Flows
- What Is the Flow Builder?
- Access the Flow Builder
- Build the Flow
- Schedule and Automate
- Check Run History
If you already know how flows work in general and want to create your first flow, go to our Getting Started tutorial.
For useful tips, check out our cheat sheet with best practices.
Flows integrate all of your project’s segments (data connectors, transformations, other flows, etc.) by creating custom automated processes, chaining components to be run in a specific order, and defining the execution schedule to bring in the newest data available.
First, you need to decide what exactly you want your flow to do, meaning what tasks should be executed. Then, you decide in what order you want them to run. And finally, you will determine when you want the entire flow to be executed and how often. Notifications are available to help you monitor the entire process.
What Is the Flow Builder?
Using the Flow Builder feature, you can create data flows by dragging and dropping the components together on a single screen. Even scheduling and automating your data pipelines takes just a few button clicks.
The flow builder enables you to do the following:
- View your multi-step data pipeline in a single browser window, which is especially helpful when your data pipeline is complex.
- Create your flows with no data engineering skills.
- Collaborate on the same data flows, set up the data pipeline as a team, and continue working on different components individually. The in-built version control lets your team see the changes others have made over time.
- Build multiple data flows in a single view. Each flow is its own data pipeline.
- Copy-and-paste an existing data flow to a new flow to reuse the work done across different data pipelines.
Let us show you how to organize individual tasks into steps, set up notifications, and schedule the execution of your flow:
- Access the Flow Builder
- Build the flow
- Schedule and automate your flow
- Set up notifications
- Check how your flow is running
Access the Flow Builder
Select from the top menu Flows -> Flows and click the Create Flow button.
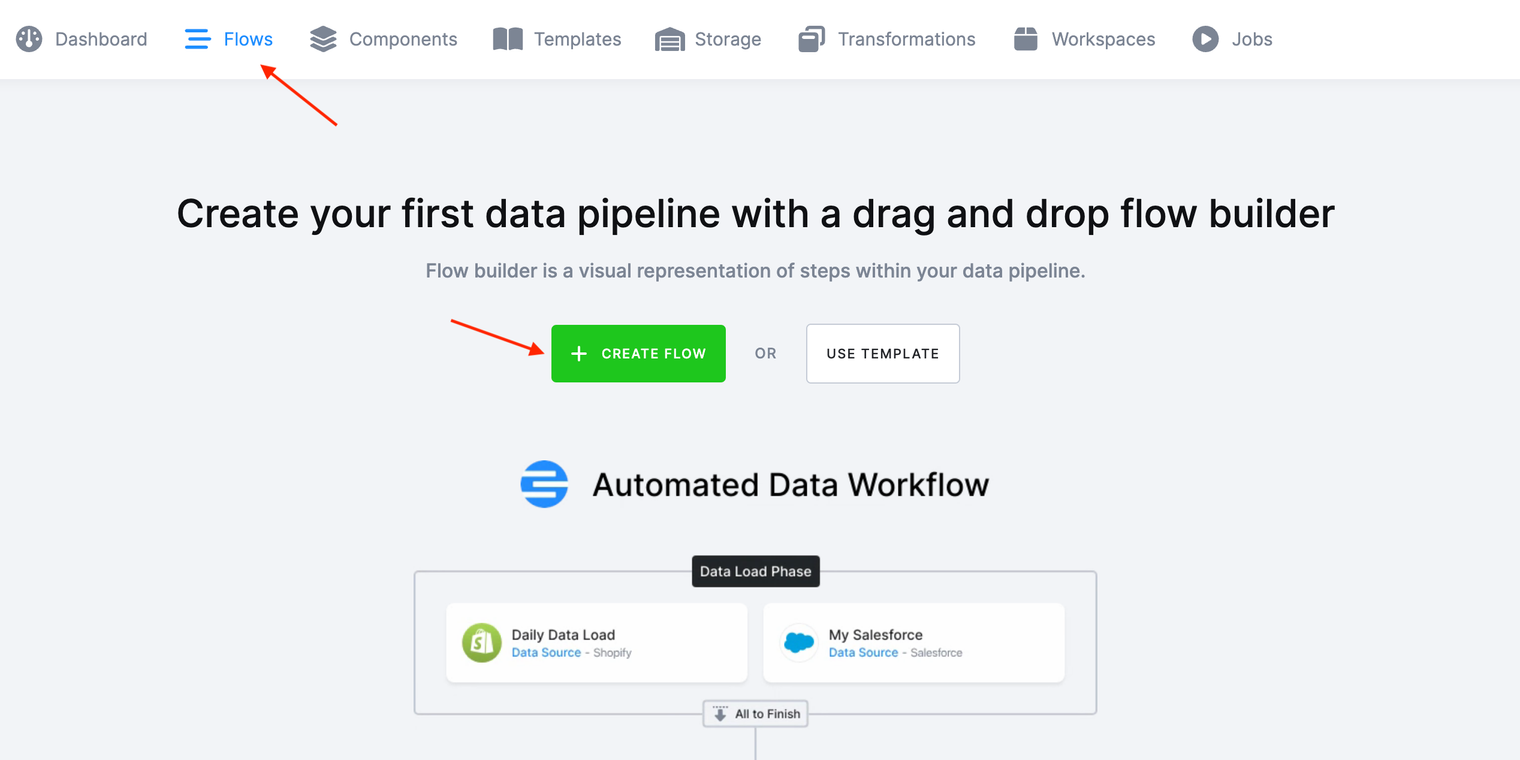
Name your new flow and add an easy to understand description. Then click Create Flow again.
