Firebolt
- Configuration
- Table Configuration
- Firebolt Table Types
- Firebolt Table Load Settings
- Firebolt Indexes
This data destination connector sends data to a Firebolt database.
Configuration
Create a new configuration of the Firebolt data destination connector.
The first step is to set up credentials:
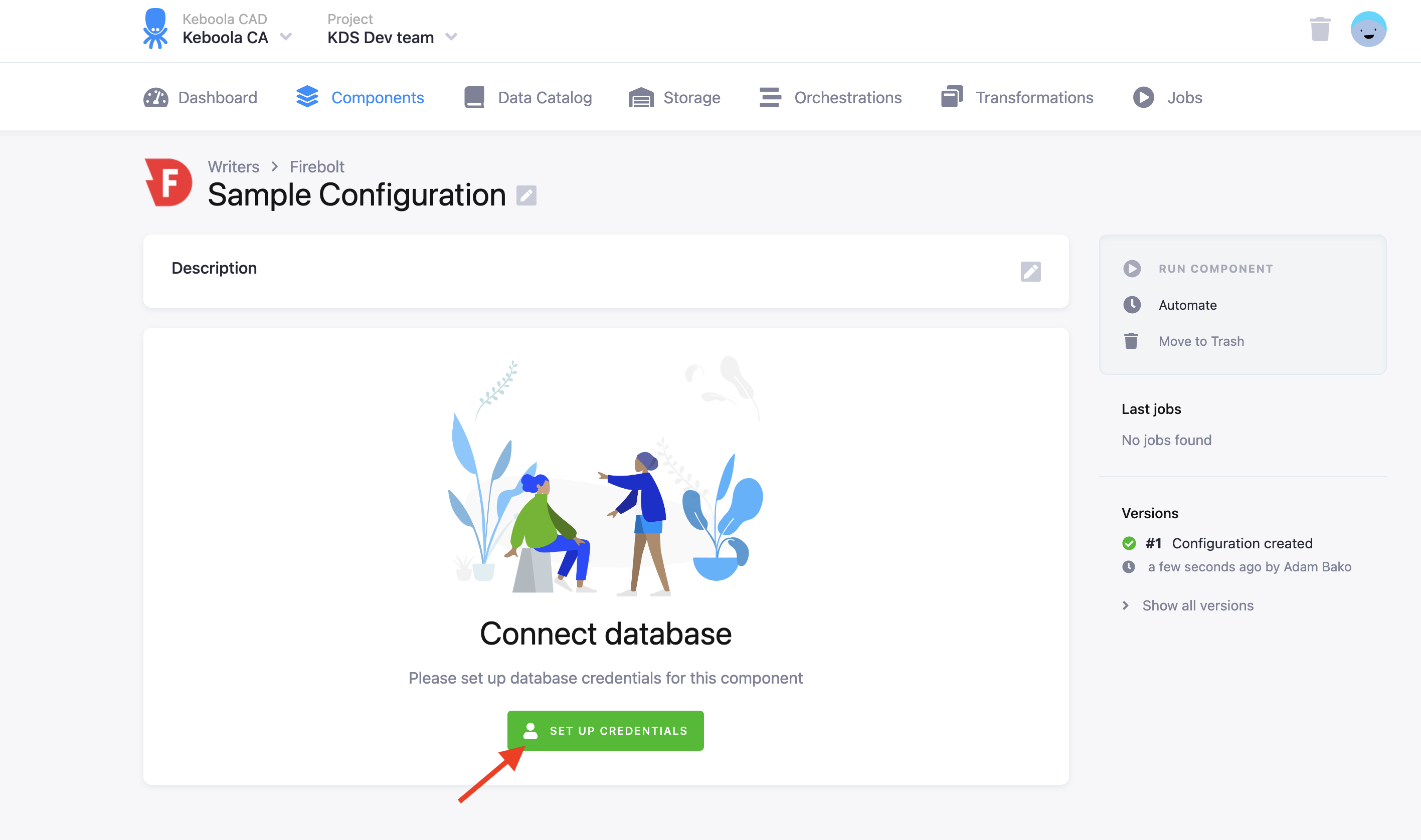
Fill in your Firebolt Username, Password, and Database Name. To use the connector, you must fill in credentials for an S3 bucket, which will be used for staging. The data destination connector will push data to the bucket and Firebolt will download the data from it.
NOTE: The S3 bucket must be in the same region as your Firebolt database.
