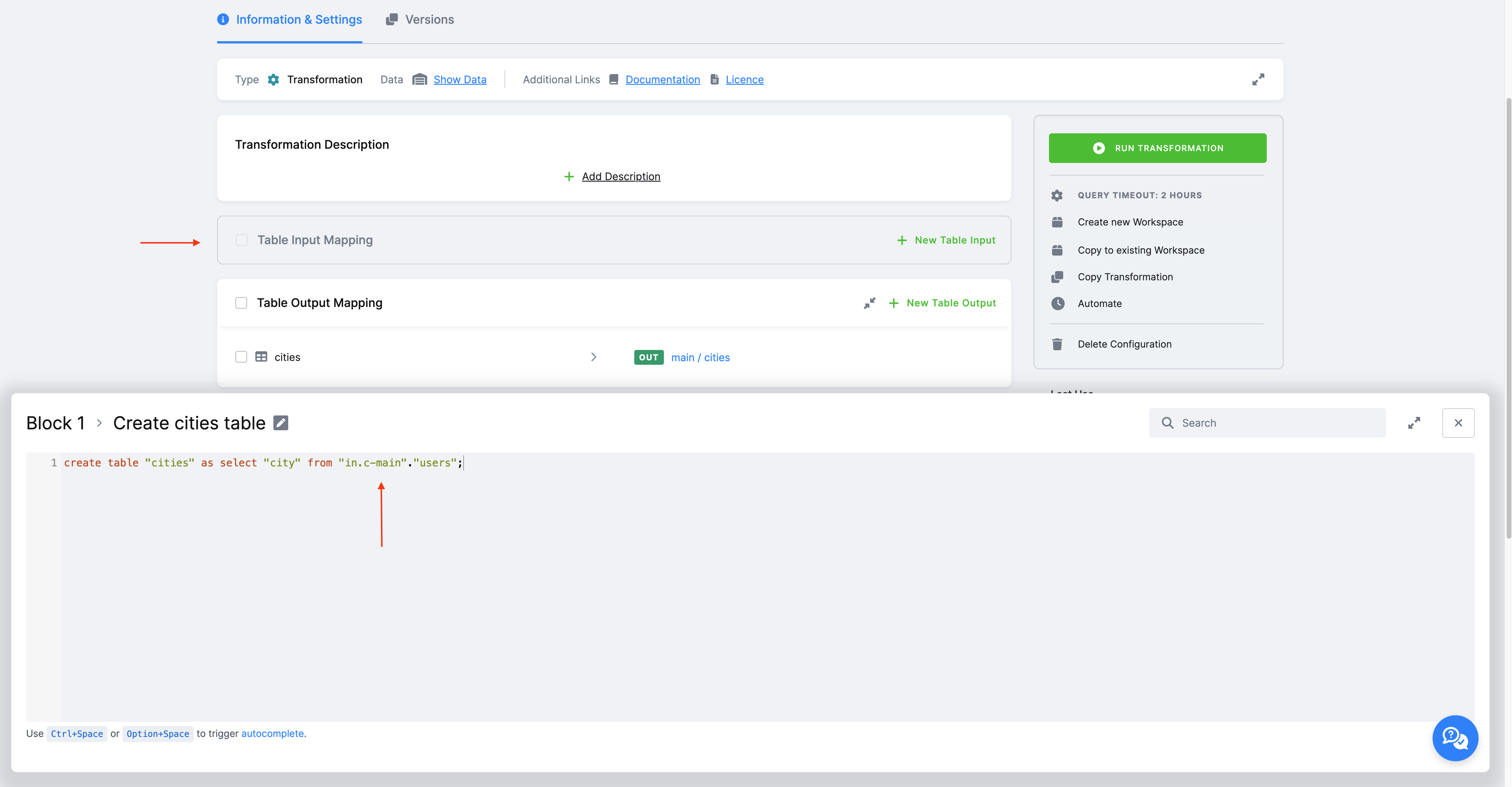
In the transformation code (Snowflake), we select from the table “in.c-main”.“users” and create a new table: create table "cities" as select "city" from "in.c-main"."users";.
Depending on the backend, the SQL format is different. More info regarding access to individual tables depending on the backend can be found in the documentation of those individual backends ( Snowflake, BigQuery ).
