Data Apps
- Overview
- Create a Data App
- Secrets
- Access Storage from Data App
- Loading Data from Storage
- Writing Back to Storage
- Deployment and App Management
- Theming
- Sleep and Resume
- AgGrid Enterprise License
- Example Data Apps
Overview
Data apps are simple, interactive web applications that use data to deliver insights or automatically take action. They are usually custom-tailored to tackle a specific problem and enable a dynamic, purpose-built user experience.
Examples of data apps include recommendation engines, interactive segmentation, AI integration, data visualization, customized internal reporting tools for business teams, and financial apps for analyzing spending patterns.
Data apps may be written in any language. However, for now Keboola only supports apps written in Streamlit, a Python framework for the rapid development of such applications.
As mentioned above, a data app is a simple web application, which can be deployed inside a Keboola project and also publicly accessed from outside the project. This means that users accessing your data app do not need access to a Keboola project.
Create a Data App
First, enter a custom prefix for your data app, which you will share with your users later.

There are two ways to create a data app in Keboola. Select a deployment type that will suit your needs:
- Code – Just paste a Streamlit code to create a simple data app.
- Git repository – Specify a Git repository with Streamlit app sources. This is more suitable for complex applications. For repository authentication, you must provide your GitHub username, private access token, or SSH private key.
Code
For simple use cases where your Streamlit code fits on one page, paste the code directly into a text area. This deployment type is ideal for simple apps or for testing. Check out our Titanic Demo App or this example from Streamlit docs.

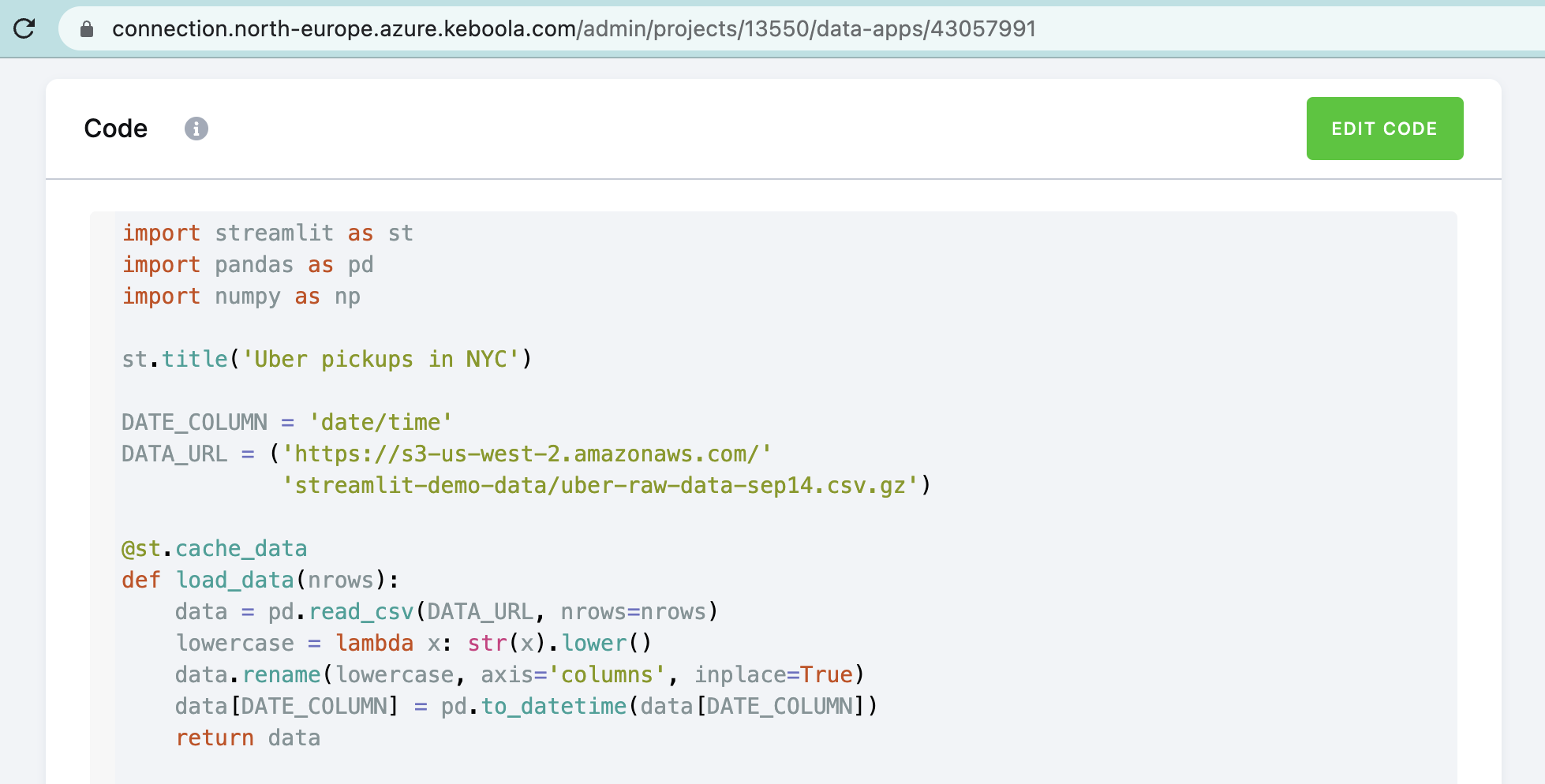
Packages
To use additional Python packages that are not already included in our Streamlit Base Image, enter them into the Packages field.