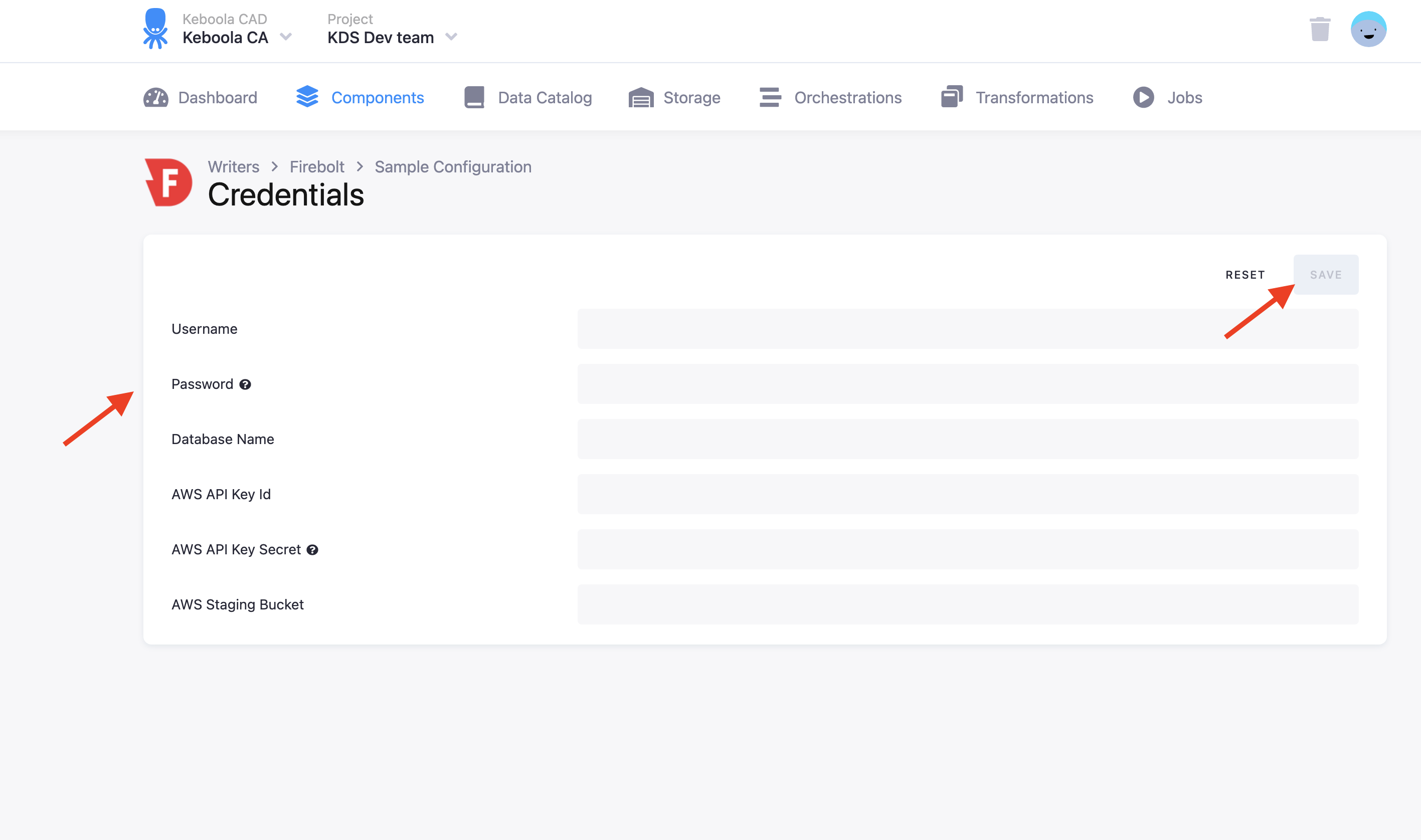
Table Configuration
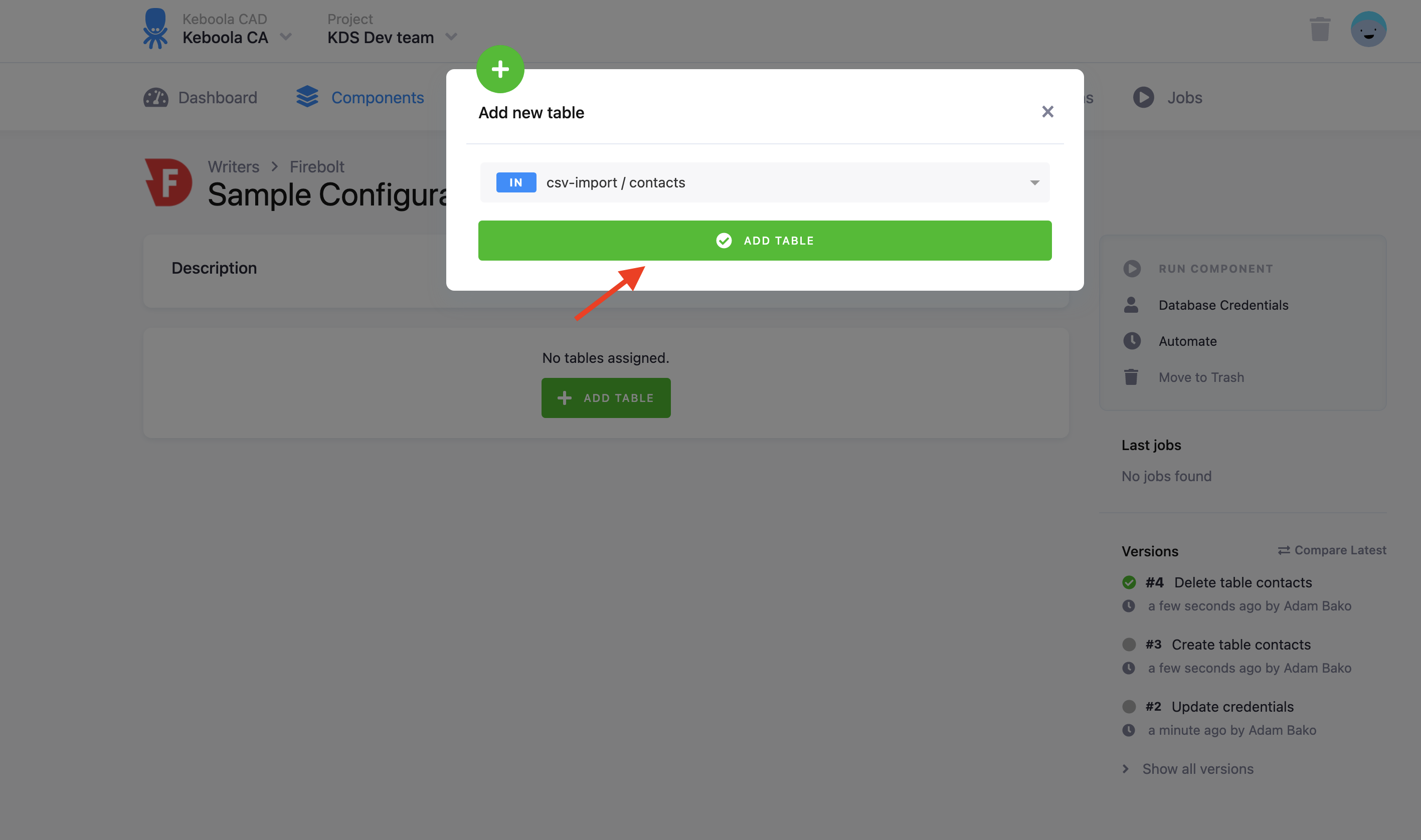
The next step is to configure the tables you want to write. Click Add New Table and select an existing table from Storage:
Then specify table configuration. Use the preview icon to peek at the column contents.
