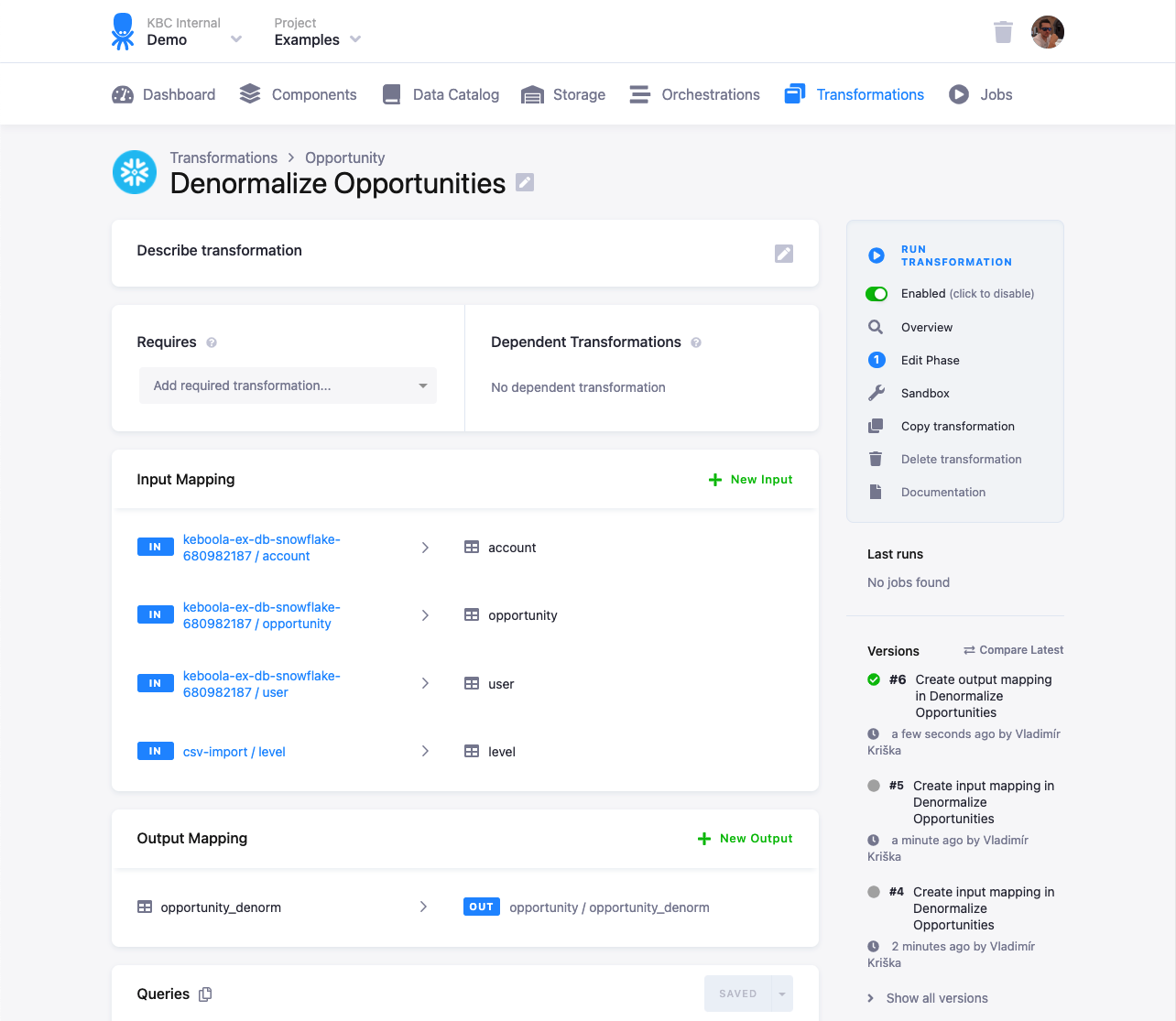
Transformations
Go to our Getting Started tutorial to create your first transformation and learn how transformations are an integral part of the Keboola workflow.
Transformations allow you to manipulate data in your project. They are the tasks you want to perform (marketing data preaggregation, Tableau denormalizer, integrity checker, joining marketing channels and sales, etc.).
