Variables
Variables allow you to parametrize transformations. This is useful when you have similar transformations which differ in only a limited number of values. You can have, for example, a transformation that processes all orders from the Meals department. With variables, you can modify it to work for the Drinks department, too.
Variables
Transformation variables are unrelated to the transformation code itself. It means that they do not manifest themselves as SQL or Python variables. Transformation variables are evaluated before the transformation is run and are valid for the entire configuration (all code blocks, shared code, mapping, etc.). Variables are referenced in the configuration using the Moustache Variable syntax.
All variables referenced in the code must be defined in the variables section. All defined variables must have assigned values.
Example
Consider the following transformation:
CREATE OR REPLACE TABLE "result" AS
SELECT "first", "second" * 42 AS "larger_second" FROM "source";To parametrize the multiplier value (42), you can change it to a variable {{ multiplier }}:
CREATE OR REPLACE TABLE "result" AS
SELECT "first", "second" * {{ multiplier }} AS "larger_second" FROM "source";When you define a variable, you have to provide its default value:
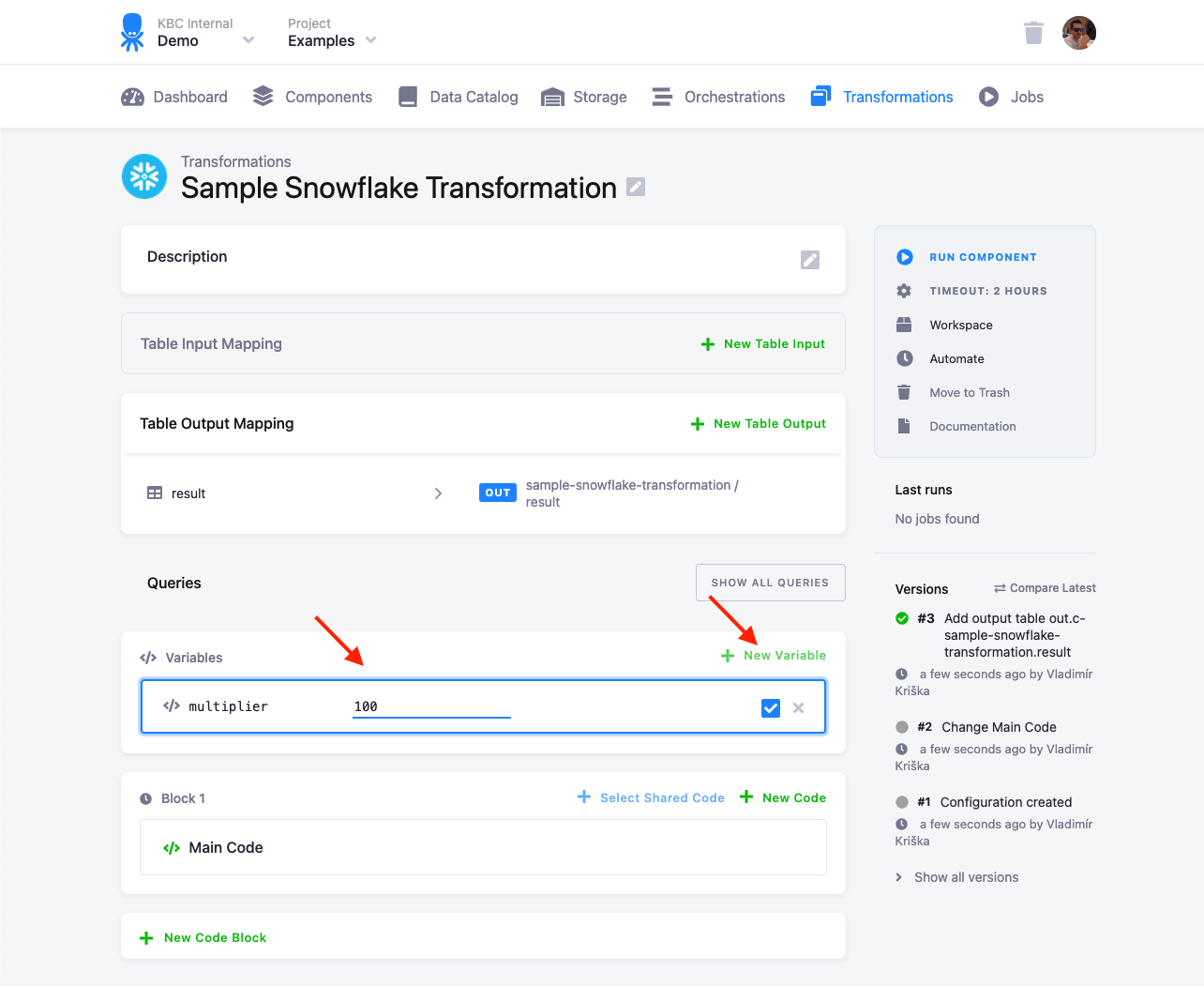
When you run a transformation, you can provide a runtime override of the default value:
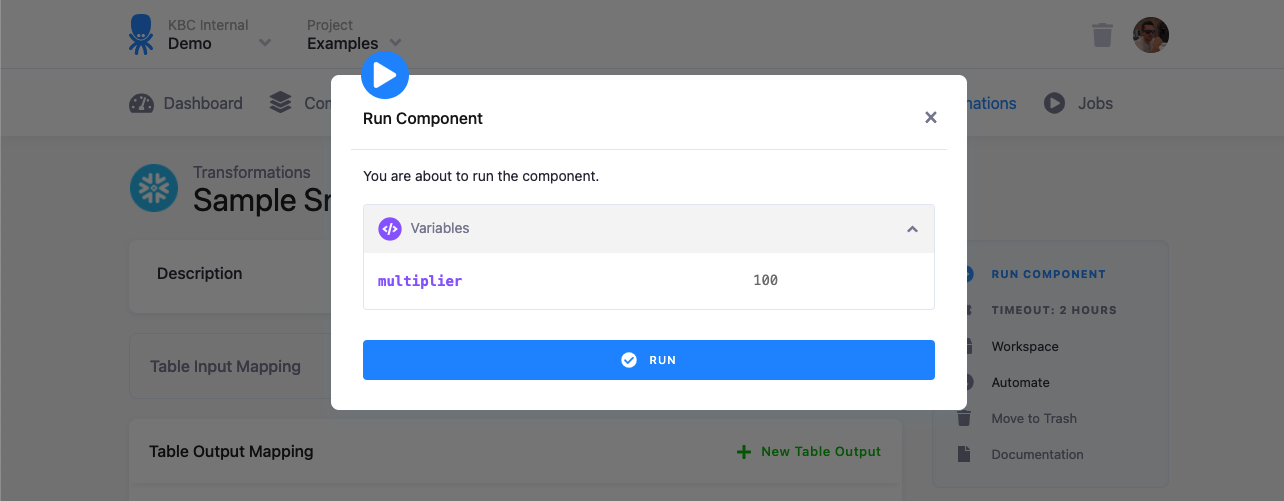
When a variable is referenced in the code but not defined, or its value is missing, you’ll get an error:
Missing values for placeholders: "multiplier"
or
No value provided for variable "multiplier".