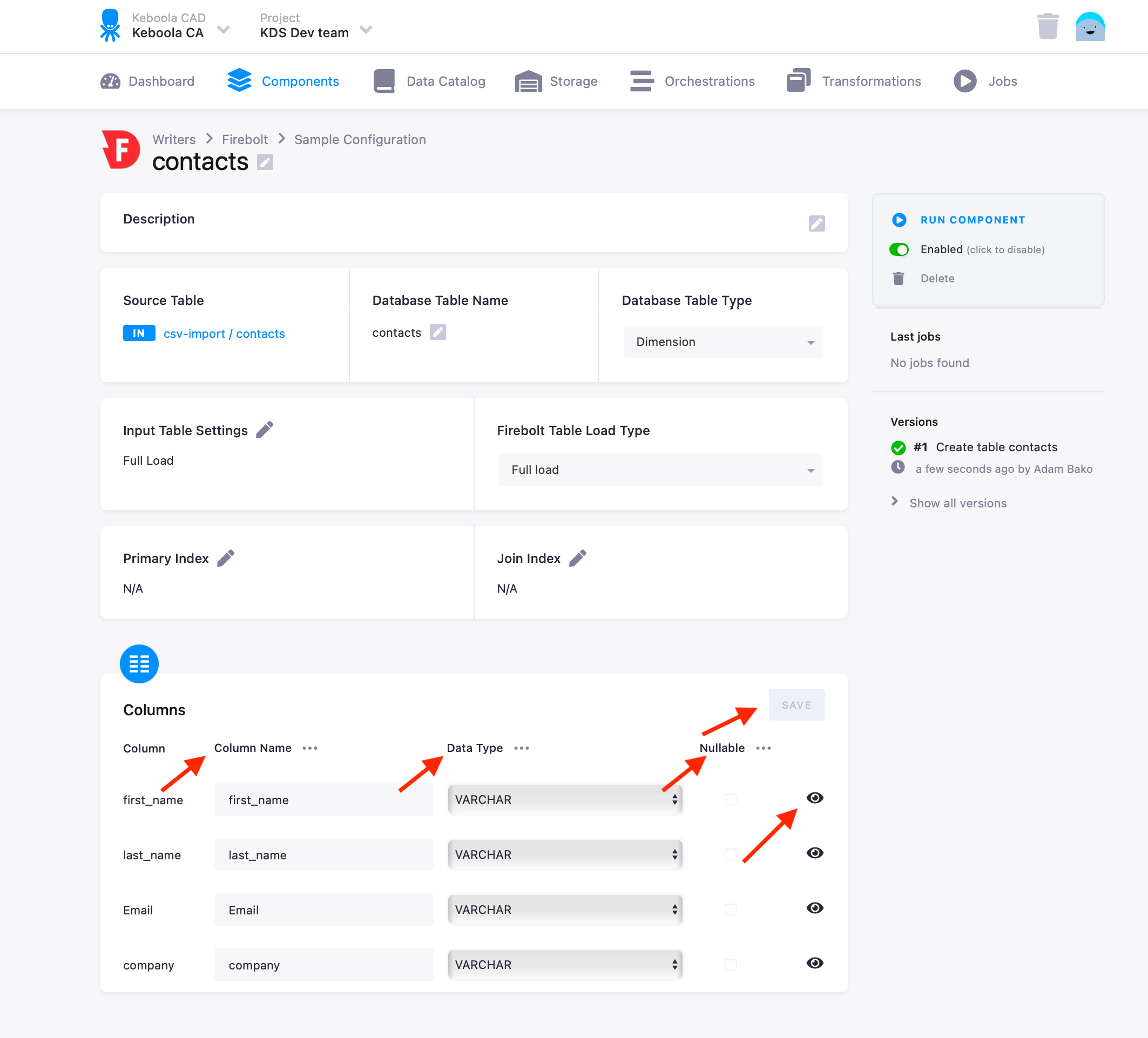
For each column you can specify its
- name in the destination database; you can also use the select box in the table header to bulk convert the case of all names.
- data type (one of Firebolt data types); you can also use the select box in the table header to bulk set the type for all columns. Setting the data type to
IGNOREmeans that the column will not be present in the destination table. - nullable; when checked, the column will be marked as nullable and empty values (
'') in that column will be converted toNULL. Use this for non-string columns with missing data.
The Firebolt connector can take advantage of the column metadata. If they are available, the column types are pre-filled automatically. Make sure to verify the suggested types, however. These data types are taken from the data source and may not be the best choice for the data destination.
When you are done configuring the columns, don’t forget to save the settings.
Input Table Settings
At the top of the page, you can specify the target table name and additional load options. There are three main options for loading the data from Storage — Full Load, Automatic Incremental Load, and Manual Incremental Load.
