Azure Datalake Gen 2
This data source connector loads a single or multiple CSV files from a filesystem in Azure Datalake Gen2 and stores them in tables in Keboola Storage.
After creating a new configuration, select the files you want to extract from Azure Datalake Gen 2 and determine how you save them to Keboola Storage.
Configuration
Section titled “Configuration”Create a new configuration of the Azure Datalake Gen 2 connector.
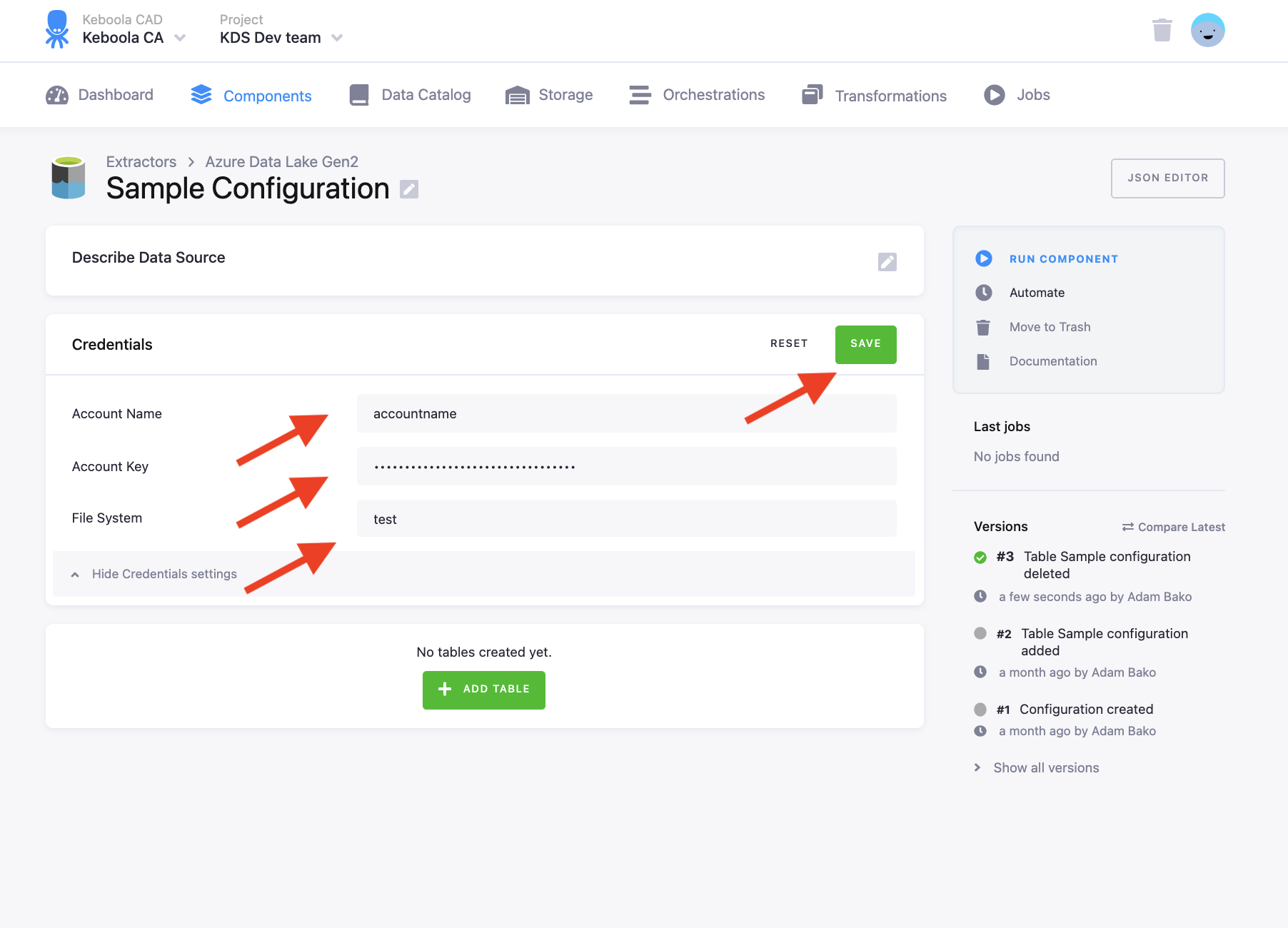
In order to access the files in Azure Datalake Gen2, you need to prepare an account name, account key, and file system.
Authentication
Section titled “Authentication”Fill in the Account name, key and file system you wish to retrieve data from.