This will open up the flow builder view, where you can create your data flow.
Build the Flow
Click Select first step and start selecting the components that will bring in data from your selected data sources. Use the drop-down menu to select a particular configuration of the component.
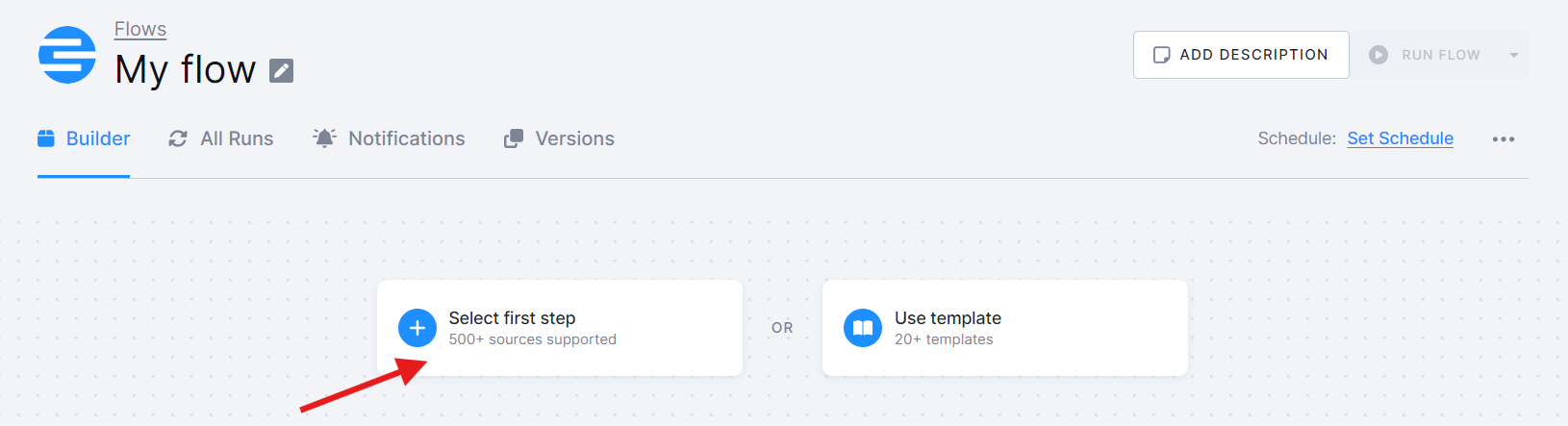
Use the plus icon to add other steps.
Typically, the flow starts with data source connectors, or, if all the tables you need are already in the project, it starts with transformations. To load your transformed data into your selected data destination, add one or more data destination connectors.
Continue adding other ready-made components and organize them in a logical flow using the drag-and-drop functionality.
Then configure each component by providing the credentials and instructions for what or where to extract or write or for what code to execute in a transformation.
Remember to adjust the input mapping of your transformation(s) to use the tables extracted from your selected data sources if necessary. Select the step and click Edit Configuration.
Click Save.
Execute Tasks in Parallel
You can group multiple tasks within one step, a phase. These tasks then run independently in parallel, speeding up the execution. Steps execute sequentially, while tasks within a single step run in parallel. If you have multiple data source connectors, you can include them all in a single step, allowing them to run simultaneously.
