ThoughtSpot
This data destination connector sends data to the ThoughtSpot platform.
Configuration
Section titled “Configuration”Create a new configuration of the ThoughtSpot data destination connector. Then Set Up Credentials. You need to provide a host name, user name, password, database name, schema, SSH user, and SSH password. The connector uses the TSLOAD CLI tool and TQL commands to load that data. These commands are executed on the server through an SSH connection. Therefore the SSH credentials are needed to connect to the server instance.
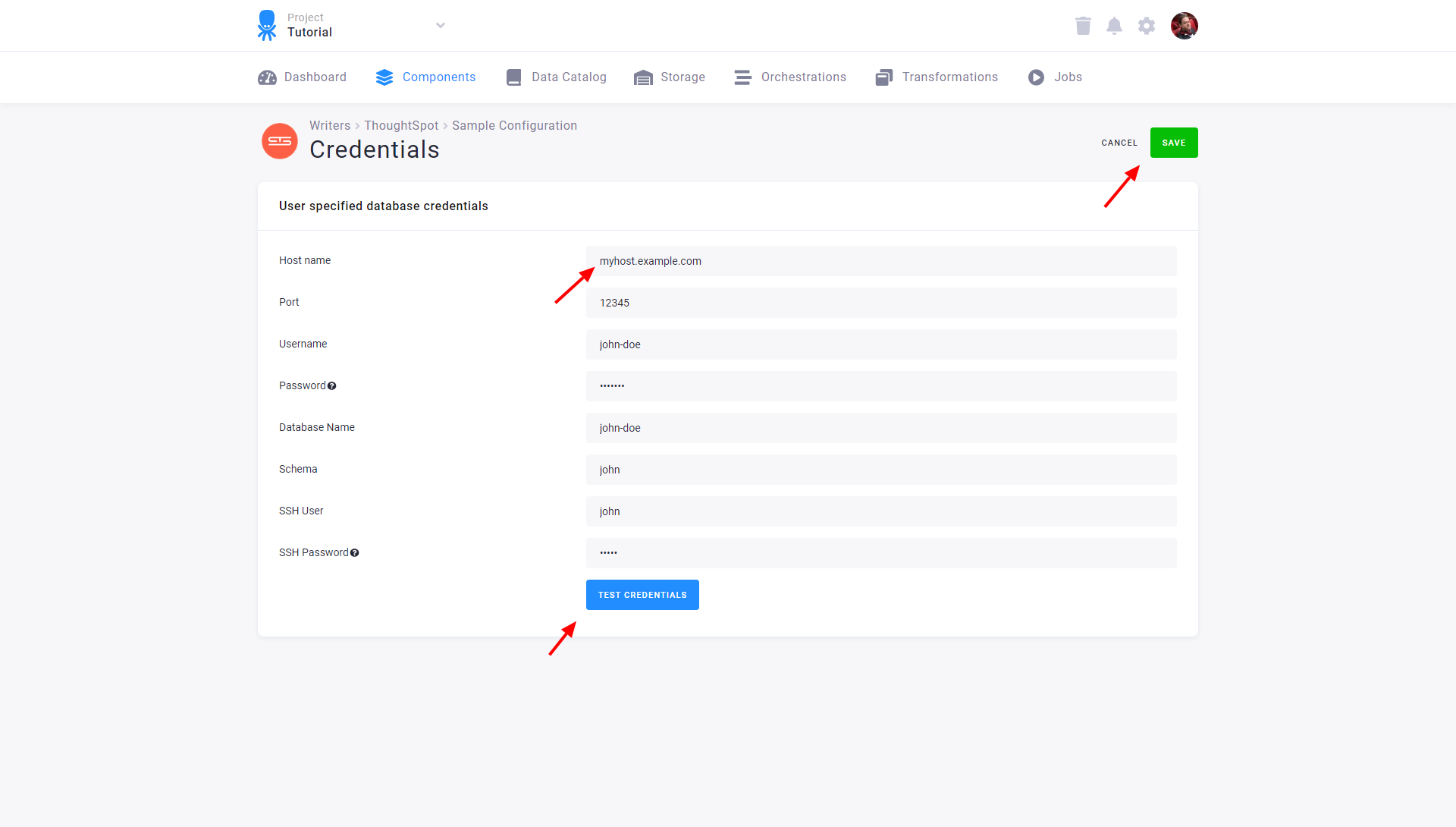
Table Configuration
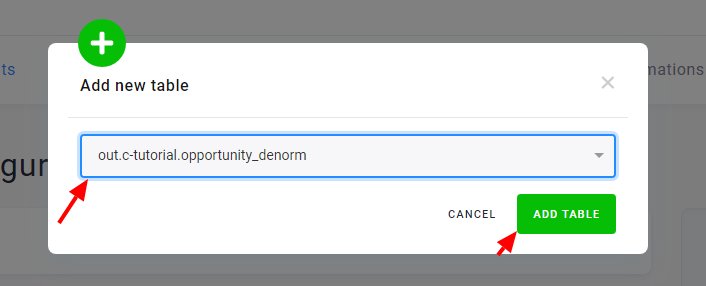
Section titled “Table Configuration”The next step is to configure the tables you want to write. Click the Add New Table button and select an existing table from Storage:
Then specify the table configuration. Use the preview icon to peek at the column contents.