Add Tables
Section titled “Add Tables”To create a new table, click the New Table button and assign it a name. It will be used to create the destination table name in Storage and can be modified.
Configured tables are stored as configuration rows. Each table has different settings (key, load type, etc.) but they all share the same credentials.
Source
Section titled “Source”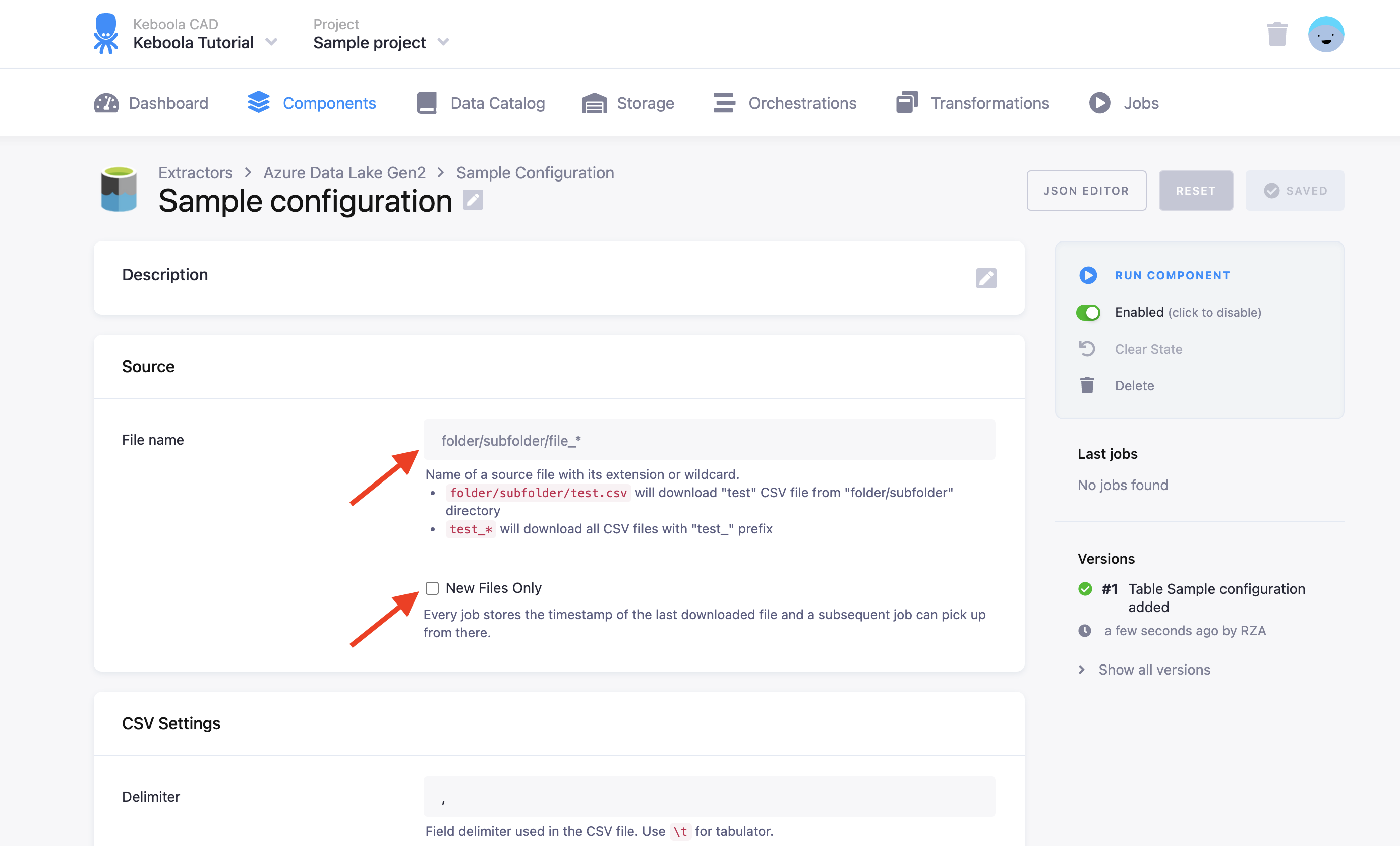
For each table you have to specify the folder in the Azure Datalake Gen2 and a Search Key. The Search Key can be a path to a single file or a prefix to multiple files (omit the wildcard character and use the Wildcard checkbox instead).
