Native Data Types
The Native Data Types feature streamlines the process of propagating data types from the source to the storage. With Keboola Native Data Types, the system automatically maintains data types throughout the pipeline, eliminating the need for manual intervention and reducing errors in data processing.
For example, when a user imports a large dataset with predefined data types, such as NUMERIC, BOOLEAN, and DATE, these types are preserved automatically. Without Native Data Types, the data would have been imported as VARCHAR, requiring the user to manually update the types in transformation.
Non-typed tables without native data types are labeled in the UI with a badge: non-typed.
Key Benefits
These are the key benefits of using the Native Data Types feature:
- Automatic Data Type Preservation: Data types from the source are automatically respected, reducing the need for manual adjustments in Storage.
- Faster Data Handling: Native data types enable more efficient data manipulation, as well as faster loading and unloading, improving overall performance.
- Simplified Transformations: Read-only data access eliminates the need for casting, making data operations smoother and more streamlined.
- Flexible Configurations: Users can decide whether data types should be automatically fetched for each configuration when creating a table.
- Improved Workspace Loading: Loading data into a workspace is significantly faster than loading into a table without native data types, eliminating the need for additional casting.
- Typed Columns in Workspaces: Tables accessed in a workspace via the read-only input mapping already have typed columns, ensuring seamless data handling.
Current Drawbacks
Using the Native Data Types feature also has its drawbacks:
- Data types in typed tables cannot be modified after creation. To change the data types, you must recreate the table. This limitation applies to both the UI and the API. See How to Change Column Types.
- Keboola does not perform any type conversion during data loading. Your data must exactly match the column type defined in the table within Storage.
- Loading data with incompatible types will result in a failure.
How It Works
By default, all new tables are created as typed tables if the component supports this feature. Non-typed tables are labeled in the Storage UI with the label NON-TYPED.
You can configure the data type behavior in the UI component configuration settings. If the component supports this feature, you will see the option Automatic data types in the right menu, which can be toggled ON and OFF.
- When enabled: The component creates a typed table that respects the data types from the source (e.g., DATETIME, BOOLEAN).
- When disabled: A typed table is created with all columns as VARCHAR, and data types are stored as metadata.
In transformations, this option is not available. Instead, you define the data types in your query (if you need the table to be typed). If no types are defined, the table will default to storing data in VARCHAR format.
Important: Existing tables will not be affected by this feature. Also, if you do not see the Automatic data types option in the sidebar, it means the component does not support this feature.
How to Create a Typed Table
The Native Data Types feature allows tables to be created with data types that match the original source or storage backend. Here’s how you can create typed tables:
- Manually via API
You can manually create typed tables using the tables-definition endpoint. Ensure that the data types align with the storage backend (e.g., Snowflake, BigQuery) used in your project. Alternatively, base types can be used for compatibility. - Using a Component
Extractors and transformations that match the storage backend (e.g., Snowflake SQL transformation on a Snowflake storage backend) will automatically create typed tables in Storage:- Matching Storage Backend: Database extractors and transformations create storage tables using the same data types as the backend.
- Mismatching Storage Backend: Extractors use base types to ensure compatibility. Learn more.
To avoid this limitation, follow the steps below.
To avoid the limitation:
- Manually create the table in advance using the Table Definition API, specifying the correct lengths and precisions.
- Subsequent jobs writing data to this table will respect your defined schema as long as it matches the expected structure.
- Be cautious when dropping and recreating tables. If a job creates a table, it will default to the base type with backend-specific defaults, which might not align with your source.
Example:
To ensure typed tables are imported correctly into Storage, define your table in a Snowflake SQL transformation, adhering to the desired schema and data types:

Base Types
Source data types are mapped to a destination using a base type. The current base types are STRING, INTEGER, NUMERIC, FLOAT, BOOLEAN, DATE, and TIMESTAMP. For example, a MySQL extractor may store a column with the data type BIGINT. This type is mapped to the INTEGER base type, ensuring high interoperability between components.
For detailed mappings, please refer to the conversion table. You can also view the extracted data types in the storage table detail.
How to Define Data Types
Using actual data types of the storage backend
For example, in the case of Snowflake, you can create a column with a specific type like TIMESTAMP_NTZ or DECIMAL(20,2). This approach allows you to define all details of the data type, including precision and scale. An example of such a column definition in a table-definition API endpoint call might look like this:
{
"name": "id",
"definition": {
"type": "DECIMAL",
"length": "20,2",
"nullable": false,
"default": "999"
}
}
Using Keboola-provided base types
Specifying native types using Keboola’s base types is ideal for component-provided types, as these are storage backend agnostic. This method ensures compatibility across different storage backends. Additionally, base types can also be used when defining tables via the table-definition API endpoint. The definition format is as follows:
{
"name": "id",
"basetype": "NUMERIC"
}
Changing Types of Existing Typed Columns
You cannot change the type of a column in a typed table once it has been created. However, there are multiple workarounds to address this limitation:
For tables using full load: Drop the table and create a new one with the correct types. Then, load the data into the newly created table.
For tables loaded incrementally: You will need to create a new column with the desired type and migrate the data step by step:
- Assume you have a column
dateof typeVARCHARin a typed table, and you want to change it toTIMESTAMP. - Start by adding a new column named
date_timestampof typeTIMESTAMPto the table. - Update all jobs filling the table to populate both the new column (
date_timestamp) and the existing column (date). - Run an ad-hoc transformation to copy data from
datetodate_timestampfor the existing rows. - Gradually update all configurations and references to use
date_timestampinstead ofdate. - Once all references are updated and the old column is no longer in use, you can safely remove the
datecolumn.