As you can see, a read-only input mapping allows you to read a table created in Storage directly in the transformation.
_timestamp system column
Section titled “_timestamp system column”A cloned table is an exact copy of the source table, including the _timestamp system column.
This column is used internally by Keboola for comparison with the value of the Changed in last filter.
The column type differs by backend: TIMESTAMP_NTZ(9) on Snowflake and TIMESTAMP on BigQuery.
The value contains the last change of the row.
You can use this column to set up incremental processing,
i.e., to replace the role of the Changed in Last filter in the input mapping (which you can’t use with a clone mapping).
Important: The _timestamp column cannot be imported back to Storage.
When you attempt to do so, you’ll get the following error:
Failed to process output mapping: Failed to load table "out.c-test.opportunity":Invalid columns: _timestamp: Only alphanumeric characters and underscores are allowed in the column name.Underscore is not allowed on the beginning.If you are not using the _timestamp column in your transformation, you can either use the dropTimestampColumn option
in the input mapping to exclude it automatically, or drop it manually:
In Snowflake:
`ALTER TABLE "my-table" DROP COLUMN "_timestamp";`In BigQuery:
`ALTER TABLE my-table DROP COLUMN _timestamp;`The _timestamp column is not present on tables loaded using the copy method.
File Input Mapping
Section titled “File Input Mapping”The file input mapping process exports the selected files from file Storage and copies them to the staging Storage. Depending on the transformation, this can be either a drive local to the transformation or a remote storage such as Amazon S3 or Azure Blob Storage. A file input mapping cannot operate with storage tables, but it comes in handy for processing files that cannot be converted to tables (binary files, malformed files, etc.) or, for example, to work with pre-trained models that you can use in a transformation.
Options
Section titled “Options”- Tags — tags used to select files.
- Changed Since — the time range for selecting files. Either a static range (e.g.
30 minutes) or Since last successful run for incremental processing (see below). With a static range, a file must satisfy both the tags and the range to be selected. - Query (deprecated, do not use) — legacy option for a customized Elastic query.
- Processed Tags (deprecated, do not use) — legacy option that assigned tags to input files after the transformation finished, used to process files incrementally.
Incremental file processing
Section titled “Incremental file processing”Incremental processing is active when Changed Since is set to Since last successful run. In this mode, the configuration stores a reference to the newest file matching the specified tags. The next run continues with files newer than that reference, so the transformation is automatically fed only the files that have not yet been processed.
To manipulate the state — for example, to run a backfill — use Debug Mode → Update State to reset it.
Output Mapping
Section titled “Output Mapping”An output mapping takes results (tables and files) from your transformation and stores them back in Storage.
It can create, overwrite, and append any table.
These tables are typically derived from the tables/files in the input mapping. In SQL transformations,
you can use any CREATE TABLE, CREATE VIEW, INSERT, UPDATE or DELETE queries to create the desired result.
The result of output mapping can be both Storage tables and Storage files. The common first choice is to use the table output mapping. The rule is that any tables or files not specified in the output mapping are considered temporary and are deleted when the transformation job ends. You can use this to your advantage and simplify the transformation script implementation (no need to worry about cleanup or intermediary steps).
Keep in mind that every table or file specified in the output mapping must be physically present in the staging area. A missing source table for the output mapping is an error. This is important when the results of a transformation are empty --- you have to ensure that an empty table or an empty file (with a header or a manifest) is created.
Table Output Mapping
Section titled “Table Output Mapping”Depending on the transformation backend, the table output mapping process can do the following:
- In case of Database Staging --- copy the specified tables from the staging database into the project Storage tables.
- In case of File Staging --- import the specified CSV files into project Storage tables.
The supported staging database type is Snowflake. The supported staging for CSV files is a storage local to the transformation.