Orchestration Usage
When you use orchestrations to automate transformations with variables, you can either rely on the default values, or you can override them for each orchestration task. This can be done by configuration of task parameters:
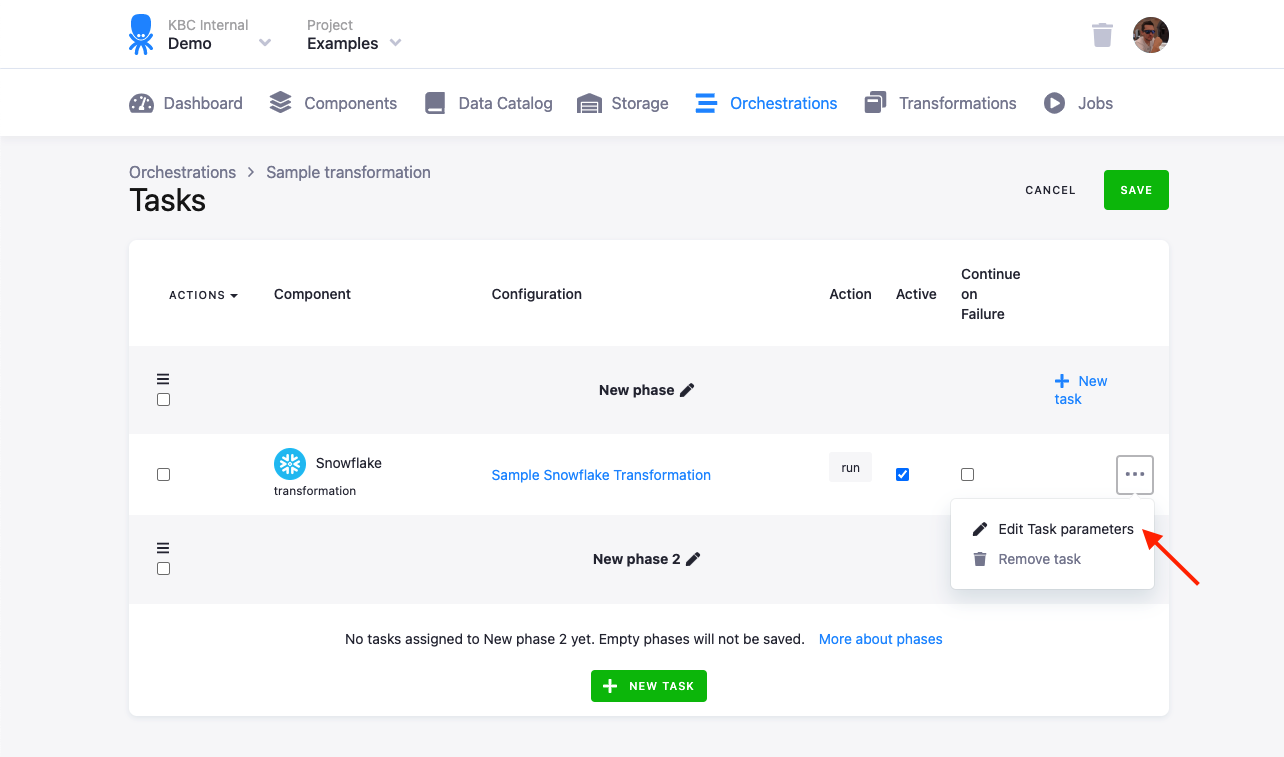
There you can set variable values override:
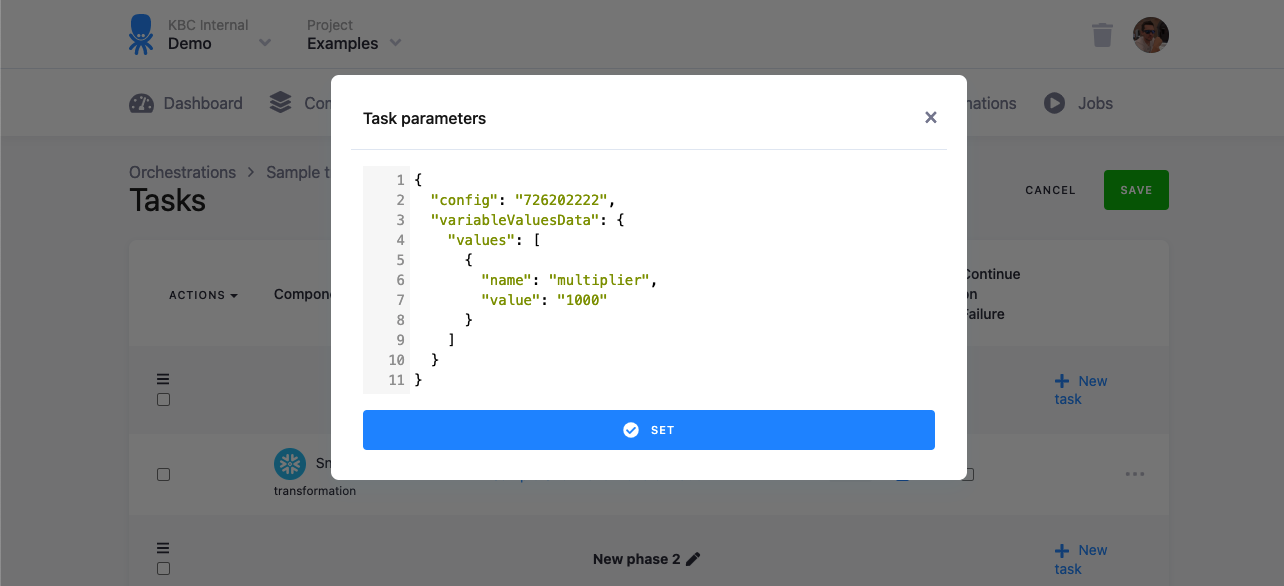
In the above example, you can override the default value by adding the following code to the configuration json:
"variableValuesData": {
"values": [
{
"name": "multiplier",
"value": "1000"
}
]
}The resulting configuration will look similar to this:
{
"config": "6939",
"variableValuesData": {
"values": [
{
"name": "multiplier",
"value": "1000"
}
]
}
}Shared Code