Git Repository
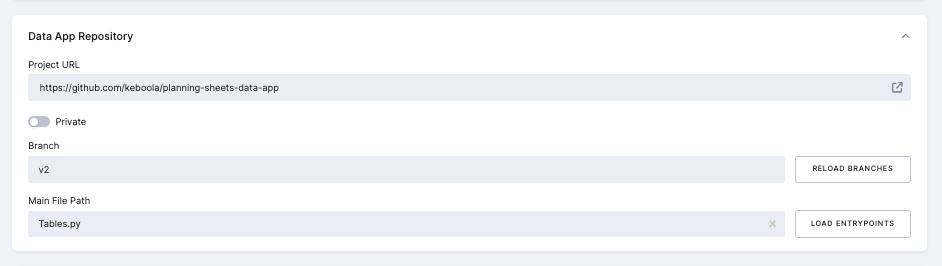
Currently in beta, we only support GitHub repositories.
To provide feedback, use the feedback button in your project. If you have a complex application, push your app sources into GitHub and link the repository in this section. Provide the Project URL, choose the right branch, and finally, select your main entrypoint file.

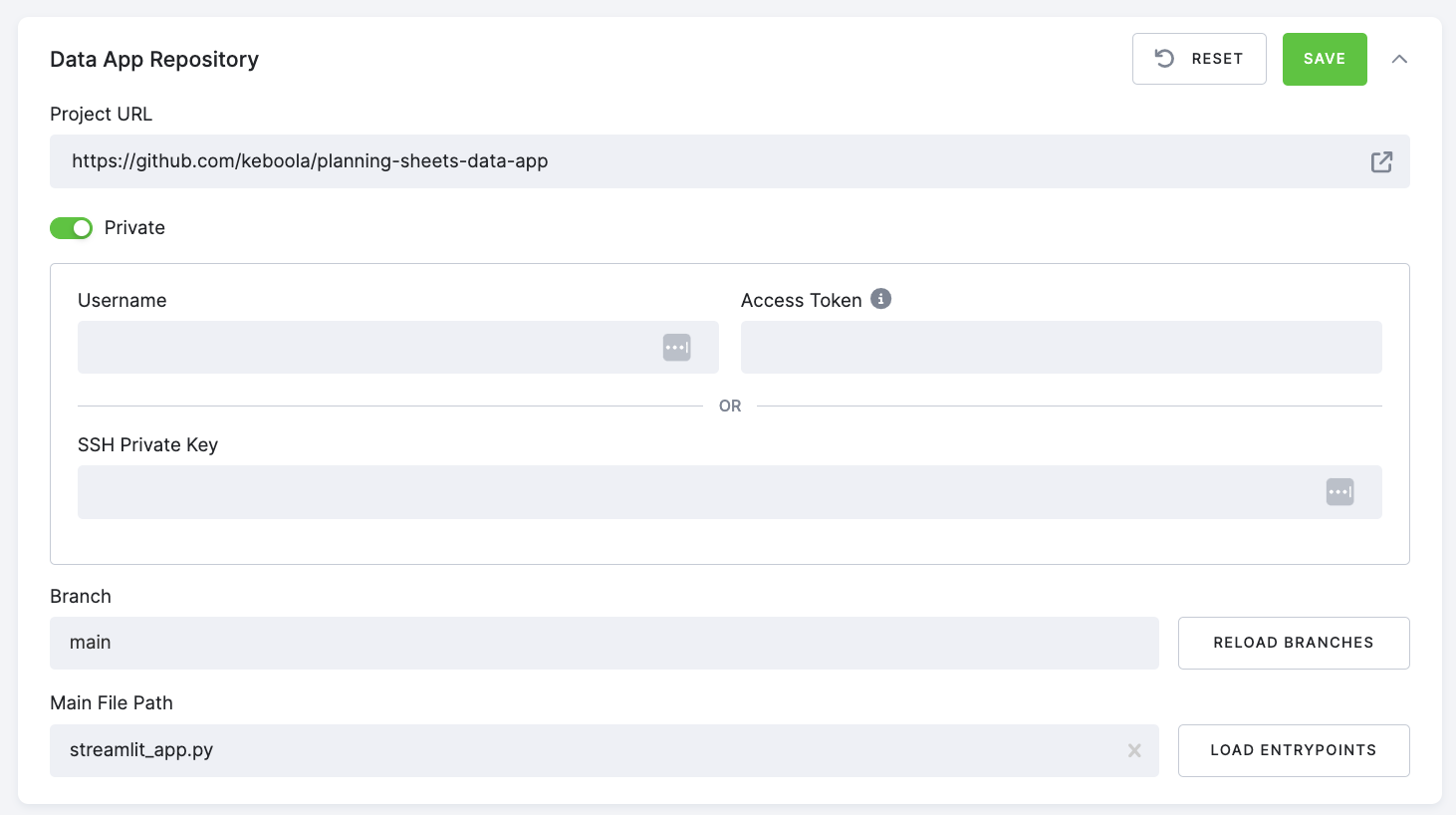
If you are using a private repository, you have two options to authenticate:
- With your GitHub username and personal access token
- With an SSH private key
Follow these steps to authenticate using your GitHub username and personal access token:
-
Generate a personal access token on GitHub by going to your GitHub account settings, selecting Developer settings > Personal access tokens, and clicking Generate new token. Ensure the token has the necessare permissions to access the repository.
-
In Keboola, navigate to the Data App Repository in your data app configuration, check the
Privateoption, and enter your GitHub username and the personal access token you generated in step 1. -
Click Save to authenticate with the private repository.
To authenticate using your SSH private key, follow the instructions in the GitHub manual. After generating your key, enter your SSH private key into the appropriate configuration field and click Save.
Now, you can deploy your data app from the private repository and access it within your Keboola project.
Secrets
To provide your app with environment variables or sensitive information like credentials, API keys, etc., enter them as key value pairs in the section Secrets.
These secrets will be injected into the secrets.toml file upon deployment of the app.
Read more about the Streamlit secrets.
Direct Secrets Upload
You can now upload a secrets.toml file directly through the UI when developing an app from code. The upload process:
- Overwrites existing secrets with matching names.
- Preserves existing secrets that don’t match the uploaded ones.
- Creates new secrets if they don’t exist.
- Does not delete any existing secrets.
Example secrets.toml structure:
[connections]
aws_key = "YOUR_AWS_KEY"
