Customer IO
The Customer IO data source connector uses the Customer IO Beta API to extract customers, campaigns, segments, and activities from your Customer.io account.
Get API Key
To use this connector, you need a bearer token, known as an App API Key from Customer.io. You can generate a key with a defined scope in your account settings. Learn more about bearer authorization in Customer.io.
Configuration
Create a new configuration of the Customer IO connector.
Then insert the API key you obtained from Customer.io.
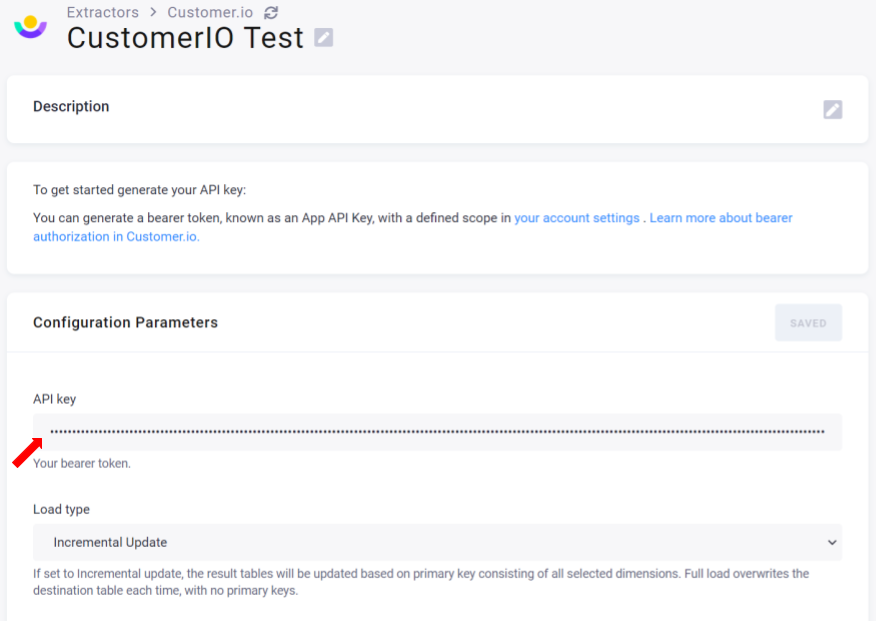
Continue configuring other parameters. Once finished, don’t forget to save everything.
Load Type
Select one of the following two load types:
Incremental Update– updates the result tables based on the primary key consisting of all selected dimensions.Full Load– overwrites the destination table each time, with no primary keys.
Note: When set to incremental updates, the primary key is set automatically based on the selected dimensions. If
the dimension list is changed in an existing configuration, the existing result table might need to be dropped, or the
primary key changed before the load, since its structure will be different. If set to Full Load, no primary key is set.
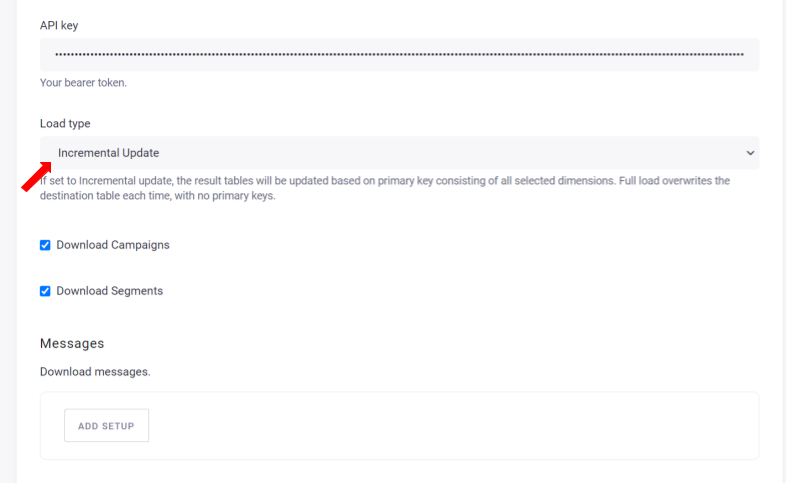
Continue by selecting what data you want to download.
Campaigns
A campaign is a workflow that people in an audience trigger and traverse. Note that the JSON and Array objects
in the actions and tags columns are represented as text.
Columns:
| column | example |
|---|---|
| actions | [{‘id’: 3, ‘type’: ‘email’}, {‘id’: 7, ‘type’: ‘email’}] |
| active | FALSE |
| created | 1591294006 |
| created_by | Leos |
| customer_id | 123x |
| date_attribute | |
| deduplicate_id | 123123:29:00 |
| first_started | 0 |
| frequency | |
| id | 1 |
| name | Onboarding Campaign |
| start_hour | |
| start_minutes | |
| state | draft |
| tags | [‘Sample’] |
| timezone |
Segments
Segments are groups of people, subsets of your audience. You get information about segments and the customers contained by a segment.