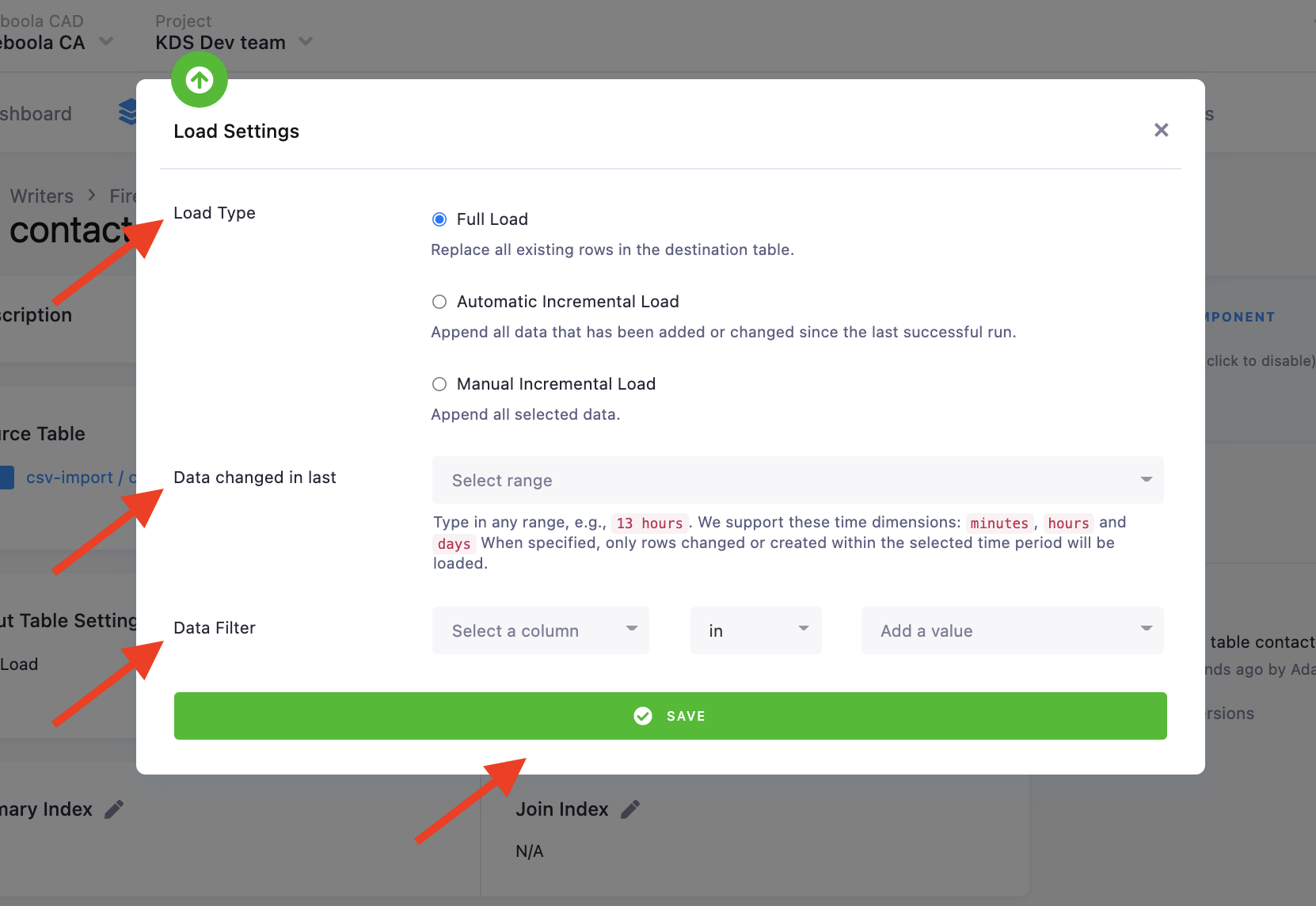
In the Full Load mode all data is fetched from Storage.
In the Automatic Incremental Load mode, the data that has been added or updated since the last run of the component will be fetched.
In the Manual Incremental Load mode, you can select which data will be uploaded based on setting data filters on columns or specify a specific date range of when data was changed to upload.
Firebolt Table Types
In the Database Table Type section of the config you can select either a fact or dimension table.