aws_secret = "YOUR_AWS_SECRET"
[api_keys]
openai = "YOUR_OPENAI_KEY"
Best Practices
- Always use descriptive secret names to improve clarity.
- Group related secrets under meaningful sections.
- Back up your secrets configuration regularly.
- Review existing secrets before uploading new ones to avoid unintentional overwrites.
Access Storage from Data App
By default, there are two environment variables available that make it easy to access Keboola Storage from your application:
KBC_URL: This represents the URL of the current Keboola project.KBC_TOKEN: This represents the Storage token with full read-write access to Keboola Storage.
These environment variables can be accessed within your Streamlit data app code. Here is an example of how to initialize the Keboola Storage token:
# Constants
kbc_token = os.environ.get('KBC_TOKEN')
kbc_url = os.environ.get('KBC_URL')
# Initialize Client
client = Client(kbc_url, kbc_token)
These variables represent the project where the application is deployed. To map data from a different project, you need to configure the appropriate secrets.
Loading Data from Storage
To load data from the Storage of a Keboola project into the app, use the input mapping section.
Just select your table in the input mapping section and navigate to that by /data/in/tables/your_data.csv or /data/in/files/fileID_FileName.* in your code.
Note that, while in BETA, the app needs to be redeployed to fetch up-to-date data.
Or you can use the Keboola Storage Python Client in the app to load the data as needed.
See the examples below for usage of the Keboola Storage Python Client.
Writing Back to Storage
For writing data back to Keboola Project Storage, use our Keboola Storage Python Client. See the examples below for usage of the Keboola Storage Python Client.
Deployment and App Management
Once the data app is deployed, its URL will be publicly available! Keboola provides two authorization methods.
Authorization
We recommend using the authorization methods provided by Keboola. Select the method that best suits your app’s requirements and security needs.

Basic authorization
This method allows you to authenticate a user using a password generated by Keboola.