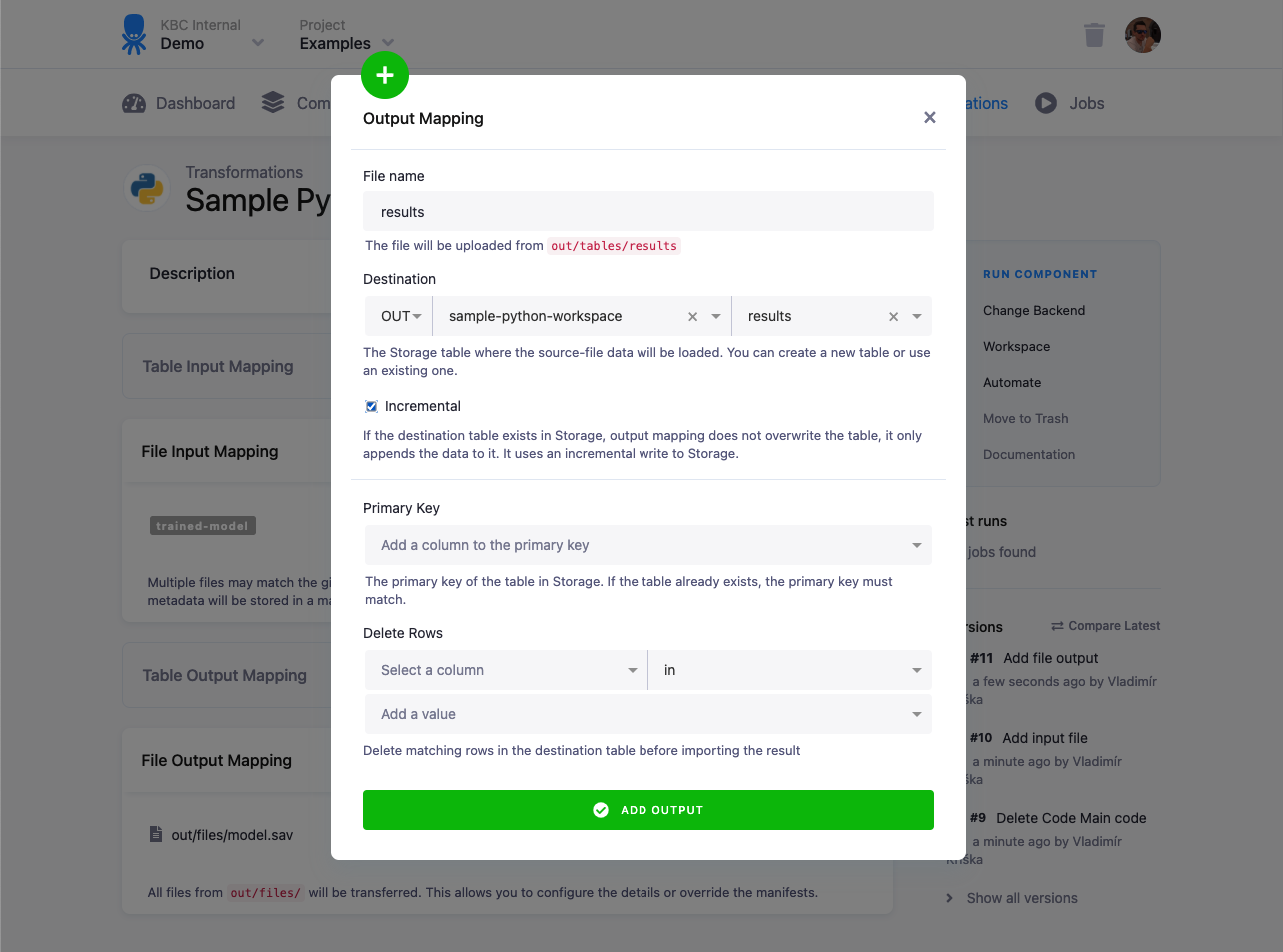
See an example of setting up an output mapping in our tutorial.
Options
Section titled “Options”-
Table --- Enter the name of the table that should be created in the transformation.
-
Destination --- Select or type in the name of the Storage output table that will contain the results of your transformation (i.e., contents of the Output Mapping source table).
- If this table does not exist yet, it will be created once the transformation runs.
- If this table already exists in Storage, the source table must match the structure of the destination table (all columns must be present, new columns will be added automatically).
-
Incremental --- Check this option to make sure that in case the Destination table already exists, it is not overwritten, but resulting data is appended to it. However, any existing row having the same primary key as a new row will be replaced. See the description of incremental loading for a detailed explanation and examples.