Shared code is slightly related to variables in that it is another option how to make the transformation code more dynamic. Shared code allows you to share pieces of code between otherwise unrelated transformations. Like with the variables, the shared code is evaluated before the transformation runs. This means that it does not interfere with your transformation code.
There are two ways how to create shared code — from the Shared Codes page:
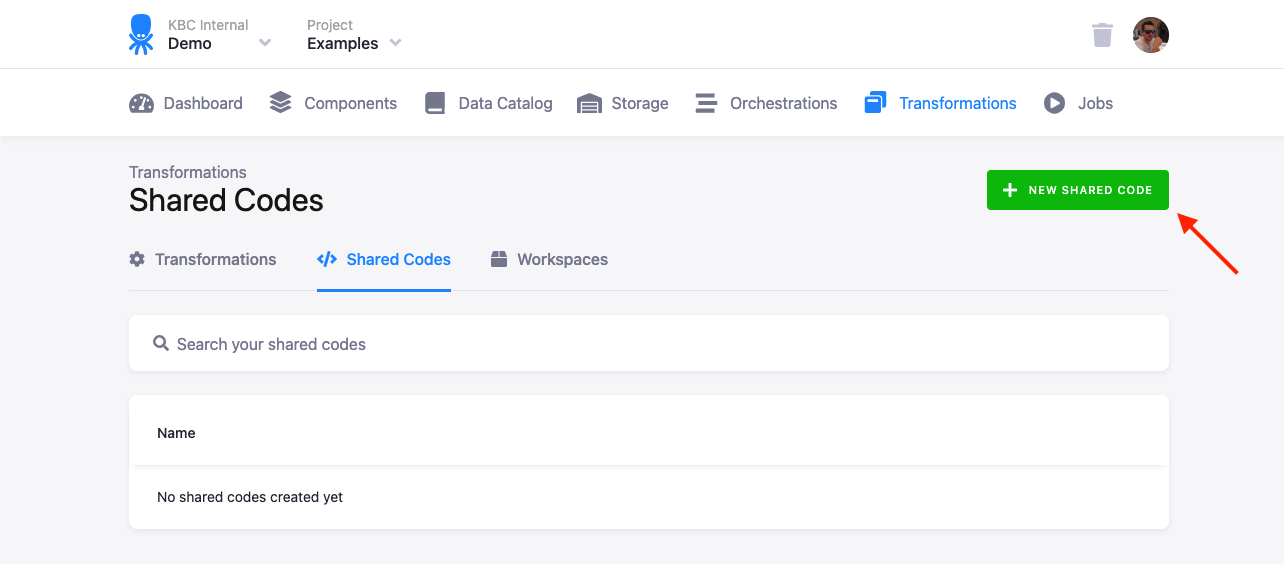
Or from an existing transformation code:
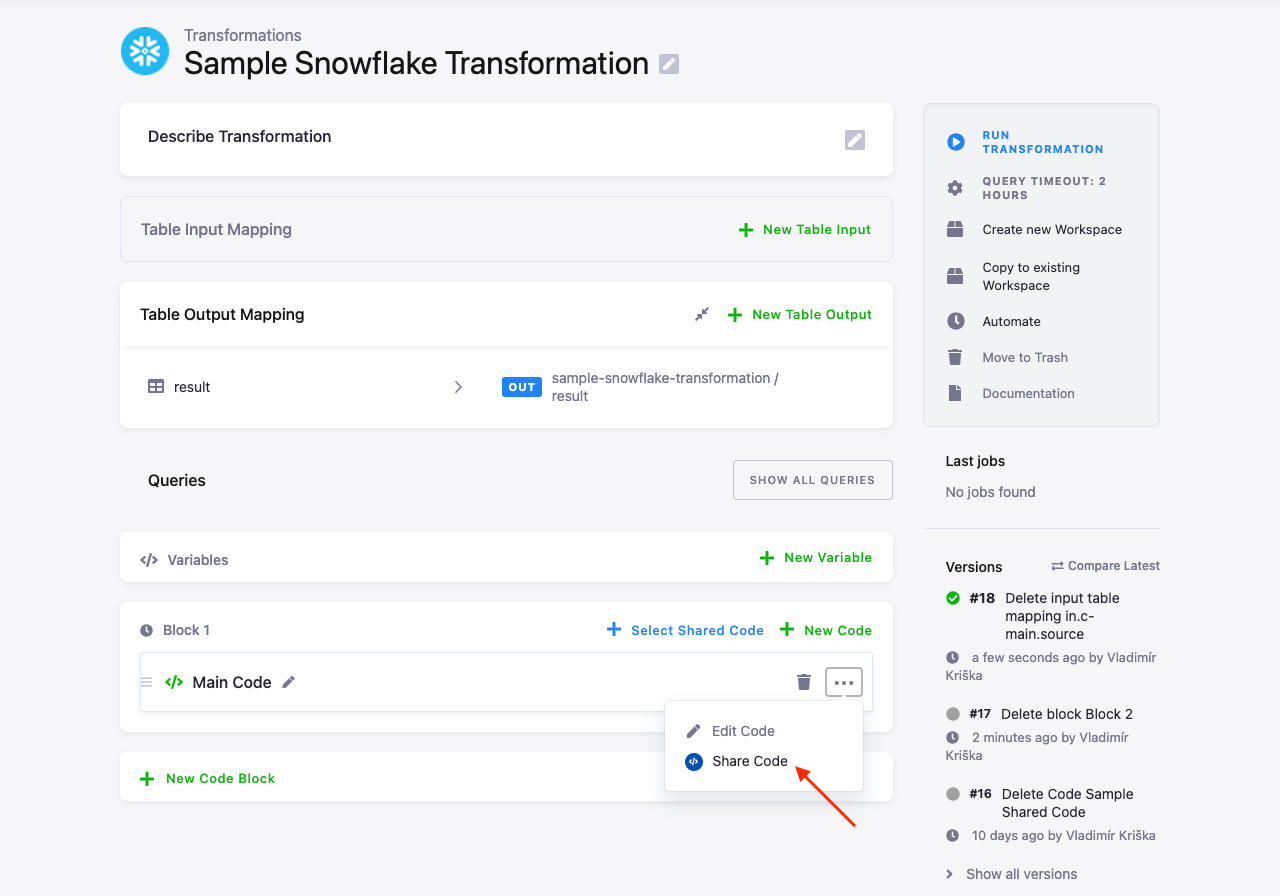
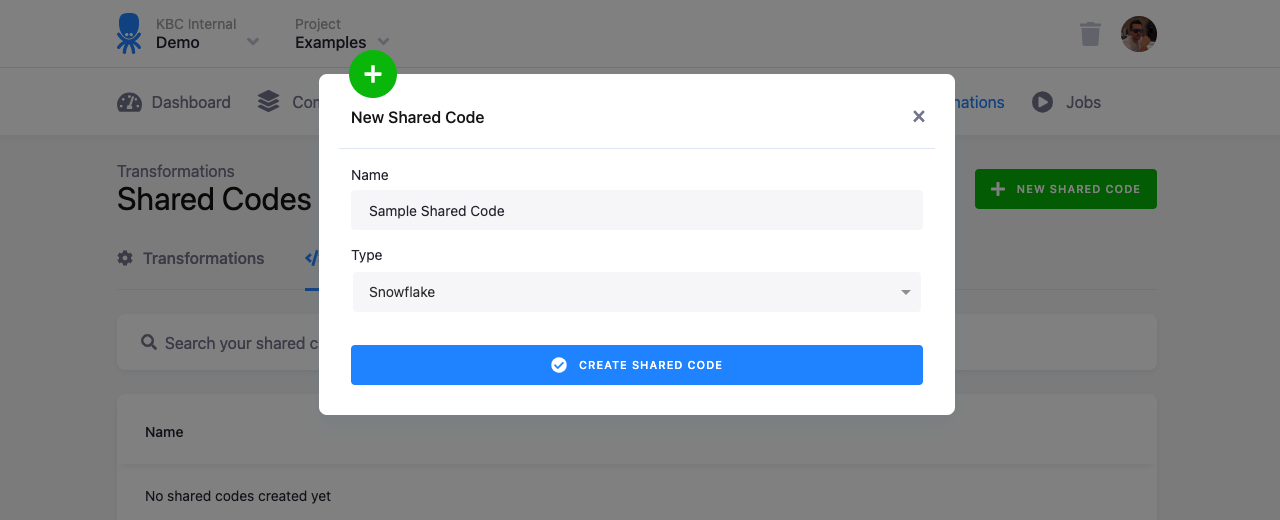
You have to enter the name for the shared code when creating a new one. When you share an existing piece of transformation code, the code and code type are filled in automatically.