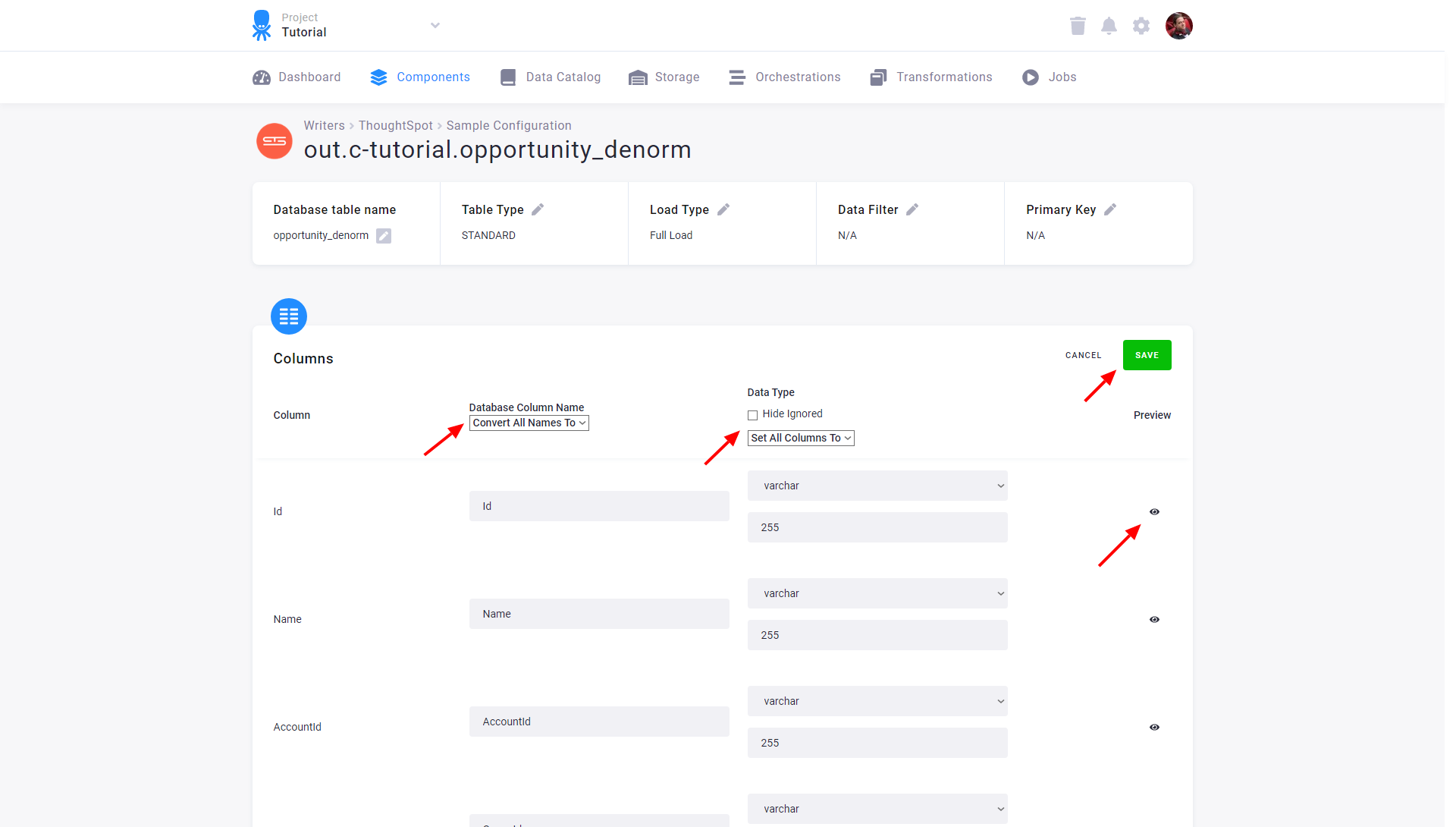
For each column you can specify its
- name in the destination database; you can also use the select box in the table header to bulk convert the case of all names.
