Keboola Overview
Keboola is a cloud-based platform for all your data integration, transformation, and orchestration needs. Designed for data engineers, analysts, and scientists, Keboola simplifies data processes, enabling efficient management and insightful analysis.
Key features of Keboola:
- Data Integration: Effortlessly extract data from various sources like databases, cloud services, and APIs. Load it seamlessly into destinations of your choice for comprehensive analysis.
- Data Storage: Use Keboola’s robust data warehousing (Snowflake, BigQuery, etc.) for secure and accessible data storage.
- Data Manipulation: With our extensive toolset, clean, enrich, and transform your data using SQL, Python, R, and more directly within Keboola.
- Automation: Automate your data workflows end-to-end with Keboola’s intuitive Flows, saving time and reducing manual errors.
Deployment Options
Section titled “Deployment Options”Keboola supports various deployment models to suit your specific needs:
- Fully Managed: Let us handle everything for you.
- Multi-Tenant: Let us fully manage and maintain all resources.
- Multi-Tenant with BYO Database: Use your data storage (Snowflake, BigQuery, etc.) while we manage the rest.
- Single-Tenant: Deploy Keboola in your cloud environment (AWS, Azure, GCP) for maximum control and security.
Keboola Architecture
Section titled “Keboola Architecture”Keboola organizes accounts by projects, offering a single project on the Free Plan and multiple projects under its subscription models. This multi-project architecture supports a Data Mesh strategy and a customizable data warehouse structure for various needs and use cases.
The following diagram illustrates the structure of a single Keboola project, composed of various categorized components described below.
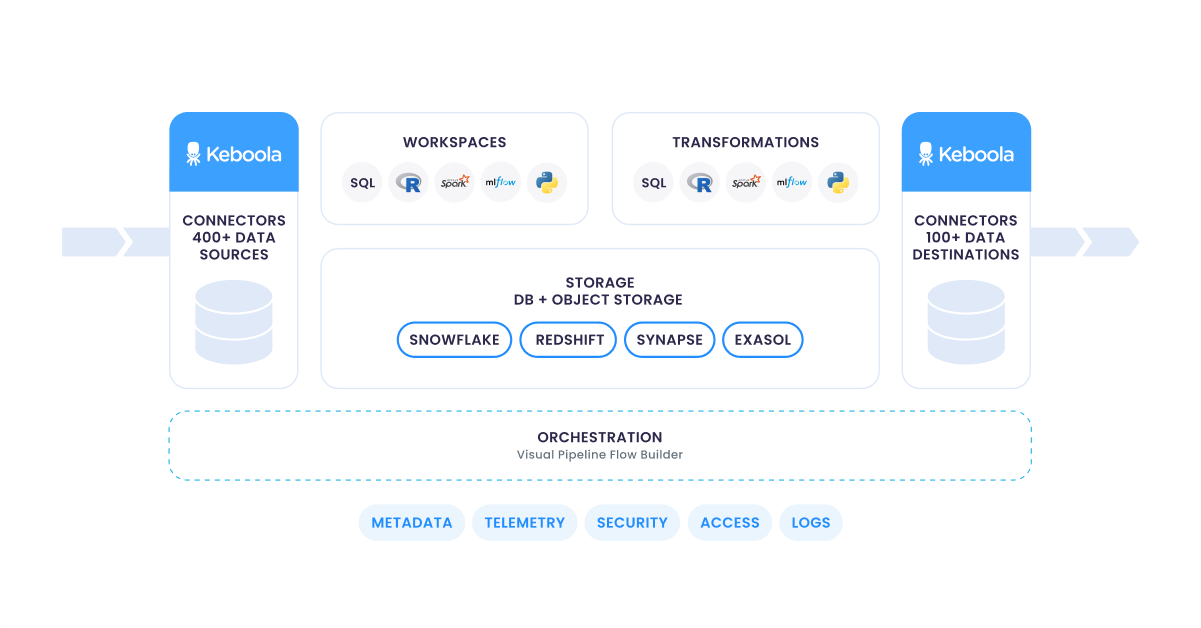
Data Source Connectors
Section titled “Data Source Connectors”Data source connectors, formerly known as extractors, are Keboola components used to gather data from various sources. They can connect to APIs of external services, databases, applications, object storage, and many others.
Storage
Section titled “Storage”Storage is the central component in Keboola responsible for data management and access. It comprises two sections:
- File Storage, with all raw files uploaded to your project, and
- Table Storage, where all data tables are organized into buckets, further categorized into in and out stages.
This component acts as a middle layer that works with various backend database systems like Snowflake, BigQuery, and others. It provides a key Storage API for working with data, making it easier to connect with other parts of the system and third-party applications.
Transformations & Workspaces
Section titled “Transformations & Workspaces”Transformations allow you to manipulate data in your project. They are the tasks you want to perform and enable you to write custom scripts in SQL (Snowflake, BigQuery, etc.), dbt, Python, and R.
All transformations operate on a copy of Storage data in an isolated environment — a workspace, guaranteeing safety for your analyses and experimentation. Workspaces support collaborations and can be shared.
- SQL workspaces are accessible through the database provider’s IDE or your preferred SQL IDE.
- Python and R workspaces are available through Keboola’s hosted and managed JupyterLab environment.
Applications
Section titled “Applications”Unlike free-form transformations, applications are predefined blocks that enable users to perform advanced tasks such as sentiment analysis, association discovery, or histogram grouping. They can also enhance data, for example, by incorporating external data like weather or exchange rates through third-party services.
Apps are simple web applications that can be deployed inside Keboola projects and also publicly accessed from outside the projects. They are usually custom-built to address specific challenges, for example, recommendation engines, interactive segmentation tools, AI integration solutions, data visualization platforms, custom internal reporting tools for business teams, and financial apps for gaining insights into spending patterns.