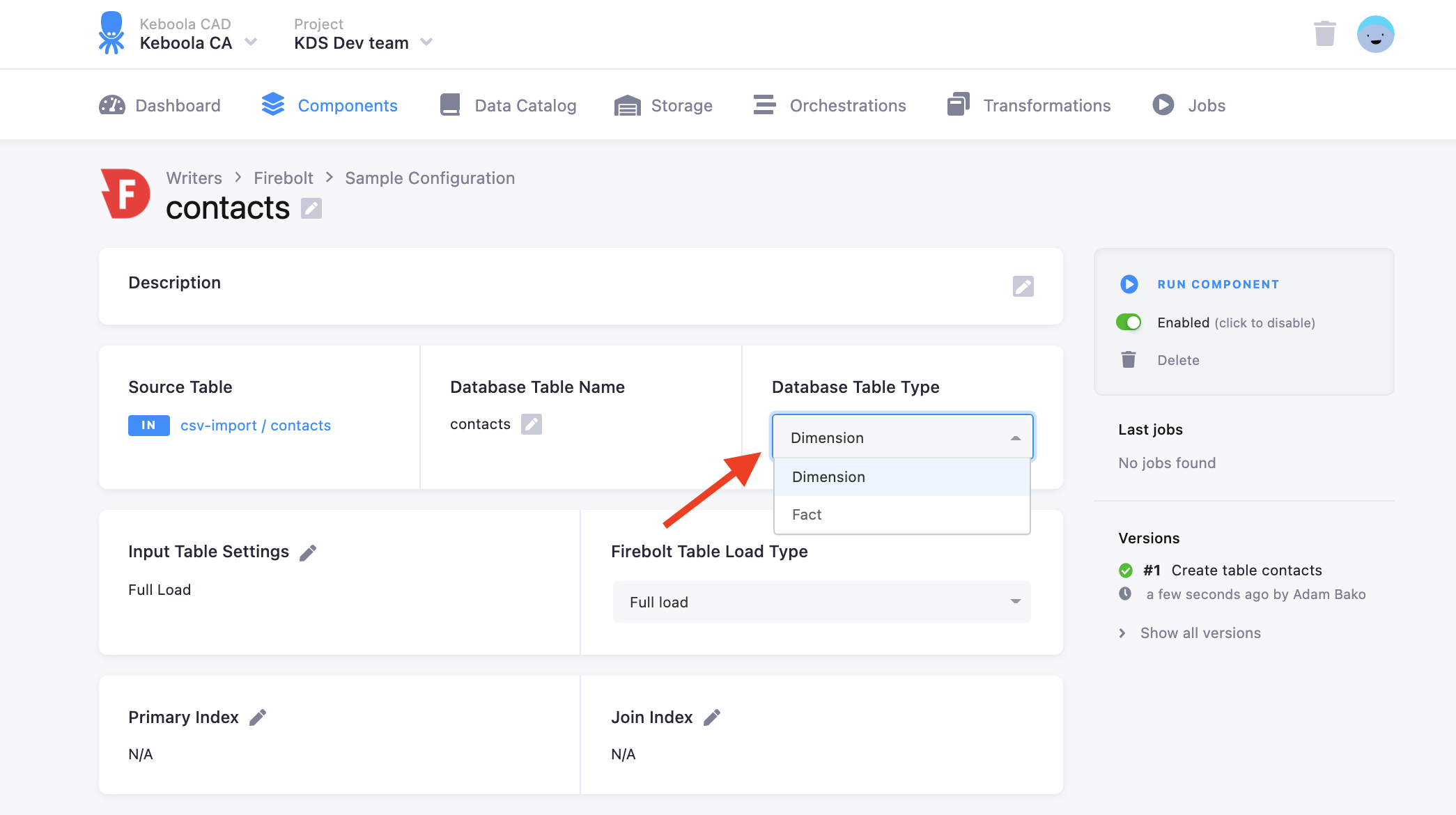
Fact tables should be used for your traditional fact tables - usually your larger and most granular (transaction) tables. Dimension tables should be used for the smaller tables that are typically more descriptive in nature and are joined with the fact tables. If your table does not fit in either of the traditional fact/dimension definition, then it is recommended to define very large tables as fact, and smaller tables as dimension.