The additional source settings section allows you to set up the following:
- New Files Only: The connector will keep track of the downloaded files and will continue with the unprocessed files on the next run. To reset the state which keeps track of the progress and enables to continue with new files, use the Reset State button or uncheck the New Files Only option and run the connector again.
- Wildcard: Search Key is used as a prefix, and all available files matching the prefix will be downloaded.
- Subfolders: Available only with Wildcard turned on. The connector will also process all subfolders.
CSV Settings
Section titled “CSV Settings”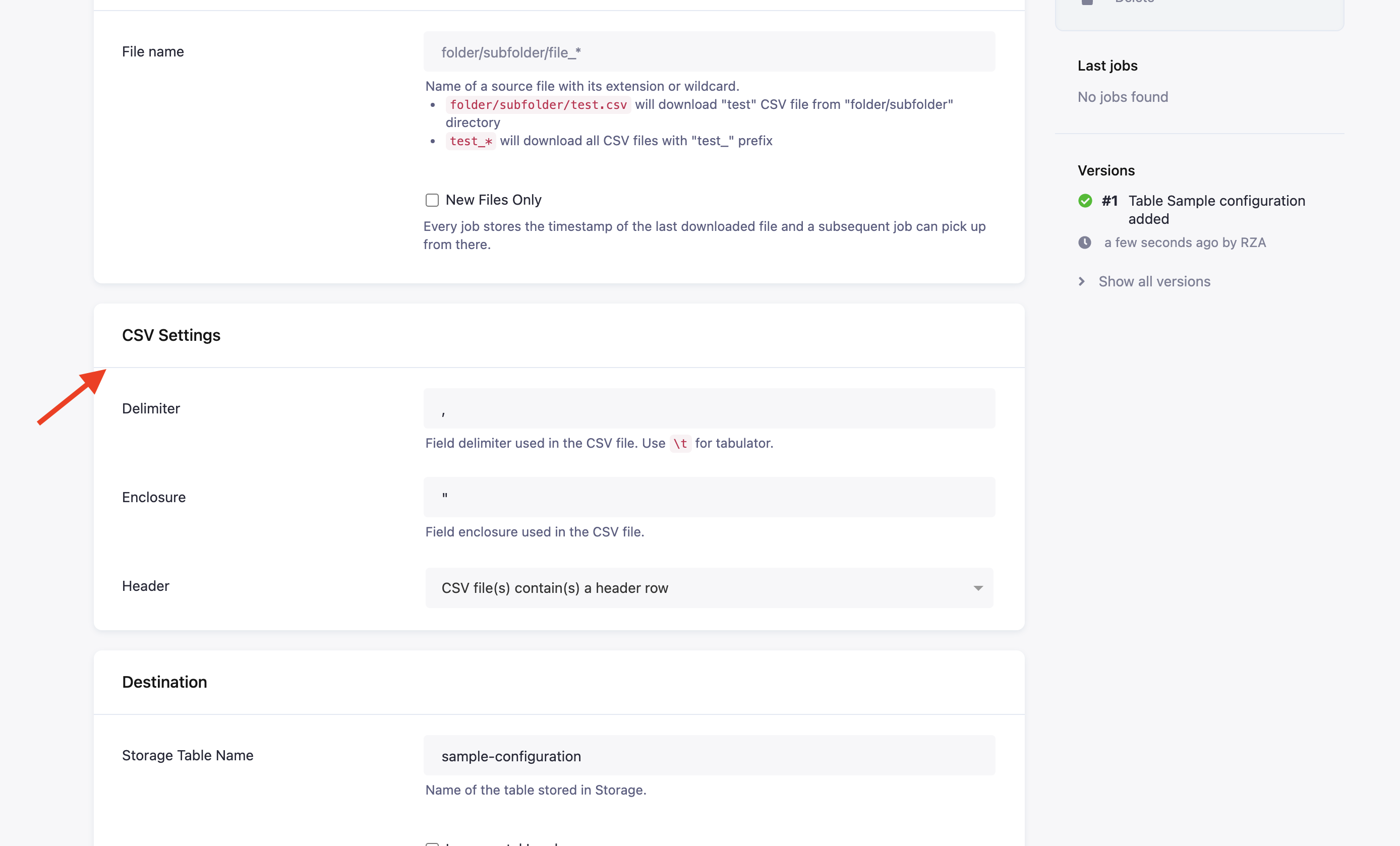
- Delimiter and Enclosure specify the CSV format settings.
- Header specifies how the destination table column names are obtained:
- CSV file(s) contain(s) a header row: All downloaded files contain a row with the CSV header. The connector obtains the header from a randomly selected downloaded file.
