- Home
- Keboola Overview
- Getting Started Tutorial
- Kai - AI Assistant
-
Flows
- Conditional Flows
- Orchestrations
-
Templates
- Advertising Platforms
- AI SMS Campaign
- Customer Relationship Management
- DataHub
- Data Quality
- eCommerce
- eCommerce KPI Dashboard
- Google Analytics 4
- Interactive Keboola Sheets
- Mailchimp
- Media Cashflow
- Project Management
- Repository
- Snowflake Security Checkup
- Social Media Engagement
- Surveys
- UA and GA4 Comparison
- Data Apps
-
Components
-
Data Source Connectors
- Communication
- Databases
- ERP
-
Marketing/Sales
- Adform DSP Reports
- Babelforce
- BigCommerce
- ChartMogul
- Criteo
- Customer IO
- Facebook Ads
- GoodData Reports
- Google Ads
- Google Ad Manager
- Google Analytics (UA, GA4)
- Google Campaign Manager 360
- Google Display & Video 360
- Google My Business
- Linkedin Pages
- Mailchimp
- Market Vision
- Microsoft Advertising (Bing Ads)
- Pinterest Ads
- Pipedrive
- Salesforce
- Shoptet
- Sklik
- TikTok Ads
- Zoho
- Social
- Storage
-
Other
- Airtable
- AWS Cost Usage Reports
- Azure Cost Management
- Ceps
- Dark Sky (Weather)
- DynamoDB Streams
- ECB Currency Rates
- Generic Extractor
- Geocoding Augmentation
- GitHub
- Google Search Console
- Okta
- HiBob
- Mapbox
- Papertrail
- Pingdom
- ServiceNow
- Stripe
- Telemetry Data
- Time Doctor 2
- Weather API
- What3words Augmentation
- YourPass
- Data Destination Connectors
- Applications
- Development Branches
- IP Addresses
-
Data Source Connectors
- Data Catalog
- Storage
- Transformations
- Workspaces
- Management
- AI Features
- External Integrations
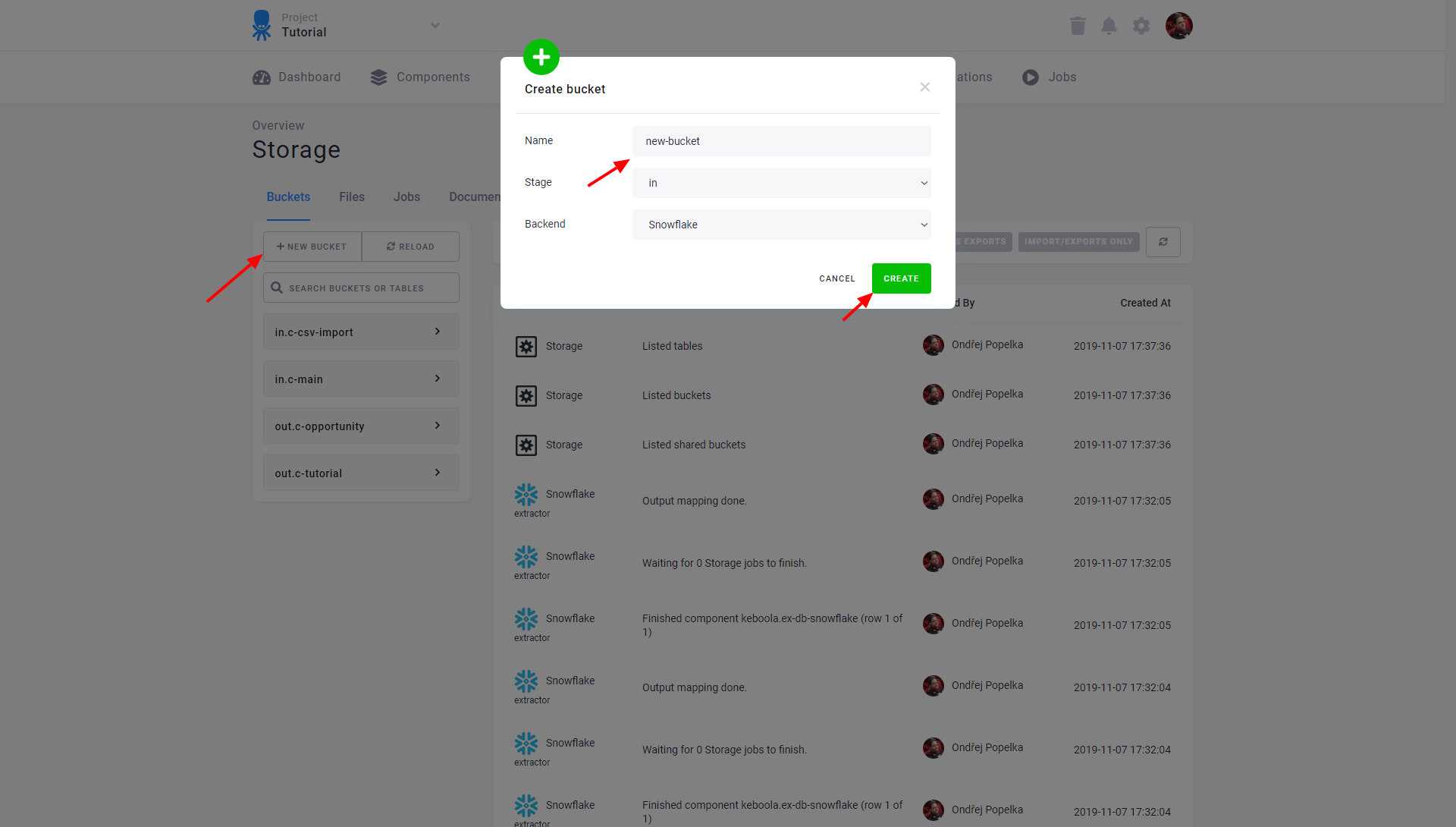
Buckets
Buckets are containers for tables in Storage. They are further organized into the following two stages:
- in — for input data (usually data source connector results)
- out — for processed data (usually results of transformations or applications)
The distinction between the input and output stages is purely conventional differentiation between raw and processed data. When creating a new bucket, select one of the stages and a suitable database backend based on its properties. For information on how to load data into Storage, see the corresponding part of our tutorial.