In Keboola, all transformations operate on a copy of the data from Storage in a safe and isolated environment. This improves the safety, repeatability, and traceability of all data operations. The process of isolating data is called mapping. The mapping process copies input data from permanent project Storage into a staging area, representing ephemeral Storage to run the transformation script. A transformation backend executes the transformation script. To ease the development of the transformation script, all transformations are automatically versioned, and you can use a workspace that provides a copy of the environment and can be run interactively.
The schema below shows a high-level overview of transformations:

A transformation is represented by a transformation script (SQL, Python, R), which you can use to manipulate your data. To ensure the safety of the data in Storage, a transformation operates in a separate staging Storage created for each transformation.
When a transformation job runs, it takes the required data from the project Storage and copies them to a temporary staging Storage. This process is called input mapping. The transformation job then runs the transformation script operating on the staging storage.
When the transformation is finished, the output mapping process moves the transformation results back to the designated tables in Storage. The input and output mappings ensure complete safety of the transformation processes — the transformation always operates in an isolated workspace.
Mapping
Section titled “Mapping”Input and output mapping --- separates the source data from your transformation. Mapping creates a secure staging area with data copied from the Storage tables specified in the input mappings. Database table names and CSV file names in transformations are completely unrelated to names of tables in Storage. This means, for example, that you can rename tables in Storage without breaking any of your transformations.
There are a number of staging options that influence the transformation script code, too. Typically, you will create an SQL transformation that works with data in a Snowflake database or a Python script that works with CSV files on a “local” disk (local from the script’s perspective). However, it is possible to have a Python script that works with CSV files on Azure Blob Storage (ABS). The transformations are very flexible, though all the combinations might not be available in all projects at all times.
Backends
Section titled “Backends”The Transformation Script is code that defines what happens with the data when the tables from the input mapping are taken, modified, and produced into the tables referenced in the output mapping.
A backend is the engine running the transformation script. It is a database server (Snowflake, BigQuery, DuckDB), or a language interpreter (Python, R).
How do you decide which backend is appropriate for each task? A rule of thumb is that SQL performs better for joining tables, filtering data, grouping, and simple aggregations. Script languages are more suitable for processing one line at a time, raw data processing, or custom analytical tasks. You’re free to use the tools that suit you best.
Each transformation within can use a different backend to perform the task with the most suitable tool and programming language. As some tasks are difficult to solve in SQL, feel free to step in with Python and finish the work with SQL again.
The following are the currently available backends:
- SQL --- Snowflake, Google BigQuery, or DuckDB (beta) is offered as a default backend.
- Script ---Python, or R. Choose according to your taste and available libraries.
Developing Transformations
Section titled “Developing Transformations”Transformation scripts are stored in configurations, and as such, they share common properties and functions. Particularly important is that all changes are automatically versioned, and you can always roll back a configuration or copy a version to a new transformation.
You can easily develop transformations using the workspace. It allows you to run and play with your arbitrary transformation scripts on copies of your tables without affecting data in your Storage or your transformations. You can convert a workspace to a transformation and vice versa.
You’ll obtain database credentials, which you can use with a database client of your choice for Snowflake. In addition, we provide access to the Snowflake web interface. Therefore, you can develop transformations without downloading and installing a database client.
You can also use a workspace represented by an isolated JupyterLab instance for Python and R transformations.
Transformations Features
Section titled “Transformations Features”| Feature | Availability/Limitations | |
|---|---|---|
| Backend | Python Transformations | ✓ |
| R Transformations | ✓ | |
| Snowflake Transformations | ✓ | |
| Google BigQuery | ✓ | |
| DuckDB Transformations | ✓ (beta) | |
| Snowflake Transformations Query timeout | 7200s (configurable per transformation) | |
| Snowflake Transformations Dynamic Backend | ✓ | |
| Oracle Transformations | ✓ | |
| Development tools | Naming | Workspace |
| Max number | Unconstrained | |
| Lifecycle | Sleeps after 1 hour of inactivity; can be resumed (if the auto-sleep feature is supported and enabled) | |
| Resume | ✓ | |
| Load data | ✓ | |
| Unload data | ✓ | |
| IDE | JupyterLab | |
| Other features | ✓ | Not available |
| Versioning | ✓ | |
| Copying | ✓ | |
| Phases | Not available | |
| Dependencies | Not available | |
| API Interface | ✓ | |
| Shared code | ✓ | |
| Variables | ✓ | |
| Code patterns | ✓ | |
Transformations
Section titled “Transformations”Transformations behave like any other component. This means that they use the standard API to manipulate and run configurations and that creating your own transformation components is possible.