- Set column names manually: None of the downloaded files does contain a header row and you will use the Column Names input to specify the headers manually.
- Generate column names as col_1, col_2, etc.: None of the downloaded files contains a header row, and
the connector will generate the column names automatically as a sequential number with the
col_prefix.
Destination
Section titled “Destination”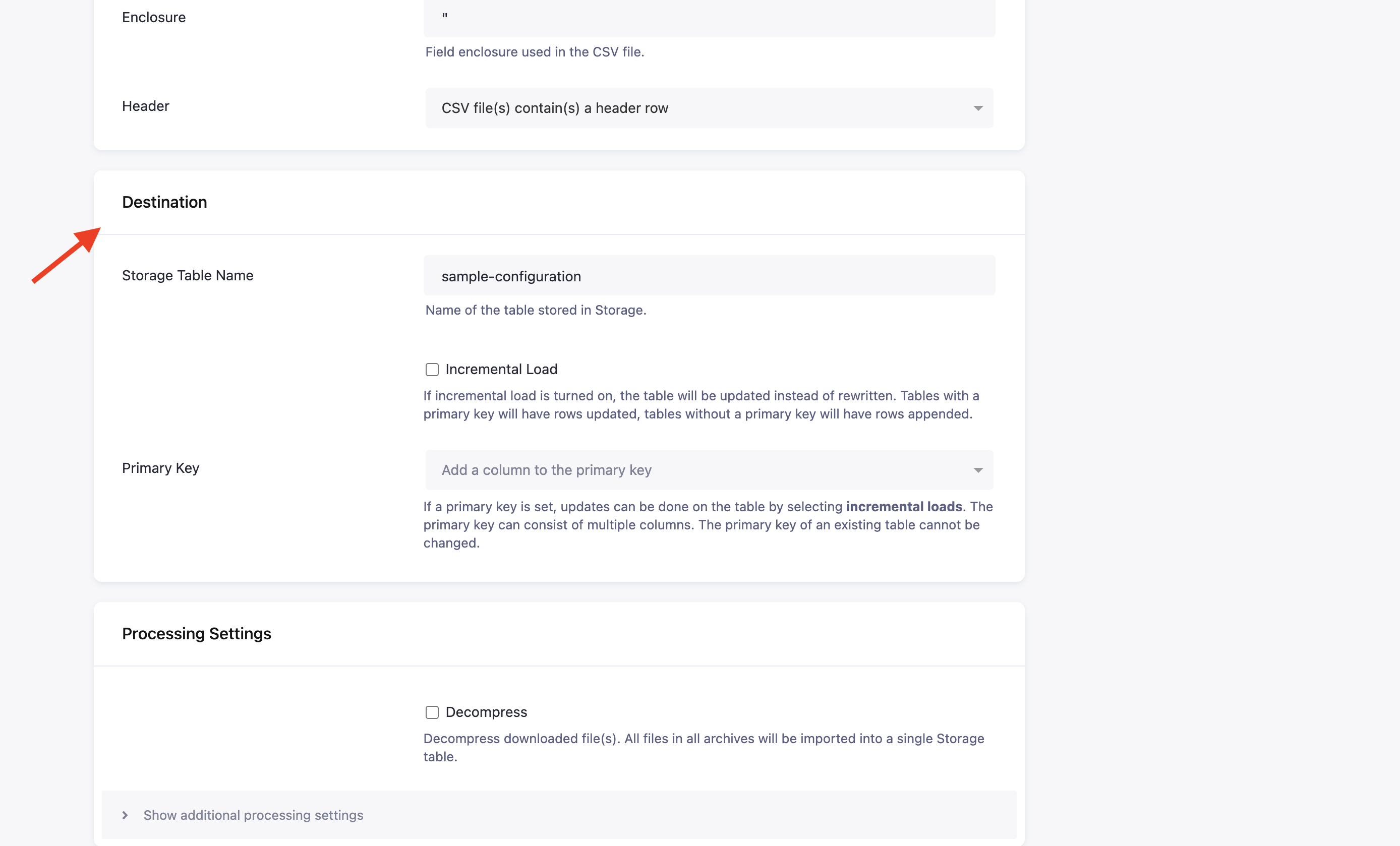
- The initial value in Storage Table Name is derived from the configuration table name. You can change it at any time; however, the Storage bucket where the table will be saved cannot be changed.
- Incremental Load will turn on incremental loading to Storage. The result of the incremental load depends on other settings (mainly Primary Key).