How to Create a Typed Table Based on a Non-Typed Table
If you have a non-typed table, non_typed_table, with undefined data types and want to convert it into a typed table, follow these steps:
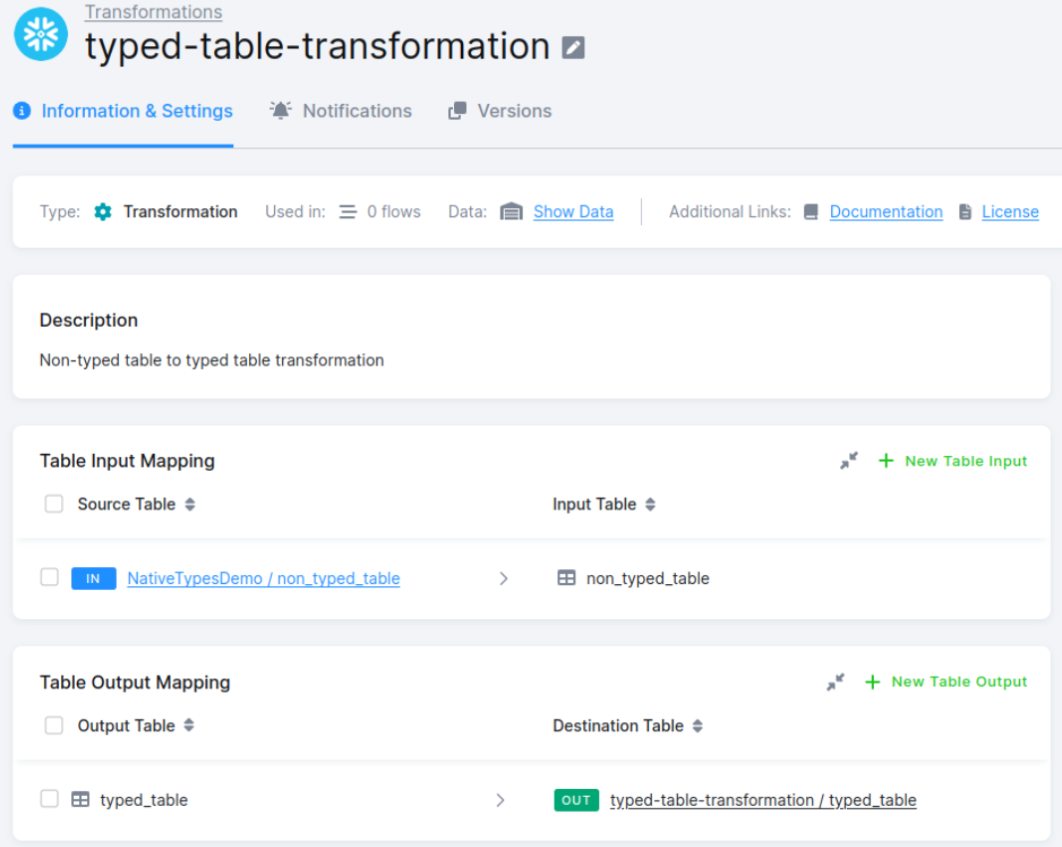
Step 1: Set Up the Transformation
- Create a new transformation in Keboola.
- Choose
non_typed_tableas the input table in the input mapping section (you can also rely on read-only input mapping). - In the output mapping section, define the output table as
typed_table. Ensure that the output table does not exist; otherwise, it will not be created as a typed table.
Step 2: Define the Query
In the queries section, write an SQL query to transform the column types. Use proper casting for each column to match the desired data types.
For example, if you need to format a date column, include the appropriate SQL casting or formatting function in your query.
CREATE TABLE "typed_table" AS
SELECT
CAST(ntt."id" AS VARCHAR(64)) AS "id",
CAST(ntt."id_profile" AS INTEGER) AS "id_profile",
TO_TIMESTAMP(ntt."date", 'DD.MM.YYYY"T"HH24:MI:SS') AS "date",
CAST(ntt."amount" AS INTEGER) AS "amount"
FROM "non_typed_table" AS ntt;
Step 3: Run the Transformation
Execute the transformation and wait for it to complete.
Step 4: Verify the Schema
Once the transformation is finished, check the schema of the newly created table, typed_table. It should now include the appropriate data types.
Note: Incremental loading cannot be used when creating a typed table in this manner.
Incremental Loading
The behavior of incremental loading differs between typed and non-typed tables:
- Typed tables: Only the columns in the table’s primary key are compared to detect changes.
- Non-typed tables: The entire row is compared, and rows are updated if any value has changed.
For more information, refer to our documentation on incremental loading.
Handling NULLs
Data can contain NULL values or empty strings, which are converted differently based on the processing backend, as follows:
- Snowflake:
,,=>NULLor""=>NULL - BigQuery:
,,=>NULLand""=>""
Columns without native types are always VARCHAR NOT NULL. This means you don’t need to worry about specific NULL behavior. However, this changes with typed columns.
In most databases, NULL does not equal NULL (NULL == NULL is not TRUE, but NULL). This behavior can disrupt the incremental loading process, where columns are compared to detect changes.
To avoid such issues, ensure that your primary key columns are not nullable. This is especially relevant in CTAS (Create Table As Select) queries, where columns are nullable by default. To address this, explicitly define the columns as non-nullable in the CTAS expression. For example:
CREATE TABLE "ctas_table" (
"id" NUMBER NOT NULL,
"name" VARCHAR(255) NOT NULL,
"created_at" TIMESTAMP_NTZ NOT NULL
) AS SELECT * FROM "typed_table";