The same applies to data destination connectors. Also, transformations independent of the connectors can be grouped within the same step. Note that this does not reduce costs, as each job consume credits independently.
You can also set up parallelization within a component (configuration), directly in the component’s UI for row-based components like database source connectors using the same credentials to run multiple tables concurrently.
Warning: If too many tasks are scheduled in a single phase, you may exceed the available Storage job slots, causing delays in your flow’s execution. Limiting the number of concurrent component jobs to 10 is recommended to avoid reaching Storage capacity limits. You can, of course, configure your flows to execute more jobs in parallel. Keboola will then concurrently execute the jobs to the maximum extent possible based on available resources.
Storage jobs have a parallel limit. They are typically capped at 10 parallel jobs but the Keboola Support team can help you adjust this.
Control Task Execution
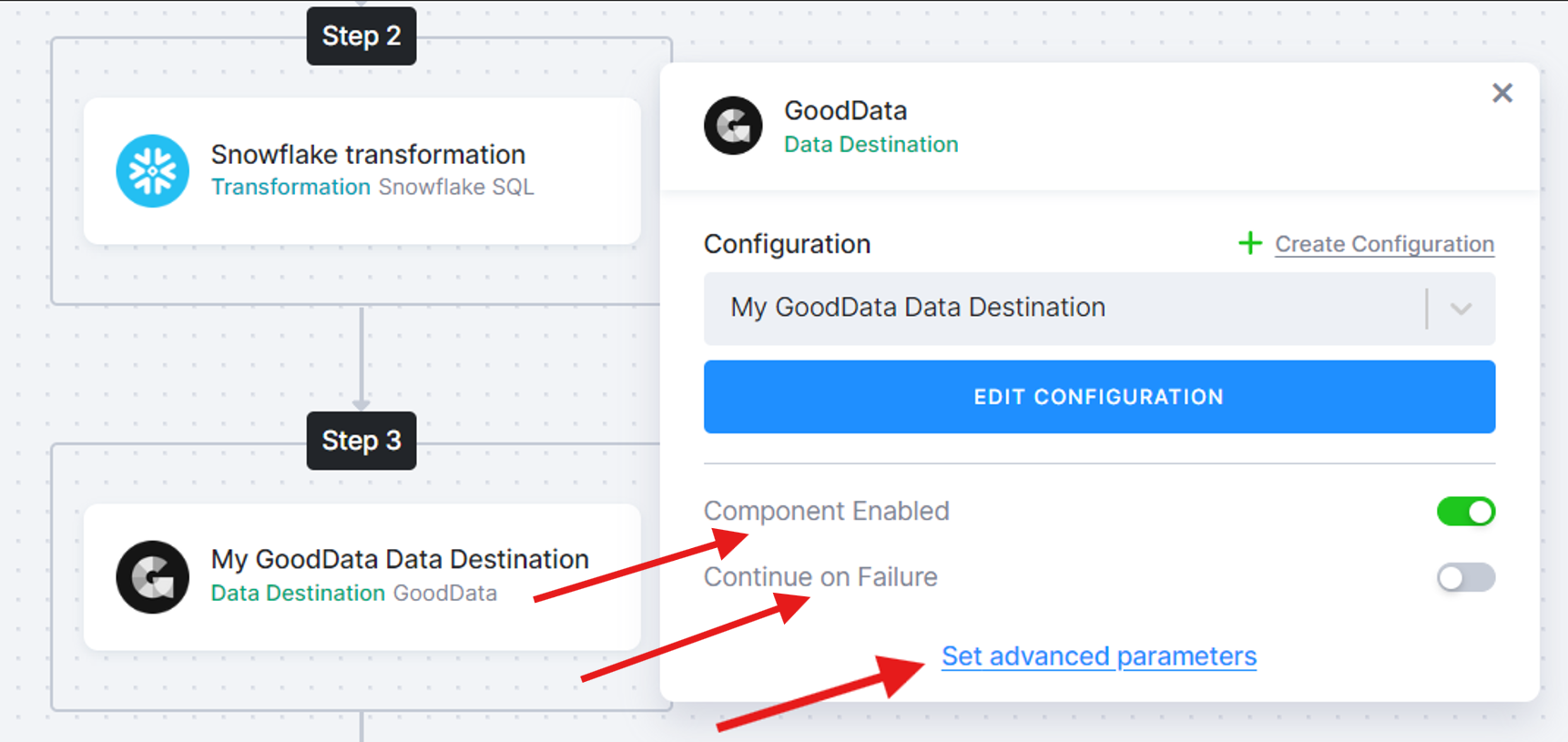
-
If you need to temporarily skip something, activate the Component Enabled flag. The task will then be excluded from the flow.