Using Shared Code
You can use shared code when editing a transformation:
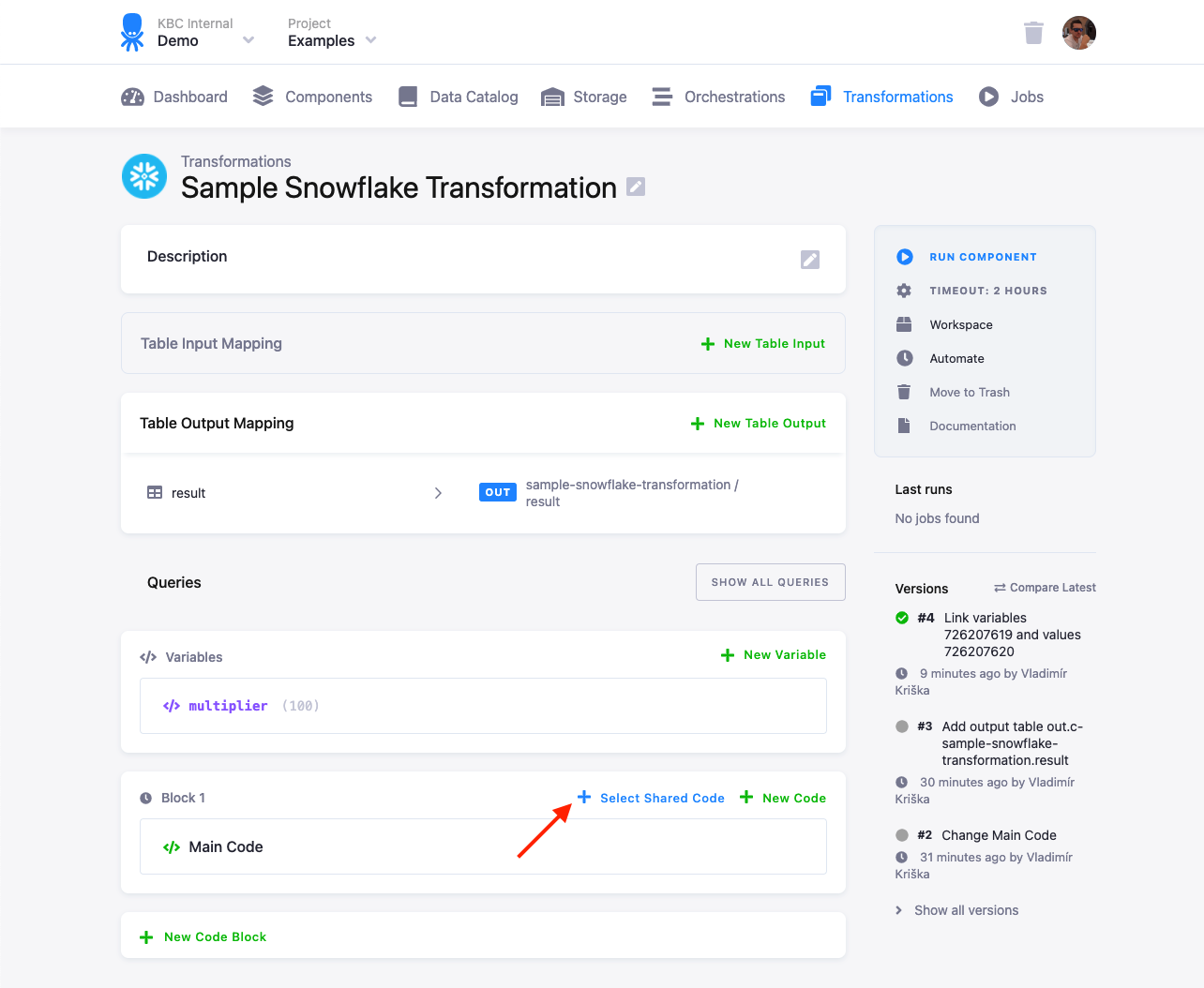
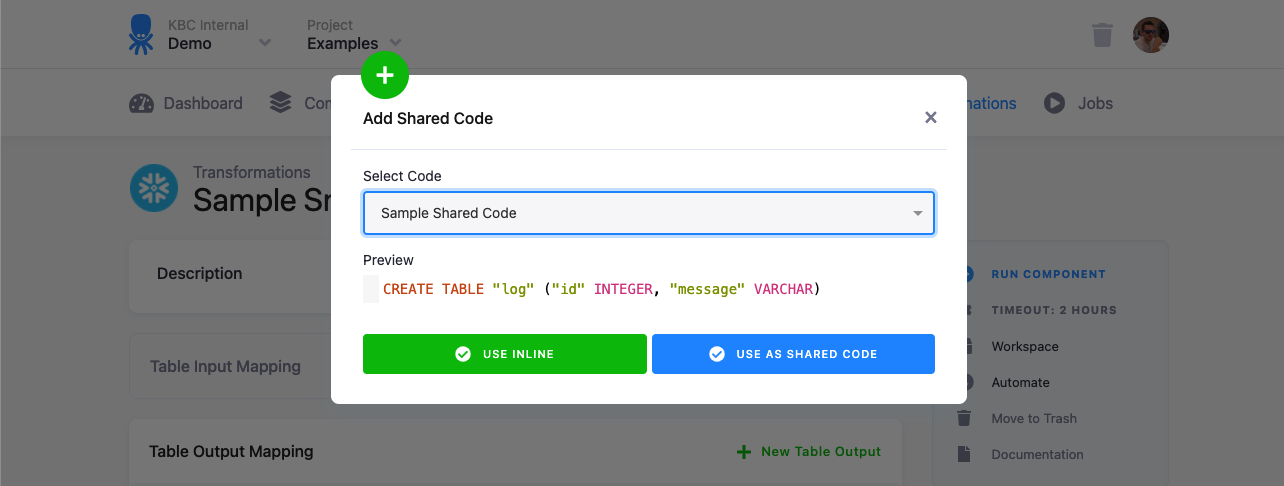
Select the shared code you want to use. There are two options how you can use it:
- Use Inline — This will make a copy of the shared code in the transformation you’re editing. There won’t be any link between the transformation and the shared code.
- Use as Shared Code — This will link the shared code with the transformation. When you modify the shared code, it will affect all linked transformations.
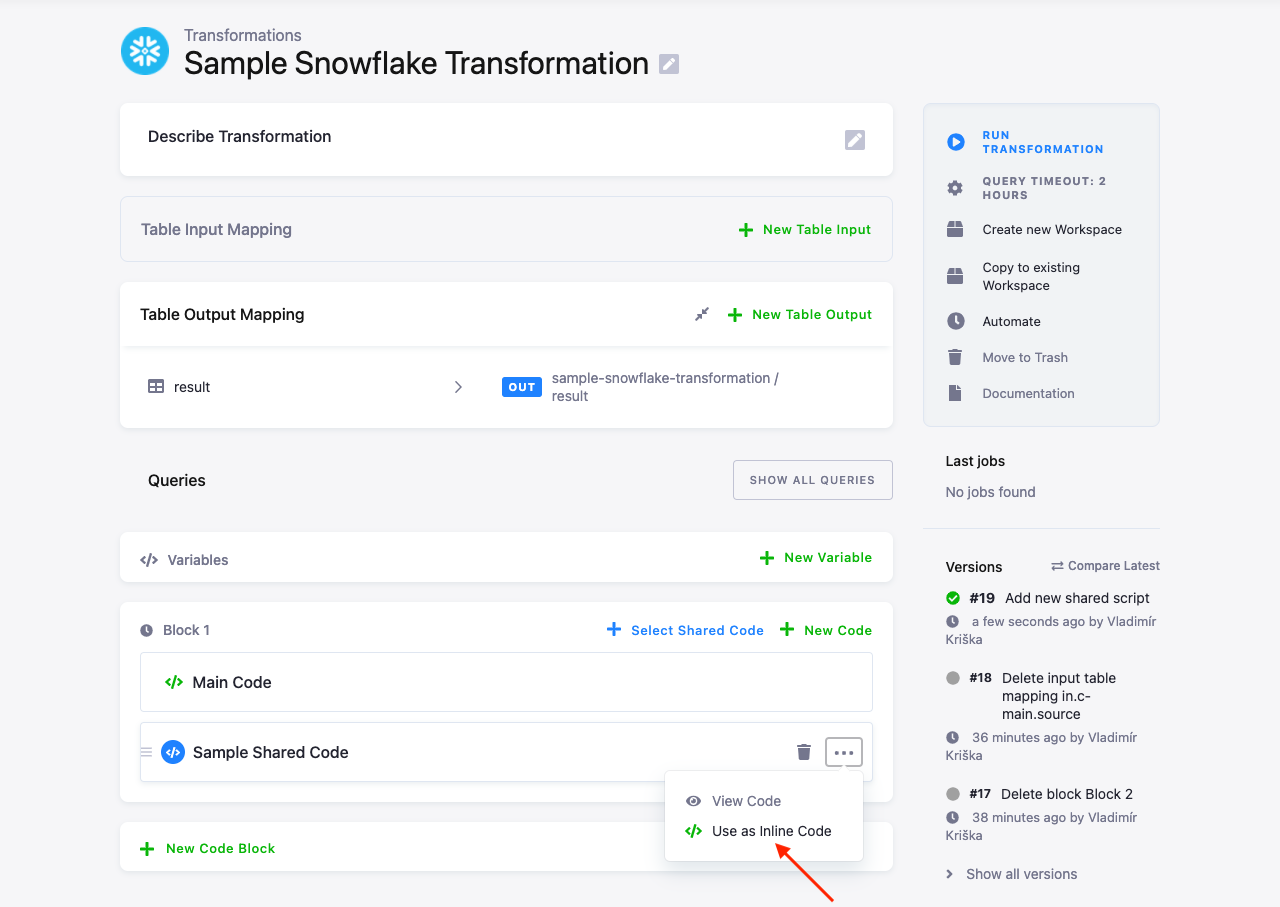