-
Primary key --- The primary key of the destination table; if the table already exists, the primary key must match. Feel free to use a multi-column primary key.
-
Deduplication Strategy --- This allows to switch in Snowflake transformations from the default load Upsert to Insert. Upsert option uses deduplication based on primary keys and ensures data quality. By switching to Insert, the load performs faster but skips deduplication and type casting - meaning you are responsible for uniqueness and correct data types. As this option is for high data maturity users, you can ask our support to enable this for your project as Deduplication Strategy is under feature flag.
-
Delete rows --- When Incremental loading is enabled, you can delete specific rows from the destination table before importing new data into the Storage. This gives you precise control over incremental updates. There are 2 options you can use:
- Delete rows from values - this option lets you manually specify values that identify rows to be removed from your destination table. This is particularly useful when the rows to delete are consistent, predictable, or rarely changing.
- Delete rows from transformation table - this option enables you to define deletion criteria using live data generated in your transformation. This method provides flexibility for more complex, data-driven scenarios, such as removing obsolete records based on recent transactions or other dynamic conditions. This option needs to be enabled by navigating to Project Settings → Features → Delete rows from transformation table. Please note that this option is available in the production environment only and is not supported in development branches (e.g. for testing or configuration changes in a development branch, the option will not be applied).
-
How the Delete Rows feature Works
Deletion is performed using SQL
DELETEstatements:- Each deletion query you configure creates a separate SQL
DELETEstatement:
DELETE FROM table_name WHERE condition;- Multiple filters within a single query combine into a single
DELETEwithANDconditions:
DELETE FROM table_name WHERE condition1 AND condition2 AND ...;- Multiple queries result in separate
DELETEstatements, functioning as logicalOR:
DELETE FROM table_name WHERE condition1;DELETE FROM table_name WHERE condition2;In this scenario, rows matching any of the specified conditions across the queries will be deleted.
- Each deletion query you configure creates a separate SQL
Note: This process enables advanced row-level deletion logic, suitable for dynamic datasets where conditions may change per run.
File Output Mapping
Section titled “File Output Mapping”A file output mapping is used to store files produced by the transformation as Storage files. If you want to store CSV files as Storage tables, use table output mapping.
A file output mapping can be useful when your transformation produces, for example, trained models that are to be used in another transformation.
Only the files stored directly in the out/files/ directory can be mapped, subdirectories are not supported
(out/files/file.txt will work, out/files/subdir/file.txt won’t).
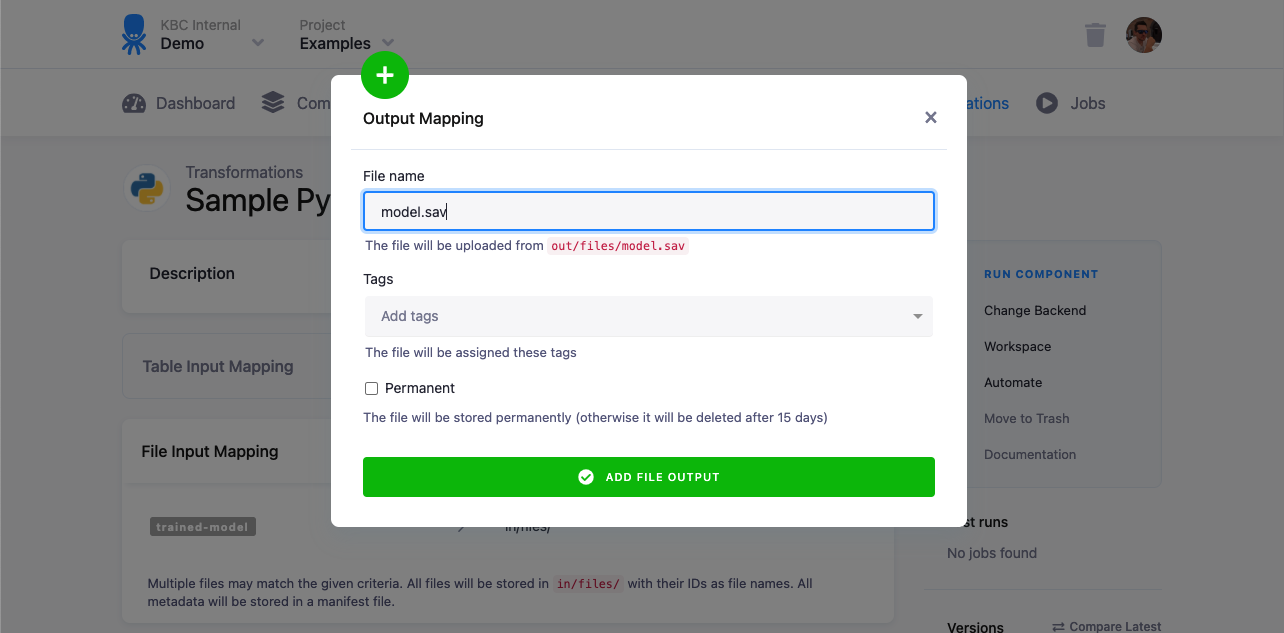
Options
Section titled “Options”- Source --- Name of the source file for mapping
- Tag --- Tags which will be applied to the target file uploaded in Storage
- Permanent - This option makes the file stay in the file Storage, until you delete it manually. If unchecked, the target file will be deleted after 15 days.