-
If you are working with APIs that are inconsistent or prone to frequent errors, consider enabling the Continue on Failure flag. Each phase (or step) of the flow will only run successfully if all jobs within that phase complete successfully. If a phase fails, no subsequent phases will continue. However, enabling this flag for each task (off by default) allows the flow to continue to subsequent phases, ending with a warning status if errors are encountered.
-
Finally, to modify the parameters sent to the underlying API call, you can set Task Parameters. Select the task and click Set advanced parameters. When finished, click Set.
Example of the advanced parameter: changing a variable in transformation:
{
"componentId": "keboola.snowflake-transformation",
"configId": "0123abc",
"mode": "run",
"variableValuesData": {
"values": [
{
"name": "variables_name",
"value": 12345
}
]
}
}
Save the changes.
Once you’ve built your flow end-to-end, it may look something like this:
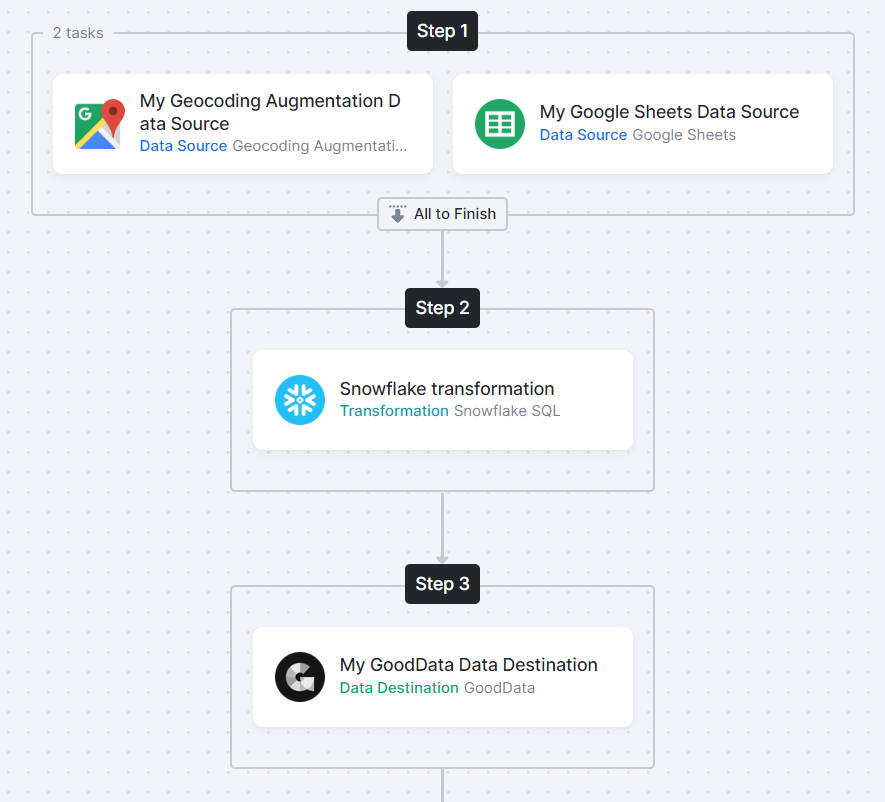
Click Run Flow to start the data pipeline.