Data Destination Connectors
Section titled “Data Destination Connectors”Data destination connectors, formerly known as writers, are components responsible for output data delivery from Keboola to the systems and applications where the data gets used or consumed (relational databases, BI, reporting and analytics platforms, tools, or applications).
Full Automation
Section titled “Full Automation”The Flows feature helps you to fully automate end-to-end processes. You can specify the order in which individual connectors, transformations, and other components will be run and set up parallelization. By adding a schedule or trigger, you can automate processes at specified intervals or times of the day.
The platform automatically scales resources to facilitate the automated processes.
Development Branches
Section titled “Development Branches”The Development Branches feature enables you to modify component settings without affecting active configurations or entire orchestrated workflows. It’s particularly useful for implementing significant project changes or when you need to be extra careful about performing your changes safely.
Keboola Governance
Section titled “Keboola Governance”Operational Metadata
Section titled “Operational Metadata”Keboola collects diverse operational metadata, including user activity, job status, data flow, schema evolution, data pipeline performance, and adherence to a client’s security rules. All project metadata is accessible in your project and enables you to perform in-depth analyses, audits, or event-driven actions.
This metadata enables us to automatically create data lineage, offering real-time insights into data origin and usage for analytical and regulatory needs and highlighting the data’s journey and usage on the platform.
Cost Monitoring
Section titled “Cost Monitoring”Keboola collects telemetry data on job executions and user activities, detailing credit units used per job for exact cost calculations. This allows costs to be attributed to specific departments, teams, use cases, and users, offering detailed insights into resource use.
Identity and Access management
Section titled “Identity and Access management”Manage user accounts in your organization, controlling their access to specific Keboola projects and datasets. Simplify data sharing within your organization, keep track of individual access rights, and promote clear visibility of data access.
Extending the Platform
Section titled “Extending the Platform”The Keboola platform, as an open environment consisting of many built-in interoperating components (Storage, transformations, data source connectors, etc.), can be extended with arbitrary code to extract, transform, or write data.
You can extend the platform by creating
- components (used as data source and destination connectors and applications).
- components based on the Generic Extractor.
Keboola, your in-house teams, or 3rd parties can create all components while using already existing data, ETL processes, and workflows. The platform automates infrastructure, user, and data management, offering services like data catalog, operational metadata, governance, and reverse billing. Components can be private or shared with Keboola users via our marketplace featuring applications mainly from 3rd parties to enhance workflows and support a composable enterprise.
Components can be run as standard pieces of our Flows [/tutorial/automate/#main-header], obtaining the full support and services (a link to your components, logs, etc.).
Keboola CLI
Section titled “Keboola CLI”Keboola CLI (Command Line Interface) is a set of commands for operating your cloud data pipeline. It can be installed in the Windows, macOS, and Linux environments.
AI Assistance
Section titled “AI Assistance”The Keboola AI feature can increase your productivity in several areas, such as:
- Suggesting descriptions of configurations: This includes transformations, components, and flows. Note that the configuration is sent to the AI service as part of description generation.
- Explaining errors: When a job finishes in failure, an error is reported. You can request an explanation of this error. Note that the error is sent to the AI service as part of explanation generation.
We’re using a privately deployed Microsoft Azure OpenAI for the AI service. Prompts and responses are NOT used to train the model. However, you should not place any sensitive information (such as API keys and passwords) into the code of transformations, descriptions or any metadata, as their contents are not consider secret and may be processed by the AI service, as well as logs or telemetry processes.
Keboola Support
Section titled “Keboola Support”When working with the Keboola platform, you are never on your own, and there are multiple ways to obtain support from us. To solve your problem or to gain context, our support staff may join your project when requested.
Other Commonly Used Terms
Section titled “Other Commonly Used Terms”This section explains a few terms often used throughout these documentation pages.
Stacks
Section titled “Stacks”The Keboola platform is available in multiple stacks, either multi-tenant or single-tenant. The current multi-tenant stacks are:
- US Virginia AWS – connection.keboola.com,
- US Virginia GCP - connection.us-east4.gcp.keboola.com
- EU Frankfurt AWS – connection.eu-central-1.keboola.com
- EU Ireland Azure – connection.north-europe.azure.keboola.com
- EU Frankfurt GCP - connection.europe-west3.gcp.keboola.com
A stack combines a datacenter location (region) and a cloud provider and is identified by its domain (URL). The currently supported cloud providers are Amazon AWS, Microsoft Azure, and Google Cloud. A stack is an entirely independent, full instance of Keboola platform services. That means that if you have projects in multiple stacks, you need to have multiple Keboola accounts.
Each stack uses a different network with a different set of dedicated IP addresses. Our developer documentation describes how to handle multiple stacks when working with the API in more detail.
Single-tenant stacks are available for a single enterprise customer with a domain name in the form connection.CUSTOMER_NAME.keboola.com.
Most things in the Keboola platform are done using the batch approach; when you perform an action, a job is created and executed in the background. We also call these jobs asynchronous. Multiple jobs can run simultaneously, and you can continue your work in the meantime.
Tokens
Section titled “Tokens”In Keboola, every action requires a token for authorization, automatically assigned to users at first login. Additionally, tokens for restricted access can be created and shared. This token system enables easy sharing of specific resources, like tables, without requiring platform registration.
Input and Output Mapping
Section titled “Input and Output Mapping”To make sure your transformation does not harm data in Storage, mapping separates source data from your script. A secure workspace is created with data copied from the tables specified in the input mapping. After the transformation is executed successfully, only tables and files defined in the output mapping are returned to Storage.