When the code is inserted as shared code, you can always unlink the transformation from the shared code by selecting Use as Inline Code from the dots menu:
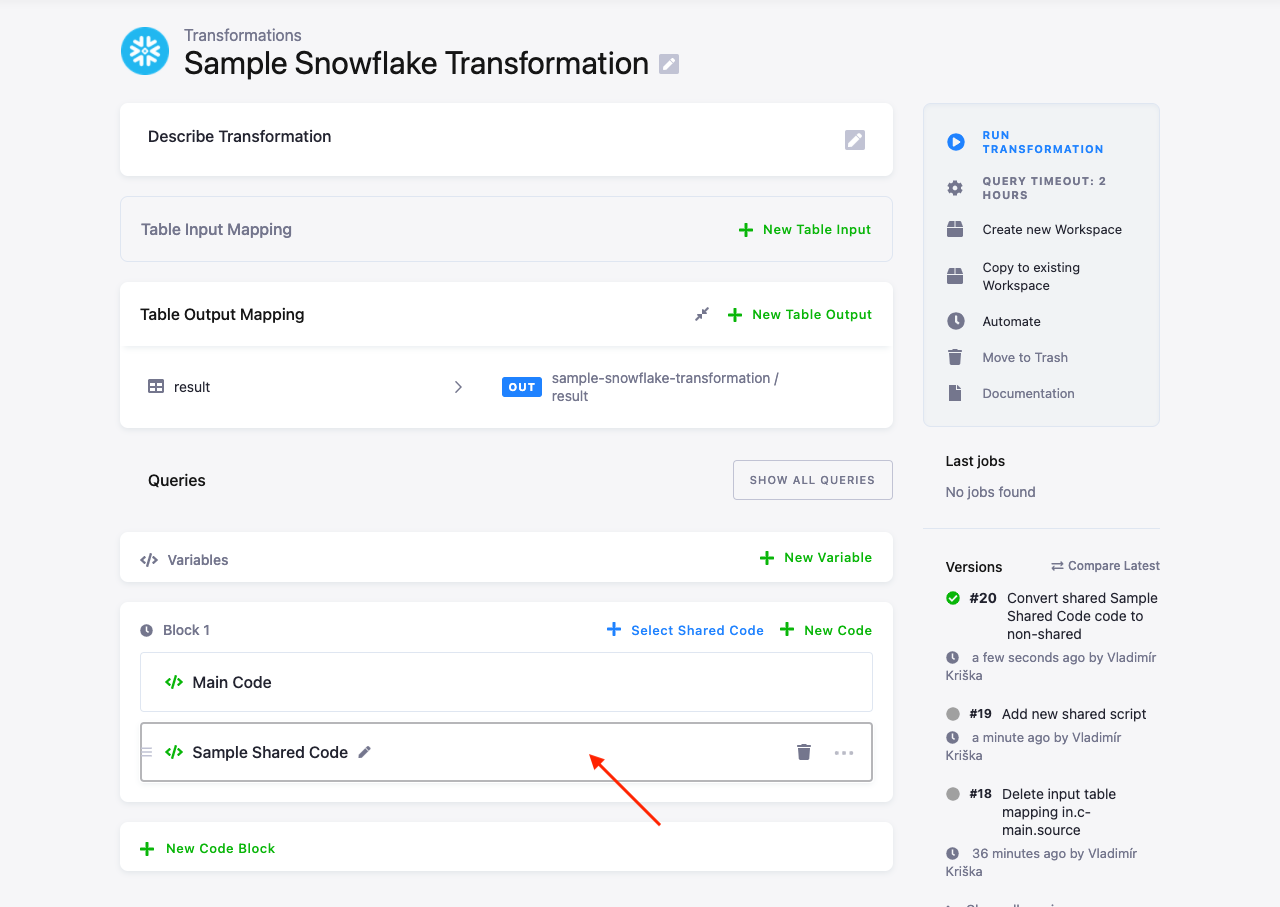
Modifying Shared Code
When a shared code is linked to transformations, you can review its usage in the Usage section on the shared code detail page:
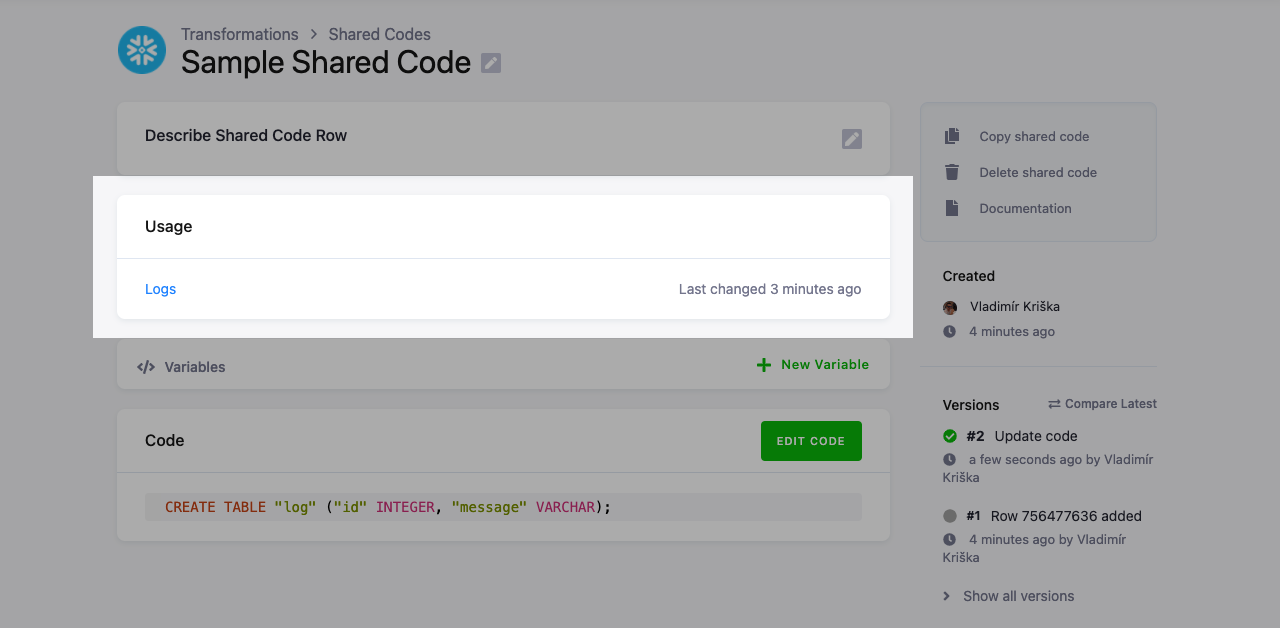
You’ll see a list of transformations to which the shared code is linked. The transformations in which the shared code was used inline are not listed, because there is no link.
When you attempt to edit a shared code, you’ll see a warning that there’s a potential to break the transformations in which it is used.