Example output:
| deduplicate_id | description | id | name | progress | state | tags | type |
|---|---|---|---|---|---|---|---|
| 26521567:45:00 | Includes all people | 1 | Signed up | finished | dynamic | ||
| 26582936:15:00 | Anyone associated with active customer account. | 13 | Active Customers | finished | dynamic |
Next, select the messages, customers, and/or activities that you wish to download.
Messages
This table contains metadata about messages. You may filter the messages by their type: email, webhook, twilio,
urban_airship, slack, push.
Learn more.
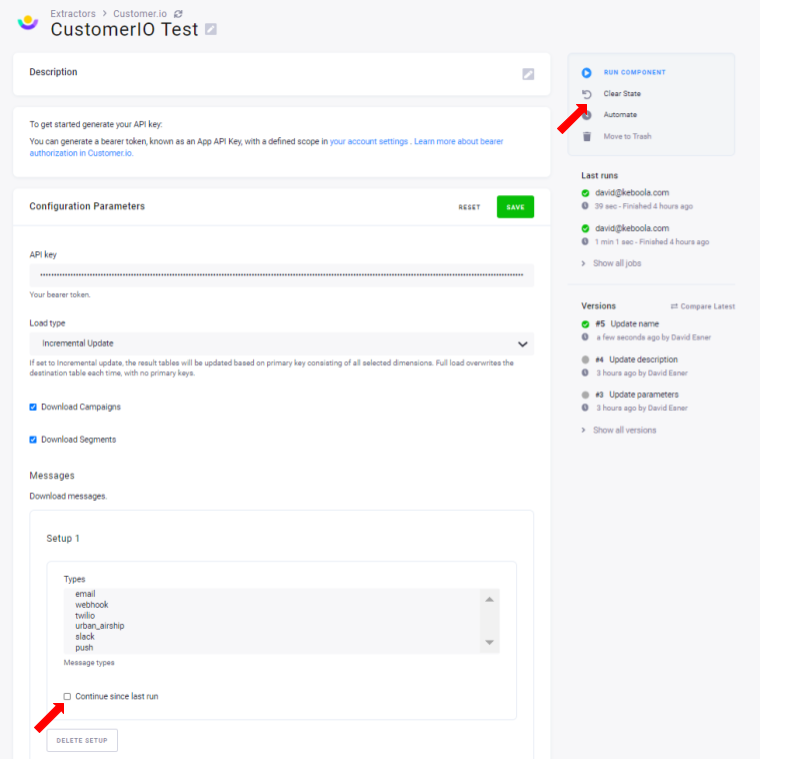
You can select the Continue since last run option. When checked, only those messages that appeared since the last run will be downloaded.
To backfill without changing this attribute, click the Reset State button.
Customers
When downloading customers, you can filter them using JSON. You can also select only the attributes you want to see.
Filter
An additional filter condition in JSON format. The filter language is defined here. If left empty, all users are downloaded.
Example values:
Find the first 2 customers in segment 7 and segment 5=>:{"and":[{"segment":{"id":7}},{"segment":{"id":5}}]}Find the first 10 unsubscribed customers=>:{"attribute":{"field":"unsubscribed","operator":"eq","value":"true"}}}
Attributes
A comma-separated list of required customer attributes. Each customer may have a different set of columns. This is to limit only to attributes you need. All attributes are downloaded if left empty.
Note: It is possible that there are some custom attributes with the same name. E.g., Name and name
or Last name and last_name are considered the same after conversion to a supported Storage format.
You may use appropriate processors to deal with this situation.
Activities
Activities are cards in campaigns, broadcasts, etc. They might be messages, webhooks, attribute changes, etc. You can select the activity types you are interested in. Also, there are two modes of result parsing available to choose from. When done, remember to save your configuration before you run it.
Result parsing
Each activity type may have different columns and table structure. For this reason, the data source connector allows fetching data
in two modes: PARSED_DATA and SINGLE_TABLE.
1) PARSED_DATA will generate structured table for each activity type. E.g., the type event will generate the table activity_event:
| customer_id | data_description | data_project | data_start | id | name | timestamp | type |
|---|---|---|---|---|---|---|---|
| David | test | 1234d | inactive project | 1609808524 | event | ||
| Tom | test2 | 2020-10-19T11:18:55Z | 3467g | enroll | 1603120800 | event | |
| Carl | desc | TS_Test | 667676h | credit grant | 1616382356 | event |
2) SINGLE_TABLE will populate single activities_all table with data unparsed as column.
The data will be present in a data folder as a JSON string.
Example:
| customer_id | data | delivery_id | delivery_type | id | timestamp | type |
|---|---|---|---|---|---|---|
| David | {‘daysofinactivity’: 76, ‘lastactivitydate’: ‘2020-10-21’, ‘project’: ‘test’, ‘projecturl’: ‘example.com’} | 1234d | 1609808524 | event | ||
| Tom | {‘project’: ‘test2’, ‘start’: ‘2020-10-19T11:18:55Z’} | 01EN0Q4 | 1603120800 | event |