- data type (one of the supported data types); you can also use the select box in the table header to bulk set the type for all columns. Setting the data type to
IGNOREmeans that the column will not be present in the destination table.
When you’re done configuring the columns, don’t forget to Save the settings.
Load Options
Section titled “Load Options”At the top of the page, you can specify the target table type and name additional load options. The table type is
one of STANDARD, FACT, and DIMENSION. See an explanatory article
about schema design or the official guide for
more details on designing the data schema.
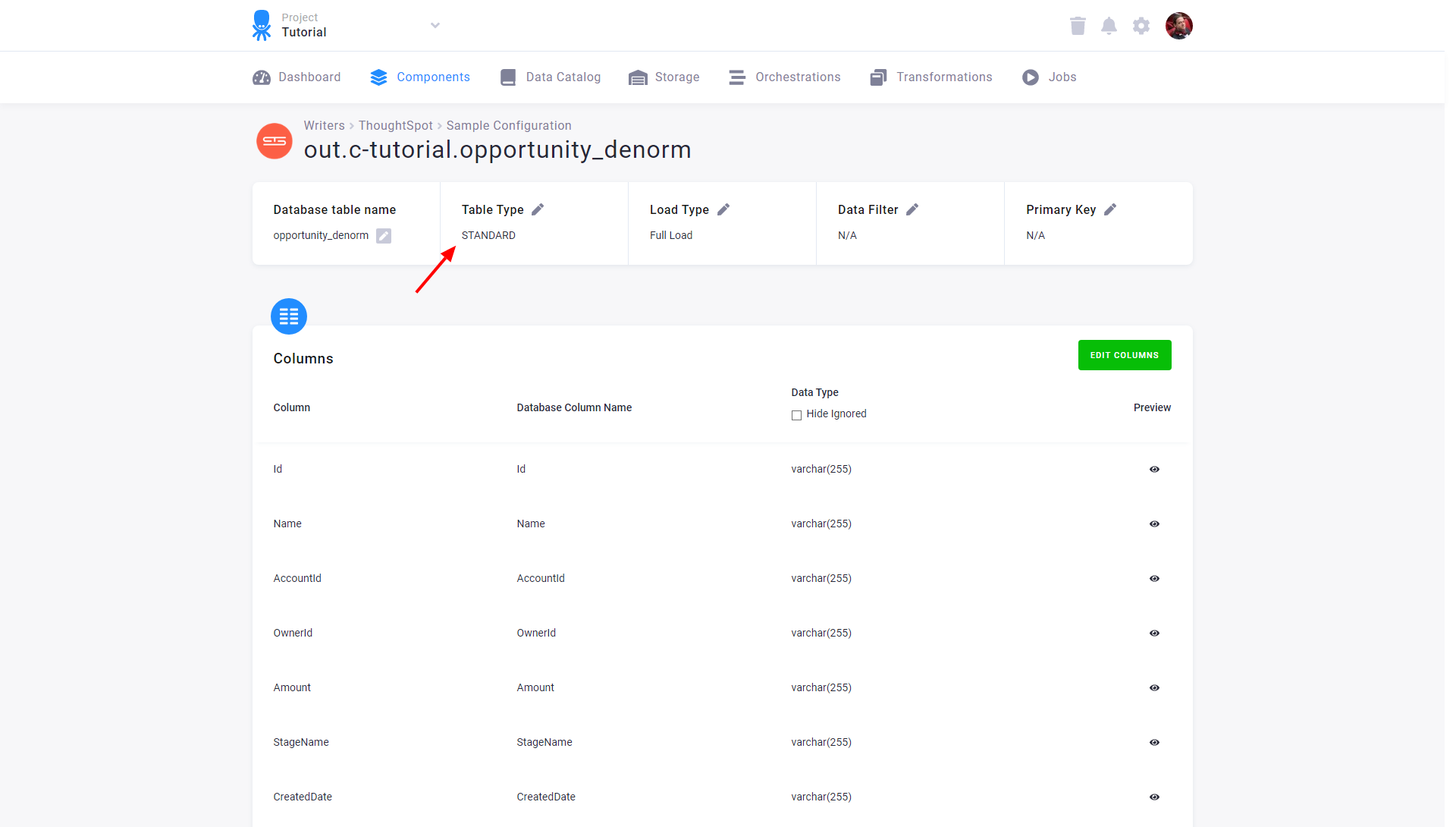
There are two main options how the data destination connector can write data to tables --- Full Load mode and Incremental Load mode.