- Primary Key can be used to specify the primary key in Storage; it can be used with Incremental Load and New Files Only to create a configuration that incrementally loads all new files into a table in Storage.
Processing Settings
Section titled “Processing Settings”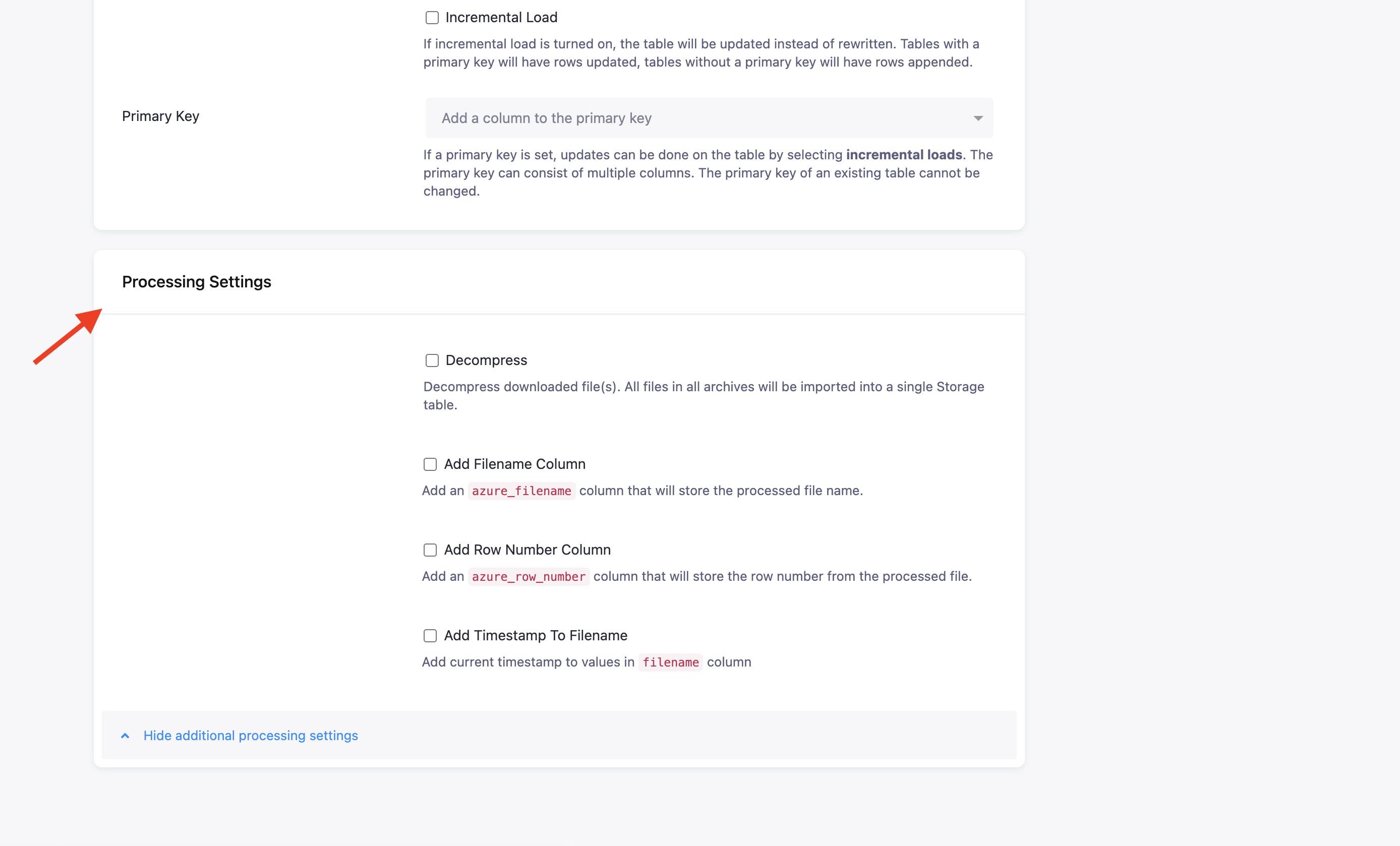
- Decompress: All downloaded files will be decompressed (currently supporting ZIP and GZIP). All files in all archives will be imported into a single Storage table.
- Add Filename Column: A new column
azure_filenameis added to the table and will contain the original filename including the relative path to the Search Key. - Add Row Number Column: A new column
azure_row_filenameis added to the table and will contain the row number in each of the downloaded files.