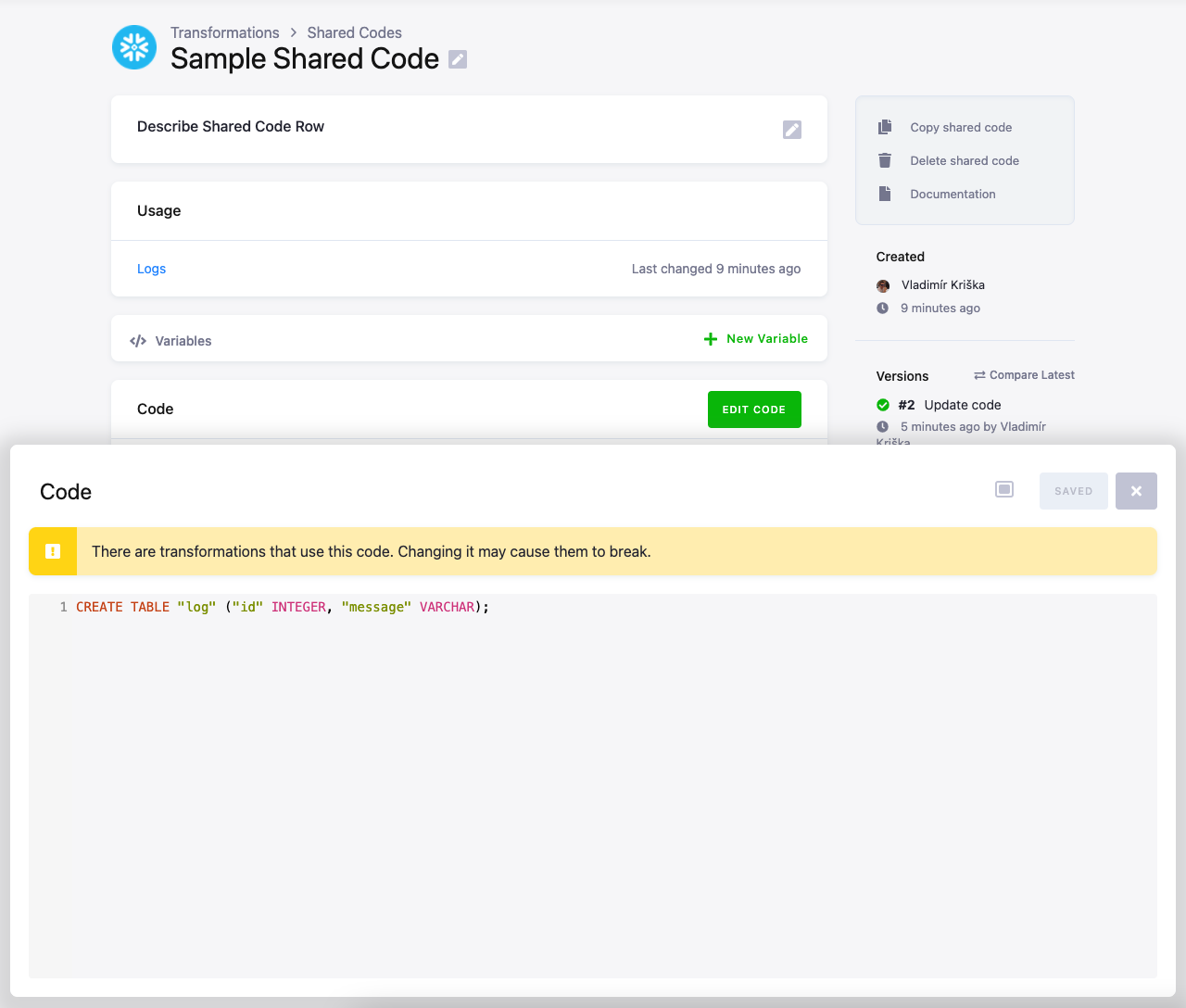
When you try to delete a shared code, you’ll see a list of the transformations which use it. When you delete a shared code that is used, the transformations using it will stop working.
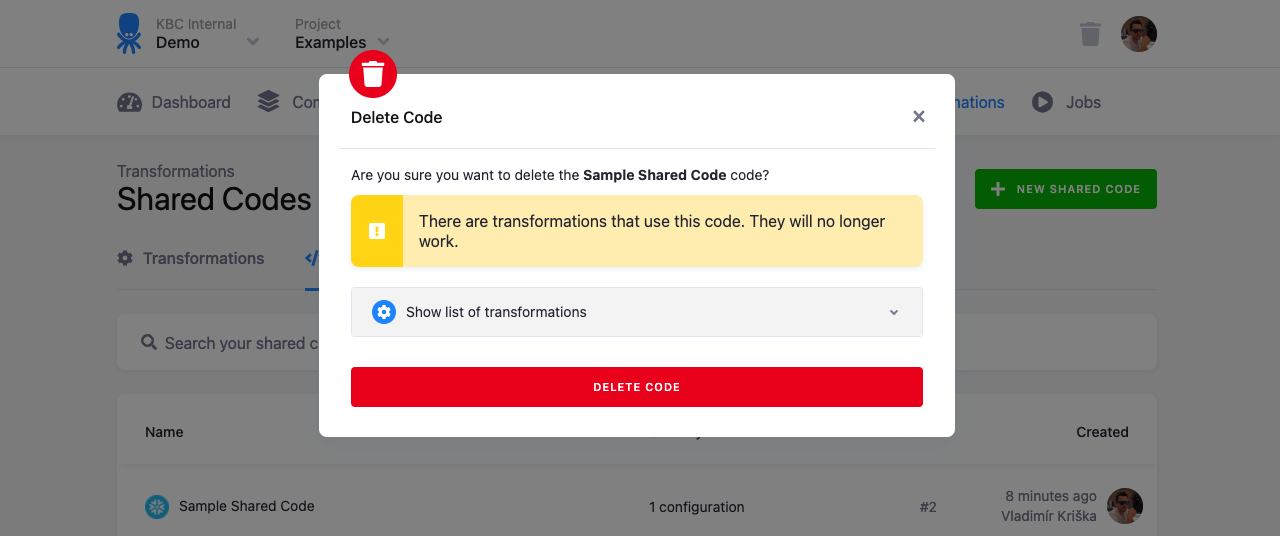
Transformations referencing a deleted shared code fail with a message similar to this:
Shared code configuration cannot be read: Row 10433 not found
Example Using Shared Code
Let’s say that you have a lot of SQL transformations with a table in input mapping that requires some preparation.
For example:
CREATE OR REPLACE TABLE "result" AS
SELECT *, "second" * 42 AS "larger_second" FROM "source";Because of Clone mapping, you have
to drop the _timestamp column from the source by executing this query:
ALTER TABLE "source" DROP COLUMN "_timestamp";If you have many transformations that require the table to be prepared in the same way, you can create the following shared code:
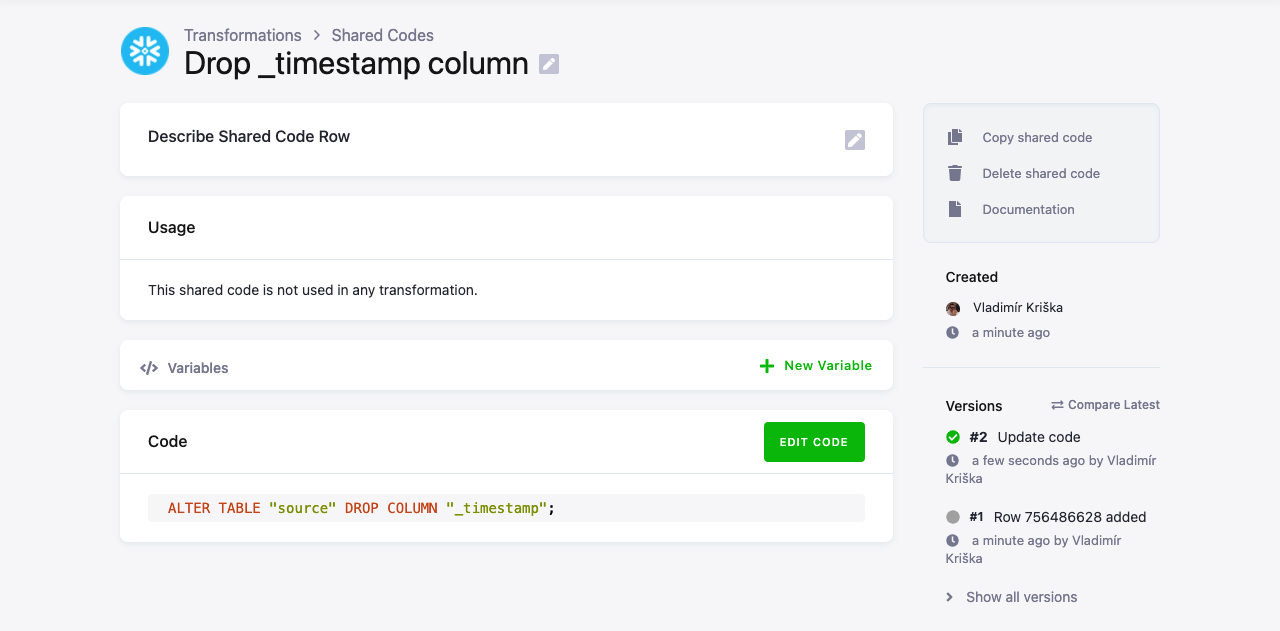
Note: When defining shared code for Snowflake, the shared code can contain only one query.