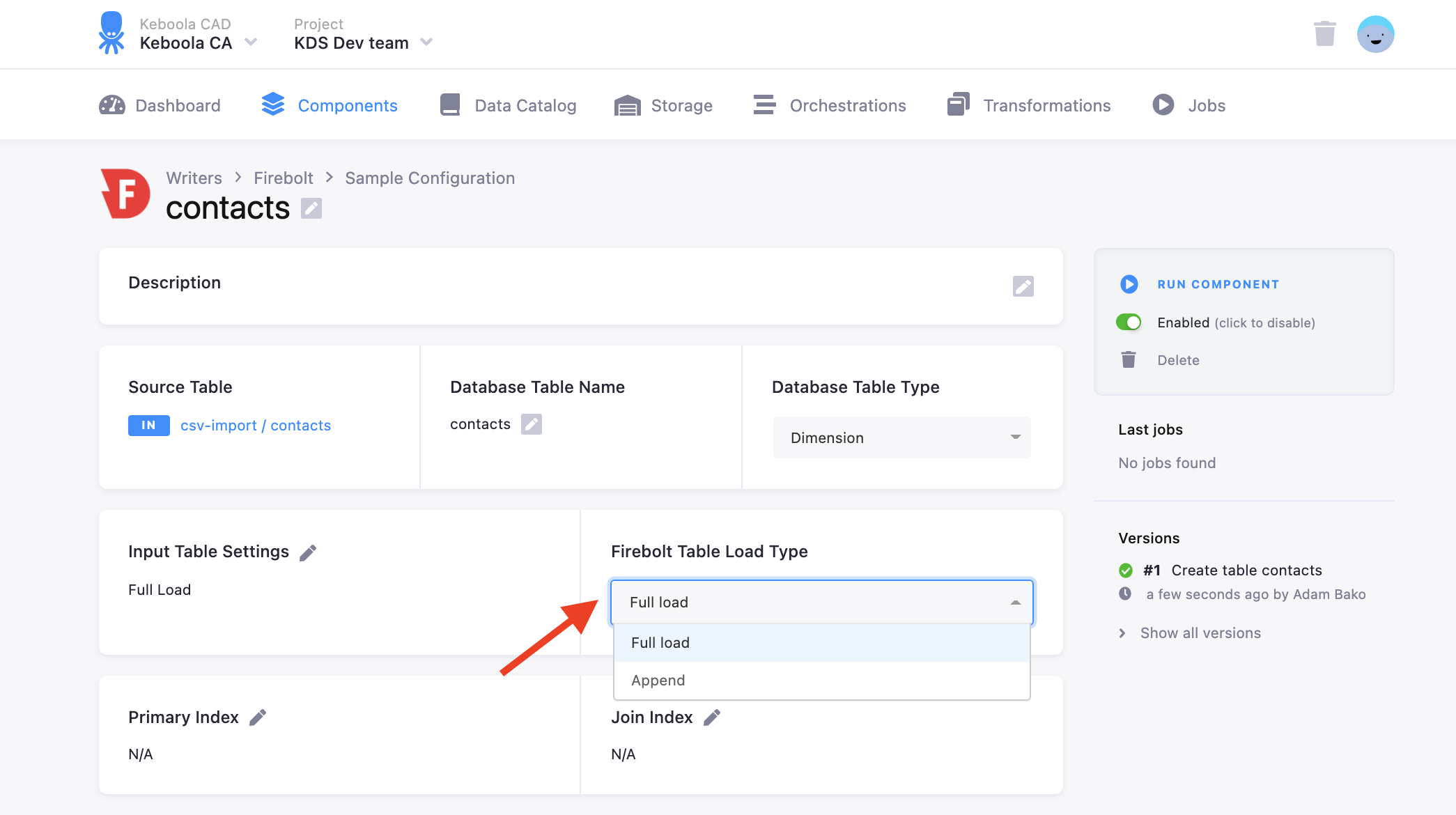
Firebolt Table Load Settings
You can set the type of load for the output to Firebolt using Full Load or Append.
Full Load replaces all the data in the table with data sent from the input table settings. If the table does not exist, it creates it.
Append mode appends data to an existing table. If the table does not exist, it creates it.
Firebolt Indexes
Using this data destination connector you can also set up Firebolt Indexes for your specific table. More information about each index can be found in the following index sections or on the Firebolt documentation page. To set the indexes, click on the pencil icon on either the primary index or join/aggregation index. Join indexes are available for dimension tables and aggregation indexes are available for fact tables.