To review information about an existing bucket, hover over the bucket name and select Bucket detail:
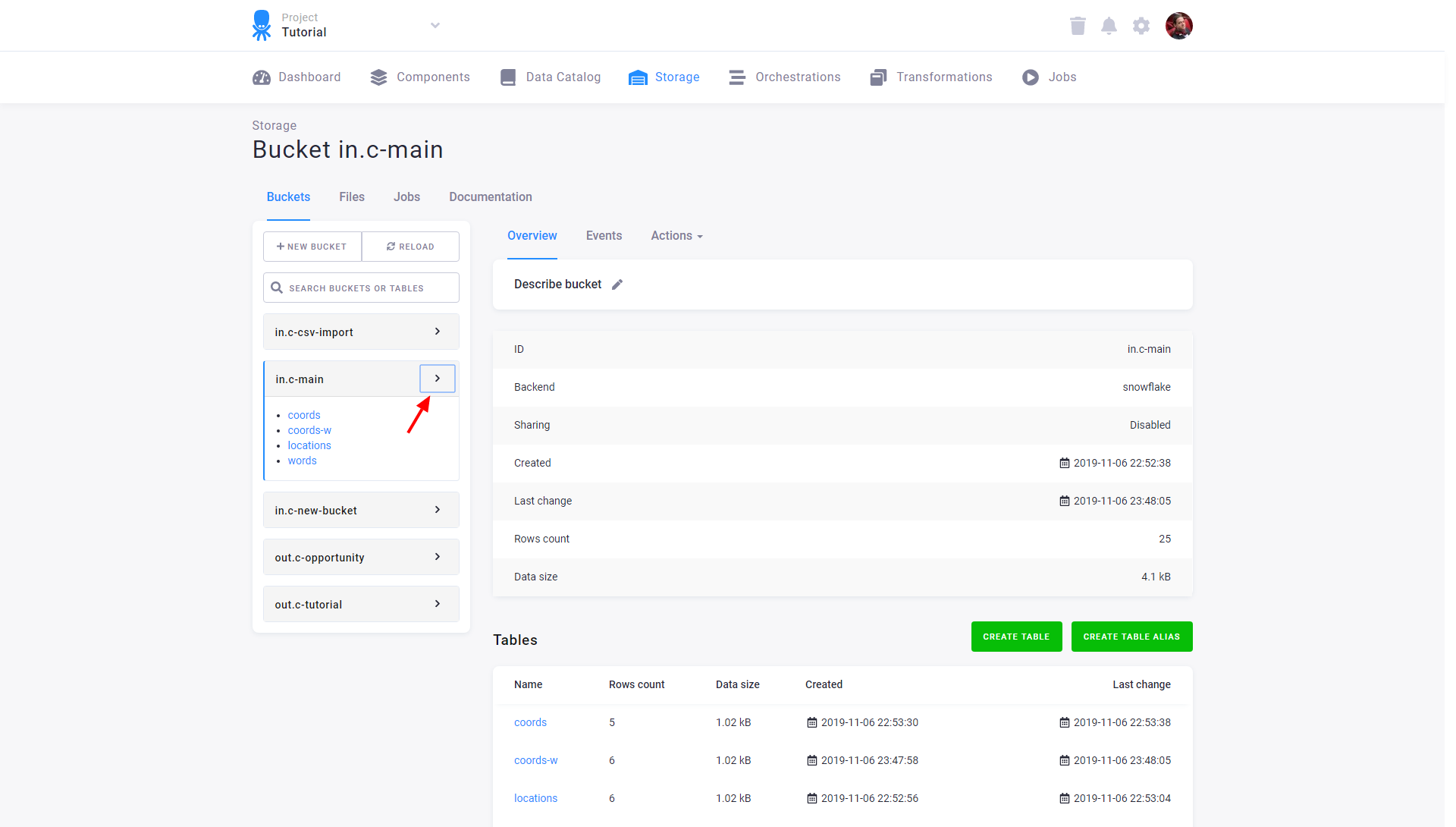
Apart from being used for organizing tables, buckets can also be used for sharing tables.
© 2026 Keboola