Direct Mode Output Mapping
Section titled “Direct Mode Output Mapping”Direct Mode Output Mapping lets your transformation write directly to Storage tables instead of going through
the standard copy-based output mapping process. With Direct Mode output mapping enabled, the transformation
user receives write privileges on specific Storage tables. Any INSERT, UPDATE, DELETE,
or TRUNCATE you run in your transformation SQL can be applied immediately to the destination table --- there is no
separate import step.
This feature is available as a private beta and must be enabled by Keboola Support.
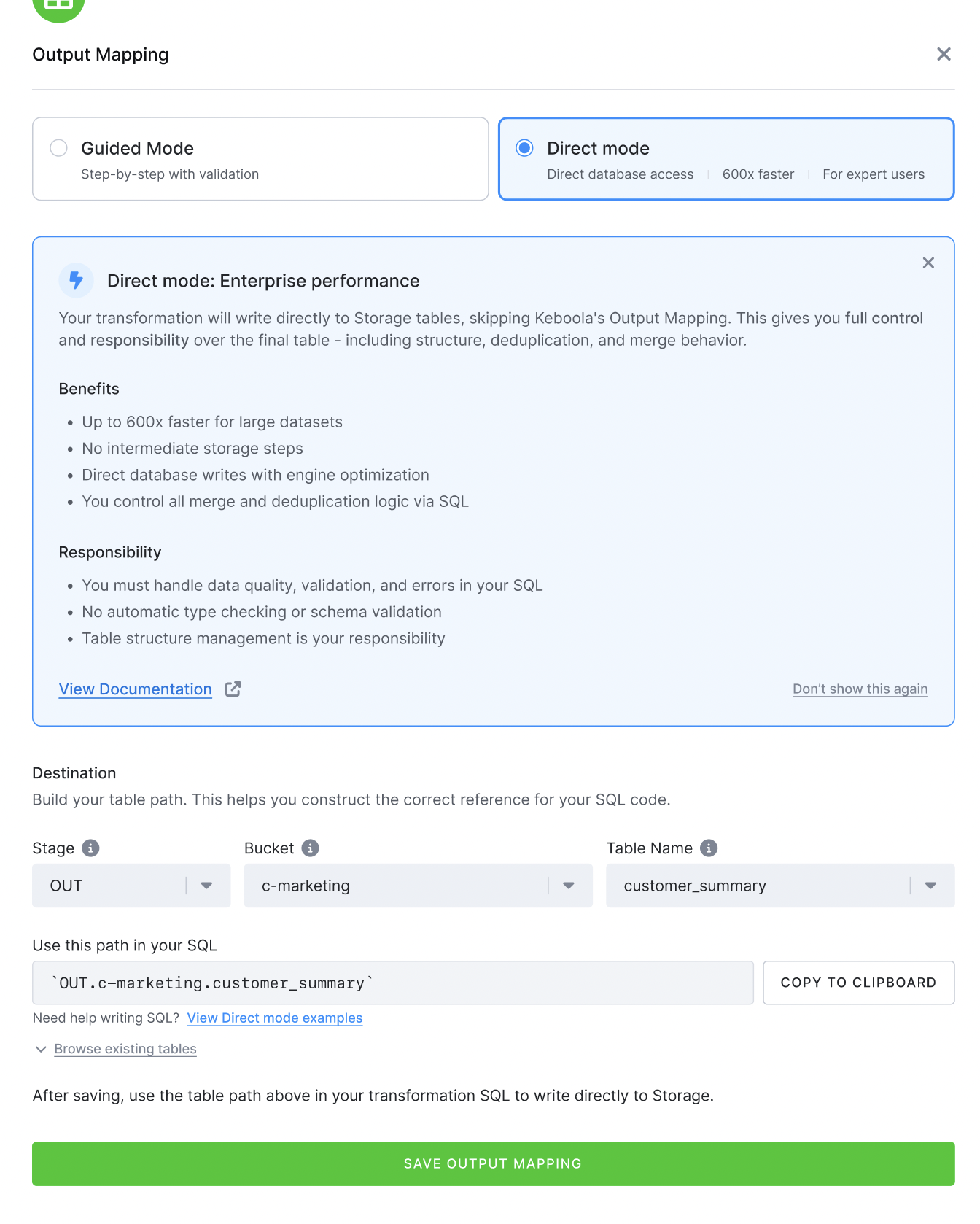
When to Use Direct Mode Output Mapping
Section titled “When to Use Direct Mode Output Mapping”Direct Mode output mapping is designed for advanced users with high data maturity who are comfortable writing production-quality SQL and managing data consistency themselves. Typical use cases include:
- Large incremental loads --- Standard output mapping on a 150 GB table with a single-row append can take over an hour due to deduplication and copy overhead. Direct Mode output mapping reduces this to seconds.
- Minimal overhead workflows --- When the standard mapping pipeline (copy to staging, deduplicate, import) creates unnecessary overhead for your workload.
Performance comparison (incremental load --- 1 row added to a 150 GB table):
| Method | Approximate Time |
|---|---|
| Standard output mapping (Upsert) | ~160 min |
| Simplified output mapping (Insert) | ~55 min |
| Direct Mode output mapping | ~11 seconds |
Supported Backends
Section titled “Supported Backends”Direct Mode output mapping is available for any component that uses a Snowflake or BigQuery workspace, including transformations, data apps, and workspaces --- both standalone Snowflake/BigQuery workspaces and workspaces opened in the SQL Editor.
How It Works