Transformations support sharing pieces of code, encouraging users to create reusable blocks of code. They also support variables that can be used to parametrize transformations.
Apart from that, transformations come with workspaces (previously named Sandboxes), which have many new features, such as loading and unloading data with a running workspace or resuming the workspace.
Writing Scripts
Section titled “Writing Scripts”The transformation script can be organized into pieces that we call code, and these can be further organized into blocks. This allows you to somehow structure lengthy scripts. The structure provides no executional isolation --- all code pieces execute sequentially in the same context in a top-down left-to-right direction. You can assign custom names to individual blocks and code pieces. You can reorder both the code elements and blocks by dragging them:
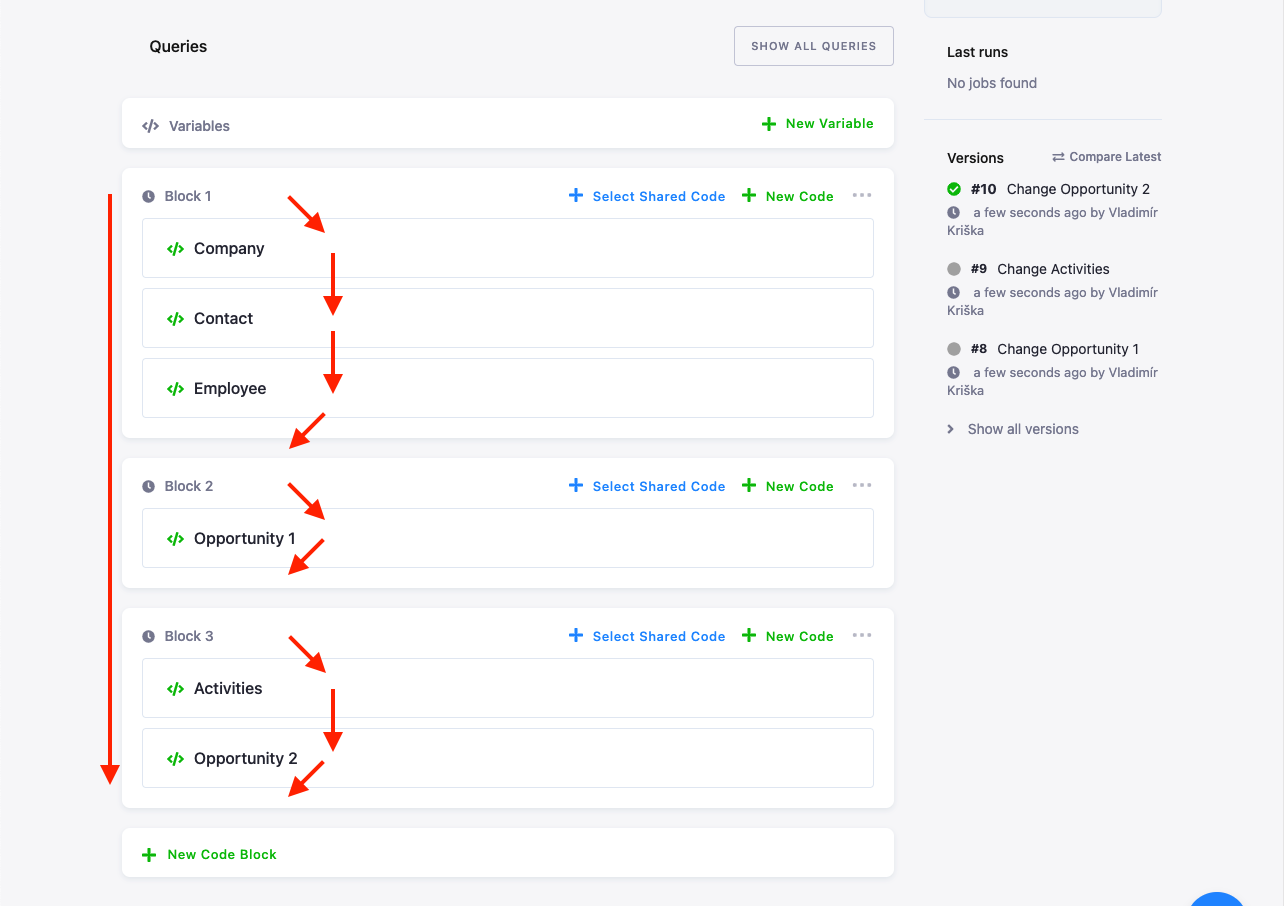
The above setup, therefore, executes Company, Contact, Employee, Opportunity & Auxiliary, Activities, Opportunity & Contact as if it were a single script (SQL in this case). Splitting the code into scripts is in no way required. You can put your whole script in a single block and code.