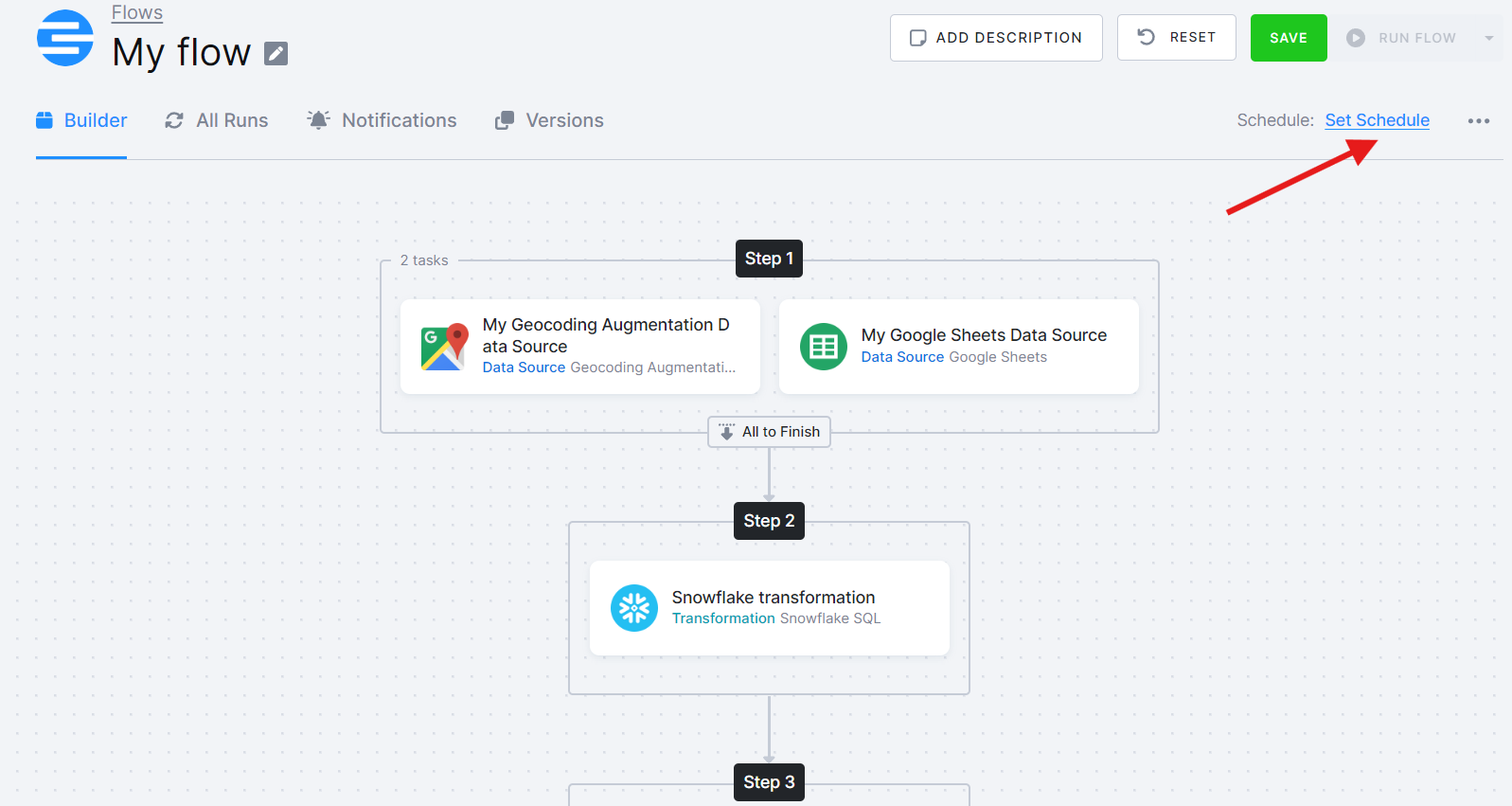
Schedule and Automate
Within the Flow Builder, click on Set Schedule and select when you want the flow to run. You can select predefined intervals or set your own. Another option is to use triggers to initiate the run.
Scheduling: Commonly, flows are set to run at specific times. To avoid busy periods in a shared environment, consider scheduling slightly off-peak for smoother execution.
Triggers: Set flows to automatically start when certain Storage tables are updated (ideal for managing dependencies across projects). Your projects will stay synchronized and run efficiently.
Note on Triggers: If table updates happen during the cool-down period, the trigger is suppressed, but the tables are marked as ready. Therefore, if all configured tables are updated during the cool-down period, the Flow is not scheduled at that time — but once the cool-down expires and any table is updated (causing the trigger to be evaluated), the system recognizes that all tables are already up to date and runs the Flow immediately.
Check Run History
In the tab All Runs, you can check how your flow is running with a detailed breakdown of each task.
In Jobs you’ll see how the flow runs and triggers each individual component sequentially. The status updates in real-time. Once the last of your data source connectors finishes, the transformations will be triggered. After they complete, the data destination connector(s) will run, and the flow will be finalized. In the end, you’ll see either a Success message or an error notification if something went wrong.