Section titled “How It Works”When a component with Direct Mode output mapping runs:
- The workspace role/service account receives write privileges on the specified Storage tables.
- Your transformation SQL operates directly on Storage tables using their read-only storage paths
(e.g.,
"KBC_USE4_33"."in.c-raw-data"."my-table"). - After the transformation finishes, Keboola runs a refresh job that updates table metadata, row counts, and statistics. No data is copied --- the changes are already in place.
In a workspace, there is no job to wait for: the write privileges are granted as soon as you save the Direct Mode output mapping, so you can write to the Storage table from your very next query. Removing the mapping revokes the privileges again.
The workspace receives these privileges on each granted table:
SELECT,INSERT,UPDATE,DELETE,TRUNCATE(Snowflake)bigquery.tables.getData,bigquery.tables.updateData,bigquery.tables.get(BigQuery)
The workspace cannot:
- Create new tables in the bucket
- Drop or alter existing tables
- Write to tables not listed in the output mapping
Configuration
Section titled “Configuration”In Snowflake and BigQuery transformations and workspaces, add an output mapping and switch the mode from Guided Mode to Direct Mode. Pick an existing Storage table as the destination; the dialog then shows the full table path to copy into your SQL.
The mode cannot be switched on an existing mapping --- delete the mapping and create a new one instead.
Under the hood, Direct Mode is the unload_strategy field on the output table in the configuration JSON:
{ "storage": { "output": { "tables": [ { "destination": "out.c-my-bucket.my_table", "unload_strategy": "direct-grant" } ] } }}The unload_strategy field accepts two values:
direct-grant--- Write directly to the Storage table (Direct Mode output mapping).copy--- Standard output mapping (default when the field is omitted).