Autocompletion
Section titled “Autocompletion”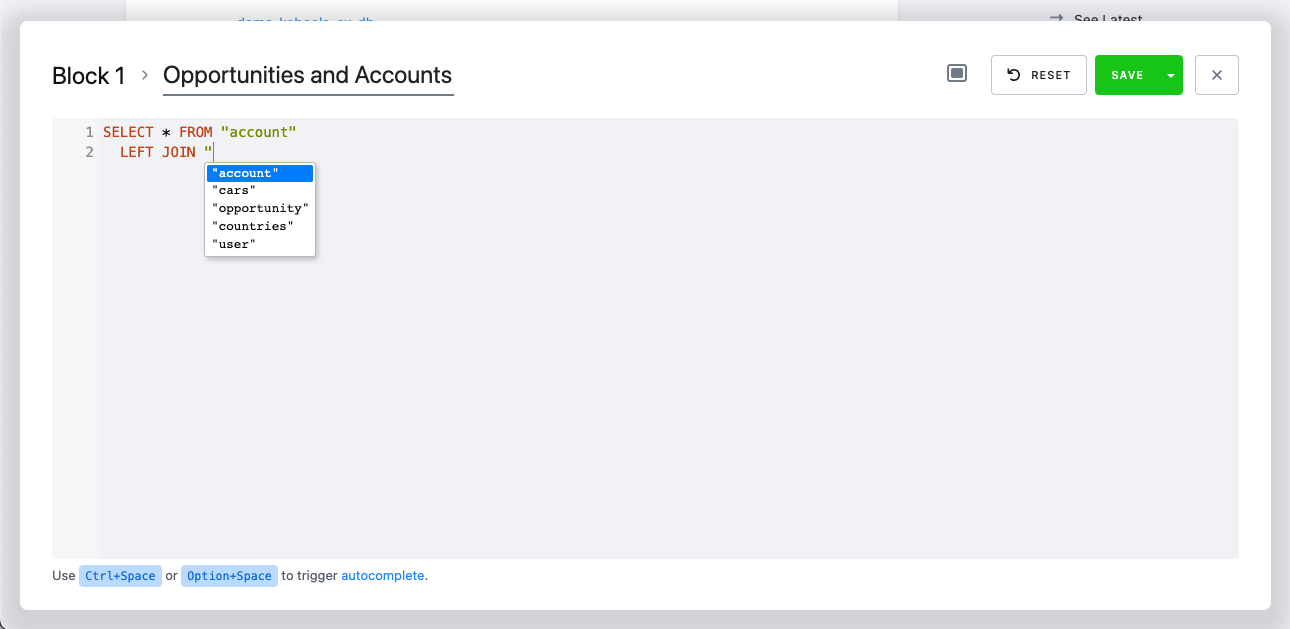
To improve code editing, we support autocompletion in the editor.
Currently, it supports autocompletion of:
- Language-specific reserved words
SELECT,UPDATE, etc., in SQL transformationsimport,while, etc., in Python transformations- Tables you added to input mapping or output mapping
- When working with Python or R transformations, a relative path will be suggested (e.g.,
in/tables/cars.csv). - Variables you defined in your transformation (also with values)
To trigger autocompletion, use Ctrl+Space or Option+Space as you would in your favorite IDE/editor.
When triggered
- after typing
", it will suggest available tables. - after typing
{{, it will suggest available variables. - in other cases, it will suggest everything (see the screenshot above).
Read-Only Input Mapping
Section titled “Read-Only Input Mapping”With the read-only input mapping feature, you can access all buckets (your own or linked) in transformations. Your transformation user has read-only access to buckets (and their tables), so you can access such data. So, there is no need to specify standard input mapping for your transformations. The name of the backend object (database, schema, etc.) depends on the backend you use, and it contains the bucket ID (not the bucket name).