Important: The SQL query must end with a semicolon ;
Add the shared code to the transformation. Drag & Drop it before the main transformation code:
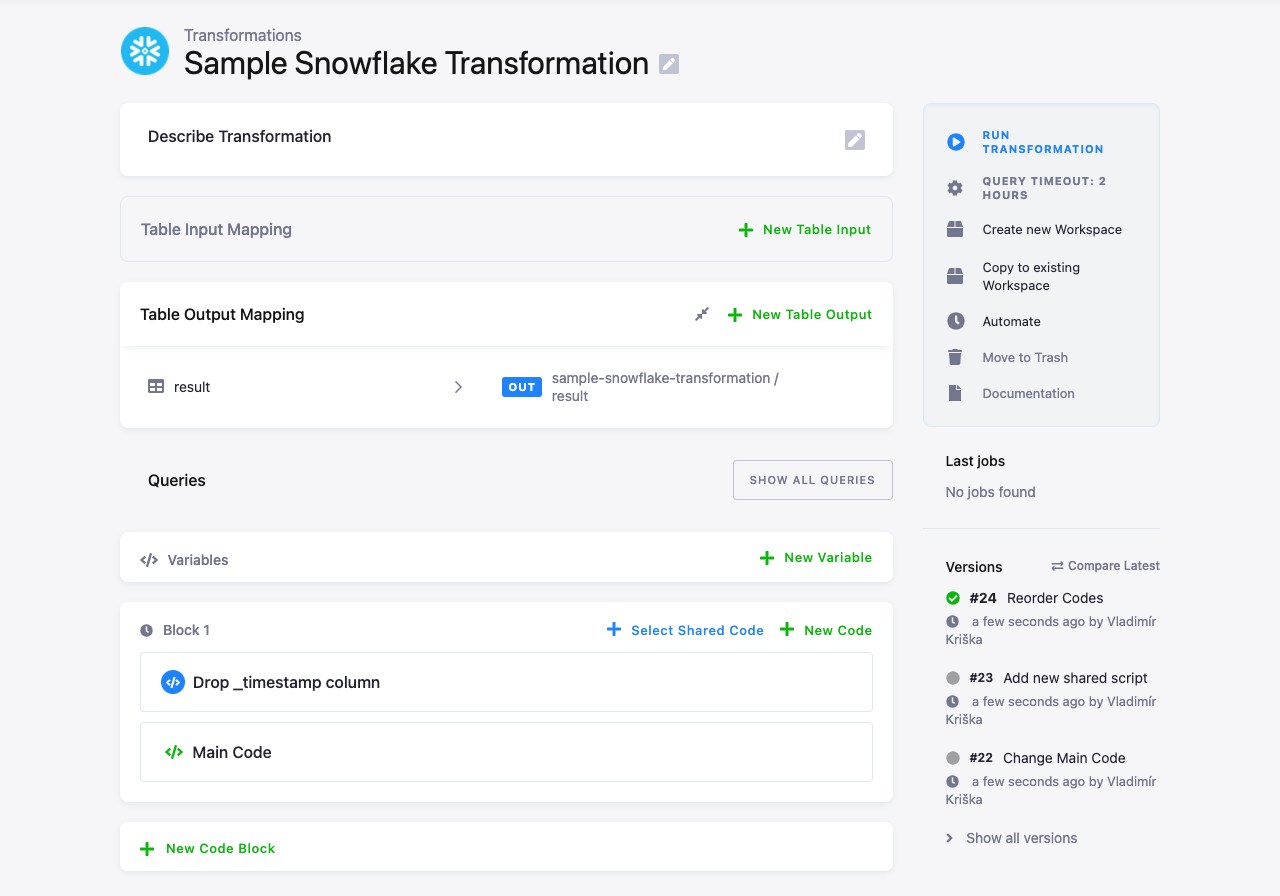
The main code being:
CREATE OR REPLACE TABLE "result" AS
SELECT "first", "second" * 42 AS "larger_second" FROM "source";When you run the transformation, you can see in the events what code has been executed:

Example Shared Code with Variables
You can also define variables for shared code.
For example, we can extend the
above example
and parametrize the name of the table from which the _timestamp column is dropped.