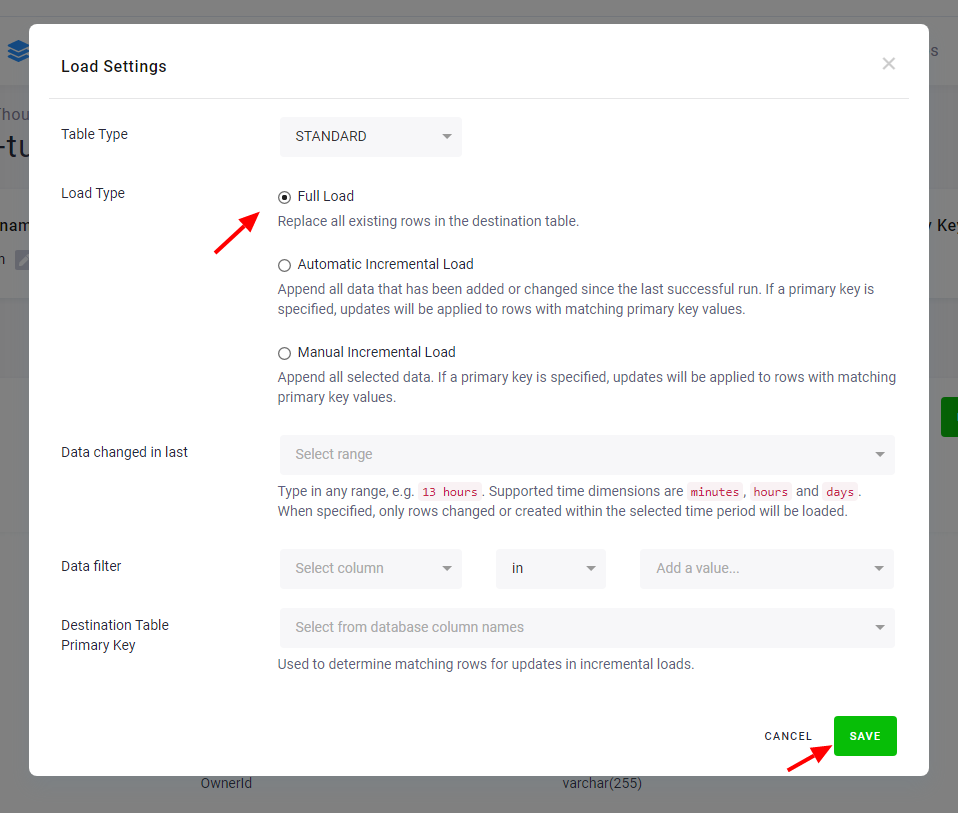
In the Incremental Load mode, the data are bulk inserted into the destination table and the table structure must match (including the data types). That means the structure of the target table will not be modified. If the target table doesn’t exist, it will be created. If the table has a primary key, the data is upserted. If no primary key is defined, the data is inserted.
In the Full Load mode, the table is completely overwritten including the table structure. The table is removed
using the DROP command and it is recreated.
Additionally, you can specify a primary key for the table, a simple column data filter, and a filter for incremental processing.