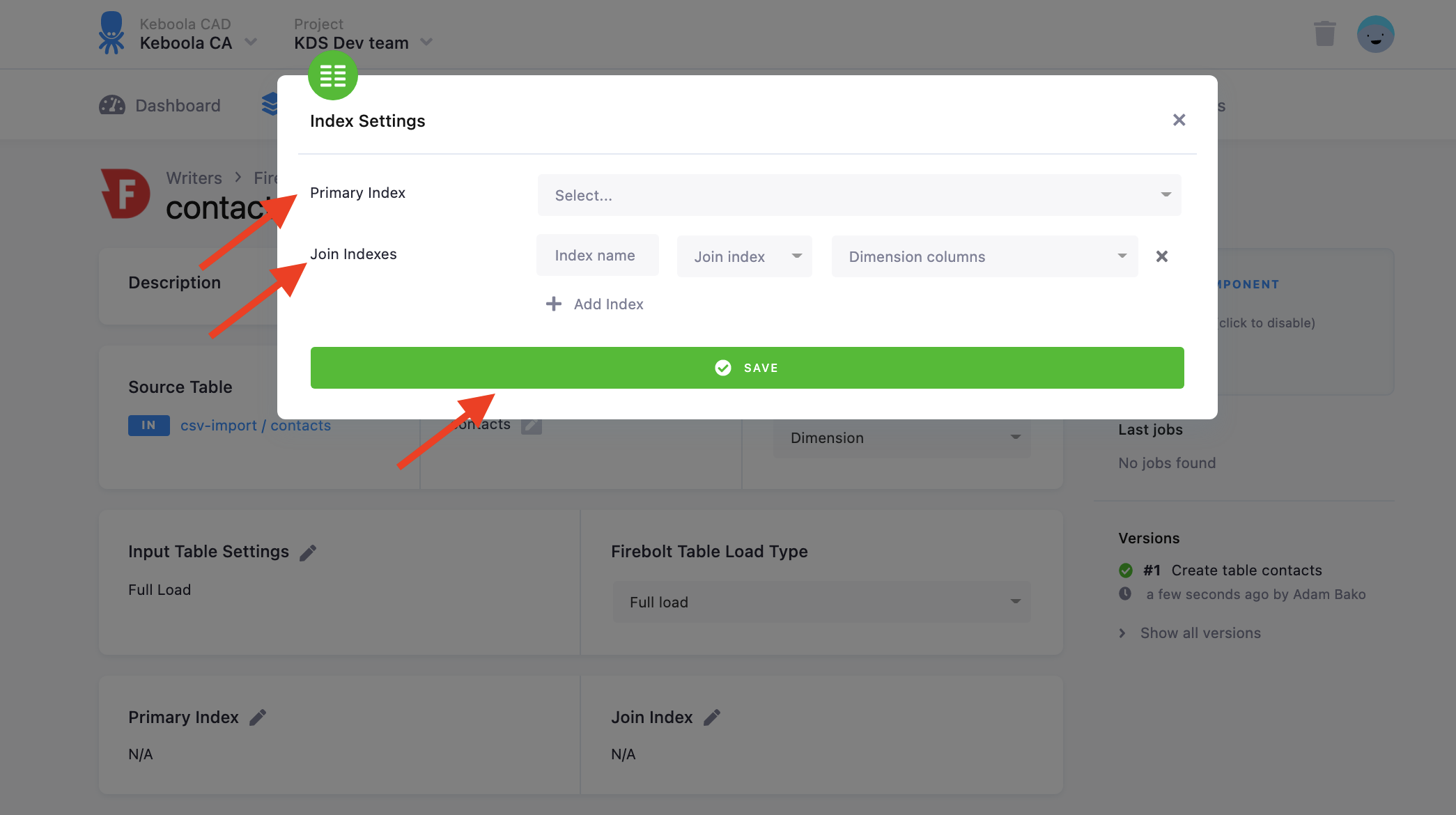
Primary Index
Firebolt tables are persisted in S3 in a proprietary file format called TripleF, aimed to optimize speed and efficiency. One of the unique characteristics of the TripleF format is that it is sorted, compressed, and indexed. What defines the sort order of the files is the primary index defined on the table, which can include one or many fields. Primary indexes are mandatory for fact tables and optional for dimension tables.
Because the primary index determines the physical sort order of the file, it significantly affects performance. For optimal performance, the primary index of fact tables should contain the fields that are most typically filtered or grouped by. This enables most queries to scan physically adjacent data and thus improve query performance. The primary index does not have to be identical to the field/s by which data is partitioned at the source. In dimension tables, the primary key should include the field/s that are used to join the dimension table to the fact table.
A primary index should not be confused with a primary key in traditional database design. Unlike a primary key, the primary index is not unique.
Join Index
Firebolt supports accelerating your joins by creating join indexes. Queries with joins might be resource-consuming and if not done efficiently - joins can take a significant amount of time to complete, which makes them unusable to the user. Using Firebolt’s join indexing saves time searching data in the disk and loading it into memory. It’s already there, indexed by the required join key, and waits to be queried.
You should consider implementing join indexes as best practice in Firebolt to speed up any query that performs a join with a dimension table. This reduces the additional overhead of performing the join to the minimum with the benefit of fast query response times while keeping your cloud bill low.
Aggregation Index
Firebolt incorporates many building blocks to guarantee fast query response times. One of these building blocks is a type of index called an aggregating index. The aggregating index enables you to take a subset of a table’s columns and configure aggregations on top of those columns. Many aggregations are supported from the simple sum, max, min to more complex ones such as count and count (distinct). The index is automatically updated and aggregating as new data streams into the table without having to scan the entire table every time since the index is stateful and consistent.