You can mix both strategies in a single transformation --- some tables can use Direct Mode output mapping while others use the standard copy strategy.
Workspaces
Section titled “Workspaces”In a workspace, Direct Mode output mapping replaces the Unload Data round trip --- you write to the Storage table directly from the workspace instead of loading data into Storage afterwards.
In a standalone Snowflake or BigQuery workspace, open the Output Mapping section in the workspace detail, add an output, and select Direct Mode.
In the SQL Editor, you can also create the destination table on the fly:
- In the Working Tables section, click the three dots next to a working table and select Create writable table.
- Set the destination bucket and table name, adjust the column definitions and the primary key.
- Click CREATE WRITABLE TABLE.
Keboola creates the Storage table (creating the bucket first if it does not exist yet) and registers it as a Direct Mode output mapping. The source working table itself is not modified or copied --- only its column structure is used as the template for the new Storage table.
The new table appears in the Writable tables section of the Storage Explorer with the DG badge, and the workspace can write to it right away. Use the three-dots menu there to remove the mapping (and with it the workspace’s write access).
Good Practices
Section titled “Good Practices”Write idempotent SQL. Because there is no automatic rollback on failure, your SQL should be safe
to re-run. Use patterns like MERGE or DELETE + INSERT within a transaction:
BEGIN;DELETE FROM "in.c-my-bucket"."sales" WHERE date = CURRENT_DATE();INSERT INTO "in.c-my-bucket"."sales" SELECT * FROM "my_staging_table" WHERE date = CURRENT_DATE();COMMIT;Handle deduplication yourself. Use MERGE statements or explicit DELETE before INSERT
to avoid duplicate rows:
MERGE INTO "in.c-my-bucket"."customers" AS targetUSING "my_staging_table" AS sourceON target."id" = source."id"WHEN MATCHED THEN UPDATE SET target."name" = source."name", target."email" = source."email"WHEN NOT MATCHED THEN INSERT ("id", "name", "email") VALUES (source."id", source."name", source."email");Test in a non-production environment first. Direct Mode output mapping writes affect data immediately. Validate your transformation logic thoroughly before pointing it at production tables.
Use the read-only storage path for table references. In your SQL, reference tables by their
full Storage path (e.g., "SCHEMA"."in.c-bucket"."table"), not by workspace-local names.
Bad Practices
Section titled “Bad Practices”Do not rely on automatic deduplication. Unlike standard output mapping, Keboola does not
deduplicate data based on primary keys. Primary keys on Snowflake and BigQuery are not enforced by the
backend, so a primary key defined in Storage will not prevent duplicates on direct writes.
Running a plain INSERT repeatedly will create duplicate rows:
-- BAD: This will create duplicates on every runINSERT INTO "in.c-my-bucket"."customers" SELECT * FROM "my_staging_table";Do not assume type checking. Keboola does not verify that column data types in your SQL match the Storage table metadata. Mismatched types may cause errors or silent data inconsistencies.
Do not use DDL statements. You cannot CREATE TABLE, DROP TABLE, ALTER TABLE, or
SWAP TABLE on Storage tables through Direct Mode output mapping. Schema changes must be done through
Storage.
Do not use Direct Mode output mapping in development branches for production data. Development branches currently share the same Snowflake schema as production. Writing via Direct Mode output mapping in a dev branch will modify production data. This limitation is being addressed in a future release.
Limitations
Section titled “Limitations”- No automatic deduplication --- Primary keys on Snowflake and BigQuery are not enforced by the backend, so they will not prevent duplicates on direct writes. You must handle deduplication in your SQL.
- No type checking or casting --- Column types are not validated against Storage metadata.
- No schema changes --- You cannot alter table structure (add/remove/rename columns). Use Storage for schema modifications.
- No automatic rollback --- If a transformation fails mid-execution, the table may be left in a partially written state. Wrap related operations in transactions to mitigate this.
- Limited auditability --- Only an import event is created on success, compared to the more detailed event trail of standard output mapping.
- Development branch isolation not supported --- Dev branch writes affect production data on Snowflake. Use caution when testing.
- Read-only, external, and linked buckets are not supported --- Direct Mode output mapping cannot write to buckets that are read-only, external schemas, or linked from another project.