Add the source variable and modify the shared code to:
ALTER TABLE "{{source}}" DROP COLUMN "_timestamp"; 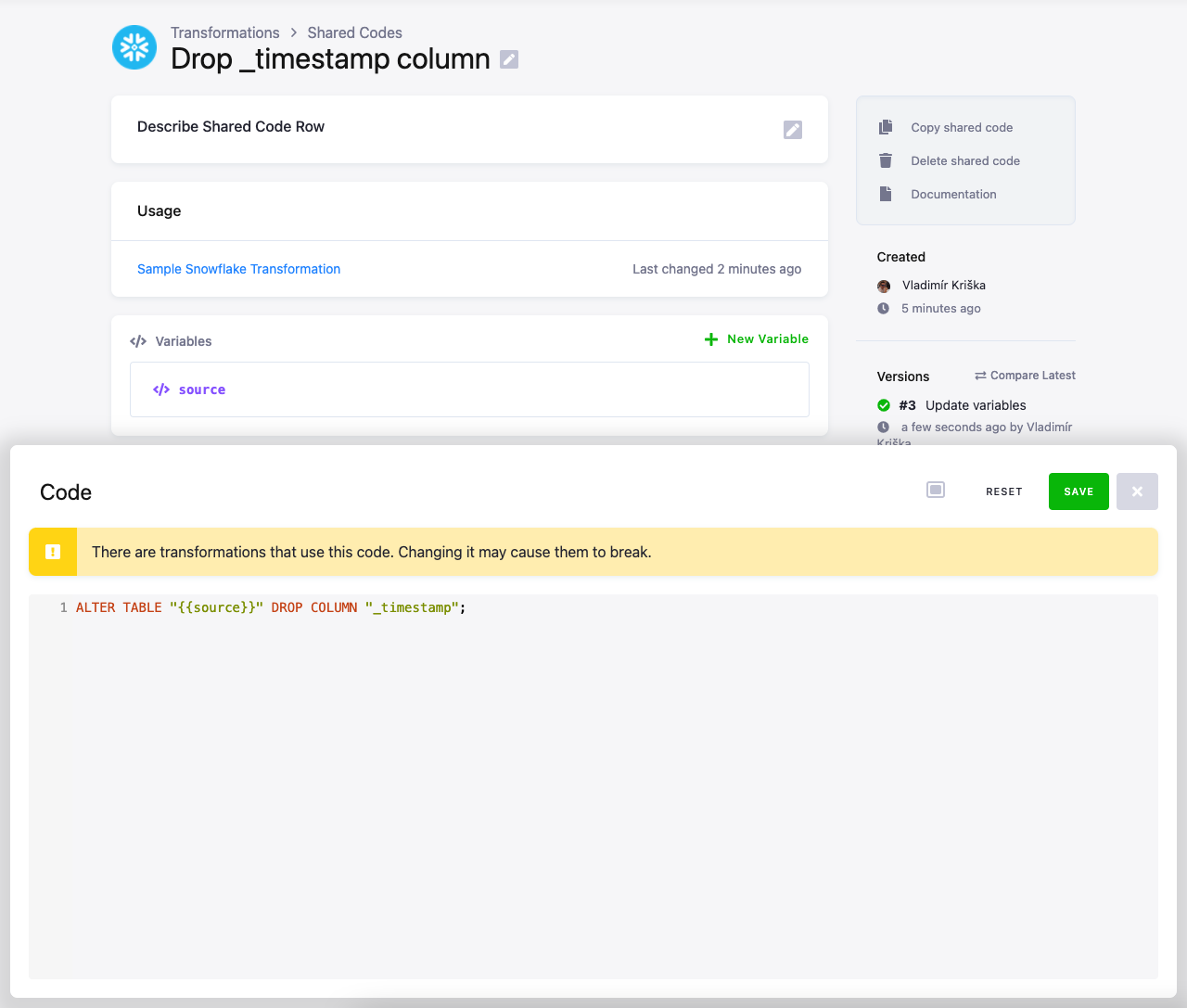
The transformation will detect that the value for the source variable is not defined:
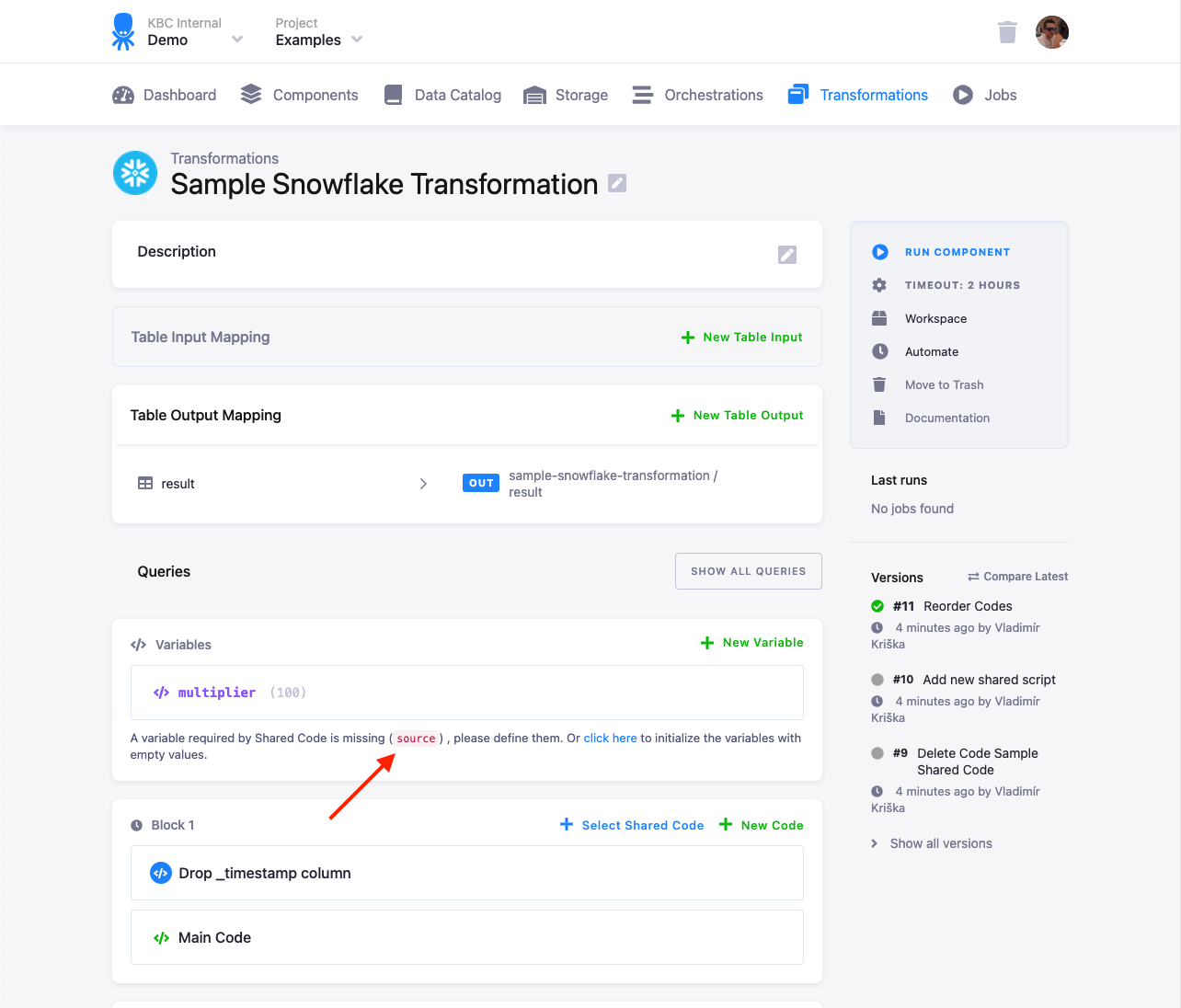
Set the source value to the destination name of the
table in the Table Input Mapping (source-table in this case):
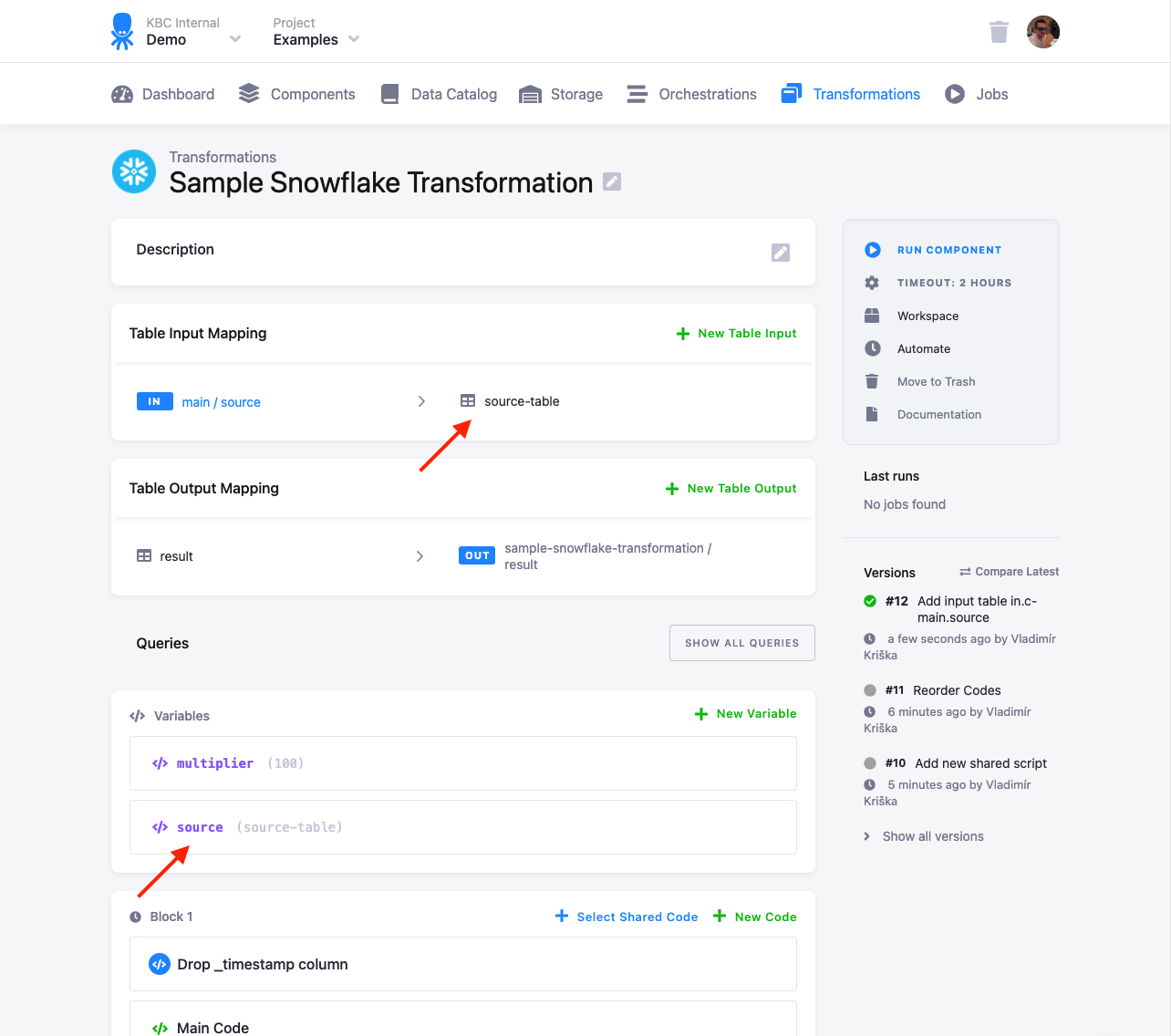
When you run the transformation, you can verify the executed queries in the job events. There
you can see that the shared code query manipulated the source-table:
