External Datasets
If you operate Keboola in Bring-Your-Own-Database (BYODB) mode using your own data warehouse, the data in the warehouse won’t automatically be visible or accessible within Keboola. To address this, we offer the External Datasets feature.
The implementation of External Datasets requires the BYODB to be enabled first. Unless specified otherwise, this description refers to the implementation of Snowflake and BigQuery.
What Is an External Dataset?
Section titled “What Is an External Dataset?”Storage in Keboola is organized into buckets. An external dataset is a special type of bucket wherein Keboola does not manage its content. It can be located anywhere in the storage backend used by your Keboola project (Snowflake or BigQuery) and is a virtual bucket connected to a Snowflake schema or BigQuery dataset, respectively.
All table-like objects (such as tables, views, and external tables) inside the schema (in Snowflake) or dataset (in BigQuery) are mapped to tables in the bucket. Access to the bucket is read-only; you cannot write to the bucket from Keboola. A single schema can be registered simultaneously with multiple projects in Keboola.
Creating an External Dataset
Section titled “Creating an External Dataset”An external dataset can be registered in the Storage of a project. Go to Storage > Register External Dataset. The dialog will differ based on the backend you are using.
Snowflake
Section titled “Snowflake”Fill in the name of the new bucket, database name, and schema name. Click Next Step. Keboola will then generate a code that you can use to grant Keboola correct access to the schema in your Snowflake. Once access has been granted, click Register Dataset to start using it.
BigQuery
Section titled “BigQuery”Fill in the name of the new dataset and dataset name. Click Next Step. Keboola will generate a code that you can use to grant Keboola correct access to the dataset in BigQuery. Once access has been granted, click Register Dataset to start using it.
BigLake Tables
Section titled “BigLake Tables”Keboola generally does not support external tables, except for BigLake tables. Please ensure that any table you are using is of this type. External tables of other types will not work in transformations and workspaces due to permission issues.
Please ensure that you can perform a SELECT * FROM <table> LIMIT 1 query on your created BigLake table. Keboola checks this during the registration process.
If the SELECT fails, the table will be skipped.
The only exceptions are tables configured with require_hive_partition_filter=true. Such configurations of BigLake tables are supported by Keboola, but
SELECT operations (like Data Preview) will fail. This is expected behavior. You can still use these tables in your workspaces and transformations, but
appropriate WHERE conditions are necessary.
Using an External Dataset
Section titled “Using an External Dataset”When you register an external dataset, we analyze the metadata of the objects in it and register all tables and views as tables in the Keboola Storage bucket. If you later add additional tables or views, you must manually refresh the Storage bucket using the Refresh action in the bucket detail to make them visible in Keboola.
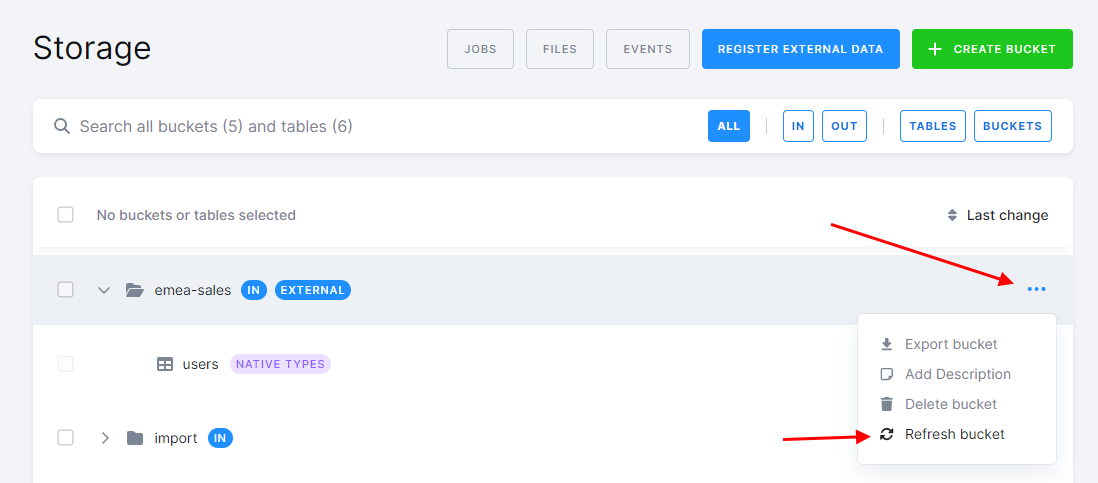
External datasets can be used in an input mapping. If you would like to disable usage of External datasets in input mapping, reach out to our support to disable it. They are also accessible via the read-only input mapping. Keep in mind that external buckets cannot be used in an output mapping as they are not writable.
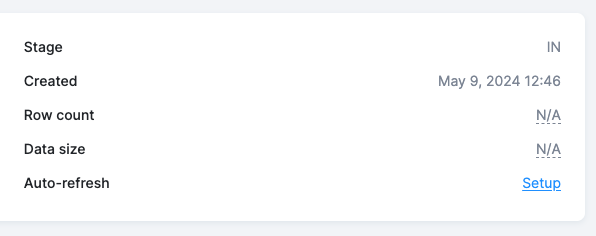
Auto-Refresh
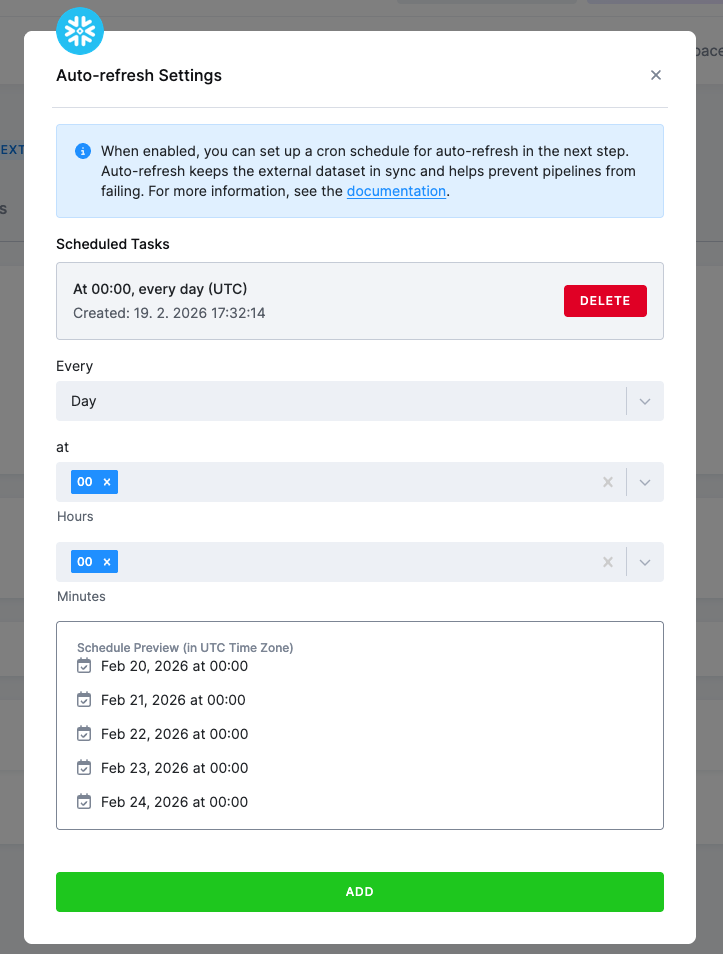
Section titled “Auto-Refresh”You can enable Auto-refresh for external buckets using a cron scheduler. Auto-refresh ensures that your external dataset remains synced with the source schema and prevents pipelines from failing due to outdated metadata.
To configure Auto-refresh, navigate to the bucket detail and click on the Auto-Refresh tab. Here you can set up a cron schedule that determines how often the bucket metadata will be refreshed automatically.
External Dataset in a Snowflake SQL Transformation
Section titled “External Dataset in a Snowflake SQL Transformation”External datasets cannot be used in an input mapping as they are not copied into your transformation workspace. You need to reference them in your transformation using a fully qualified name.
In the following example, it is assumed that you’ve created an external dataset called users-reporting that references the sales_emea schema in the database
REPORTING. The schema contains a table called users. Now you want to create a new table MQL_USERS that contains only users sourced from
marketing-qualified leads. You can do that using the following SQL:
CREATE TABLE "MQL_USERS" AS SELECT *FROM "REPORTING"."sales_emea"."users"WHERE "source" = 'mql';External Dataset in a BigQuery SQL Transformation
Section titled “External Dataset in a BigQuery SQL Transformation”For BigQuery, an external dataset is mapped to an actual dataset, users_reporting (the name you filled in the dialog), in your project—in this case, project sapi-9752. You can reference the contents of the dataset in your SQL transformation using a fully qualified name:
CREATE TABLE `MQL_USERS` AS SELECT *FROM `users_reporting`.`users`WHERE `source` = "mql";Sharing an External Dataset
Section titled “Sharing an External Dataset”It is possible to share an external dataset using the same process as any other Storage bucket. Once the bucket is shared, the refresh operation is only available in the source project (the project where the external dataset was registered). Currently, it is possible to share entire buckets, not specific tables within them.
Snowflake
Section titled “Snowflake”Sharing a Snowflake external dataset works out of the box — no additional configuration is required beyond the standard bucket sharing flow.
BigQuery
Section titled “BigQuery”Sharing a BigQuery external dataset is supported, but requires additional IAM permissions to be granted on your Analytics Hub listing. This is because BigQuery Analytics Hub does not allow re-sharing a linked (subscribed) dataset — instead, the target project must subscribe directly to your original listing. Keboola handles this automatically, but needs permission to grant subscriber access on your behalf.
To enable sharing, grant one of the following to the Keboola service account on your Analytics Hub listing, in addition to the roles/analyticshub.subscriber already required for registration:
Option 1 — Custom role (recommended, least privilege): Create a custom IAM role in your GCP project with exactly these two permissions:
analyticshub.listings.getIamPolicyanalyticshub.listings.setIamPolicy
The scope of this custom role depends on where your external datasets live:
- If all external datasets come from a single GCP project, create the custom role at the project level and grant it to the Keboola service account on that project.
- If external datasets come from multiple GCP projects across your organization, create the custom role at the organization level so it can be applied across projects.
Option 2 — Built-in roles/analyticshub.listingAdmin (simpler, broader permissions):
Grant the built-in roles/analyticshub.listingAdmin role to the Keboola service account on your listing. This role includes the required permissions, but also covers additional capabilities (such as updating or deleting the listing) that Keboola does not use.
Removing an External Dataset
Section titled “Removing an External Dataset”Removing an external dataset is as simple as removing any other Storage bucket. Simply delete it in the UI or via API. The Storage bucket will be removed from the project, but the schema in the database will remain untouched. Any rights that you have granted to Keboola during the registration will be revoked.
If you wish to remove the schema, you must do so manually in your warehouse.
Usage Recommendations
Section titled “Usage Recommendations”- Use external datasets to work with data in your warehouse that has been produced by third-party tools outside Keboola.
- Use external datasets to access data in table-like structures that are not directly supported by Keboola (e.g., views and external tables).
- Using external datasets to load data from services with existing components into Keboola is discouraged. Consider the following limitations of such an approach:
- You would have to orchestrate, maintain, and monitor the external pipeline, which Keboola normally does for you.
- Manipulation of the data will not be tracked in the Keboola audit trail.
- Event-driven triggering is not supported for external datasets, so you must manually synchronize the external and Keboola pipelines based on time.
- While there are legitimate uses of external tools, keep in mind that by having data pipelines outside Keboola, you lose the main benefit of Keboola—the ability to orchestrate, maintain, monitor, and audit the pipelines in one place.
Limitations
Section titled “Limitations”- Table names can’t be longer than 92 characters and can contain only alphanumeric characters, dashes, and underscores. Tables that do not meet these requirements will be ignored.
- Table names are not case-sensitive. You cannot create two tables with the same name that differ only in letter case.
- Creating snapshots from tables in external buckets is not supported.
- A read-only input mapping with an external dataset has a limitation. If you delete and recreate a registered table in the source schema, our read-only input mapping will lose access to this table. This occurs because we aim to limit clients from having excessive permissions, such as OWNERSHIP, on their external schemas. However, manually refreshing the bucket addresses this issue.
To permanently resolve this issue, you can manually grant the read-only input mapping role future access to your tables and views as illustrated below:
GRANT SELECT ON FUTURE TABLES IN SCHEMA "REPORTING"."sales_schema" TO ROLE KEBOOLA_8_RO;GRANT SELECT ON FUTURE VIEWS IN SCHEMA "REPORTING"."sales_schema" TO ROLE KEBOOLA_8_RO;GRANT SELECT ON FUTURE EXTERNAL TABLES IN SCHEMA "REPORTING"."sales_schema" TO ROLE KEBOOLA_8_RO;Ensure the role name follows the pattern in the picture and is suffixed with `_RO`.