OIDC (OpenID Connect) authorization
This enables users to log into your app using your Single Sign-On (SSO) providers.
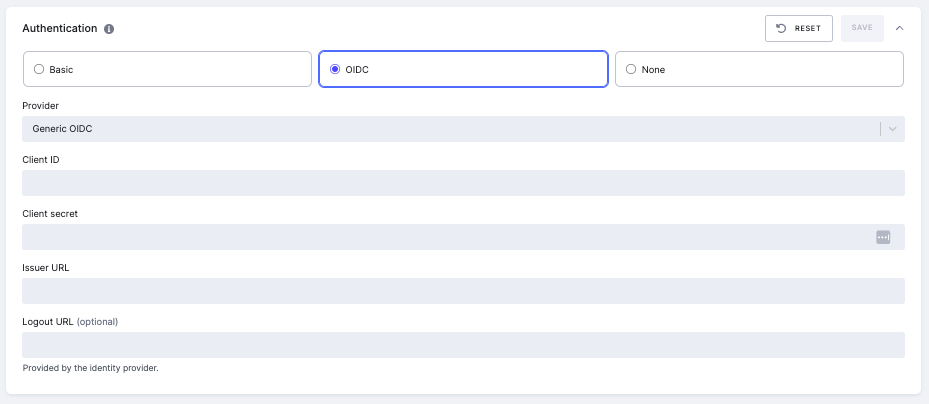
If you enter an app with OIDC, you’ll be asked to select an Authentication Provider and sign in.

None
Alternatively, you may implement your own authorization method within your Streamlit data app. For instance, you can use the Streamlit authenticator. For guidance, check out the Streamlit authenticator tutorial or take a look at our example.

Theming
To configure theming in your data app, you can select from predefined themes or create a custom theme. Predefined themes include Keboola, Light Red, Light Purple, Light Blue, Dark Green, Dark Amber, and Dark Orange. Each theme has a specified primary color, background color, secondary background color, text color, and font. Users choosing Custom can manually set these values.
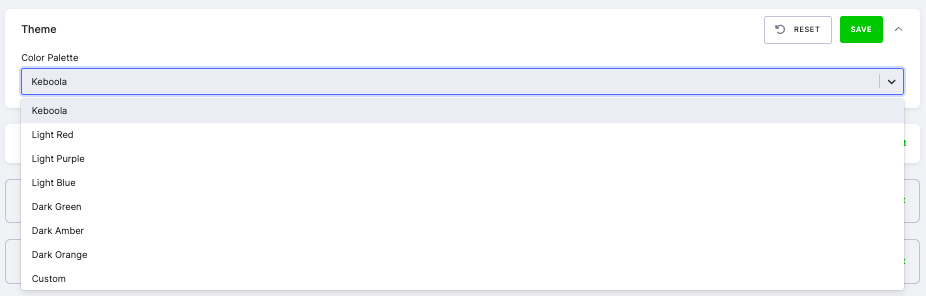
For Custom, users can select colors using the color pickers and choose the desired font from a list.
Predefined Themes:
- Keboola
- Primary Color:
#1F8FFF - Background Color:
#FFFFFF - Secondary Background Color:
#E6F2FF - Text Color:
#222529 - Font: Sans Serif
- Primary Color:
- Light Red
- Primary Color:
#FF5D5D - Background Color:
#FFFFFF - Secondary Background Color:
#FFE6E6 - Text Color:
#222529 - Font: Sans Serif
- Primary Color:
- Light Purple
- Primary Color:
#9A6DD7 - Background Color:
#FFFFFF - Secondary Background Color:
#F2E6FF - Text Color:
#222529 - Font: Sans Serif
- Primary Color:
- Light Blue
- Primary Color:
#0000B2 - Background Color:
#FFFFFF - Secondary Background Color:
#E6E6FF - Text Color:
#222529 - Font: Sans Serif
- Primary Color:
- Dark Green
- Primary Color:
#4CAF50 - Background Color:
#222529 - Secondary Background Color:
#3D4F41 - Text Color:
#FFFFFF - Font: Sans Serif
- Primary Color:
- Dark Amber
- Primary Color:
#FFC107 - Background Color:
#222529 - Secondary Background Color:
#4A3A24 - Text Color:
#FFFFFF - Font: Sans Serif
- Primary Color:
- Dark Orange
- Primary Color:
#FFA500 - Background Color:
#222529 - Secondary Background Color:
#4A3324 - Text Color:
#FFFFFF - Font: Sans Serif
- Primary Color:
Sleep and Resume
Our Suspend/Resume feature helps you save resources by automatically putting your app to sleep after an hour of inactivity. Here’s how it works:
+Activity Monitoring: The app monitors for HTTP requests and active Websocket connections. If no activity is detected for one hour, the app automatically suspends. Please note that an inactive browser tab where your app is open may still cause background activity, potentially preventing your app from sleeping. If you’re using Google Chrome, you may want to enable Memory Saver in the settings which can help preventing such background activity.
Automatic Resumption: As soon as a new request is made to the app, it wakes up and resumes operation. While the resume process is designed to be smooth, the first request upon waking may take slightly longer to process.
Cost Efficiency: For example, if your app is active for two hours and then becomes inactive, it will go to sleep after one additional hour of inactivity. You’ll only be billed for the three hours when the app was active or waiting to suspend.
This feature is not only efficient but also intelligent—ensuring you pay only for what you use, while keeping the app ready for when you need it next.
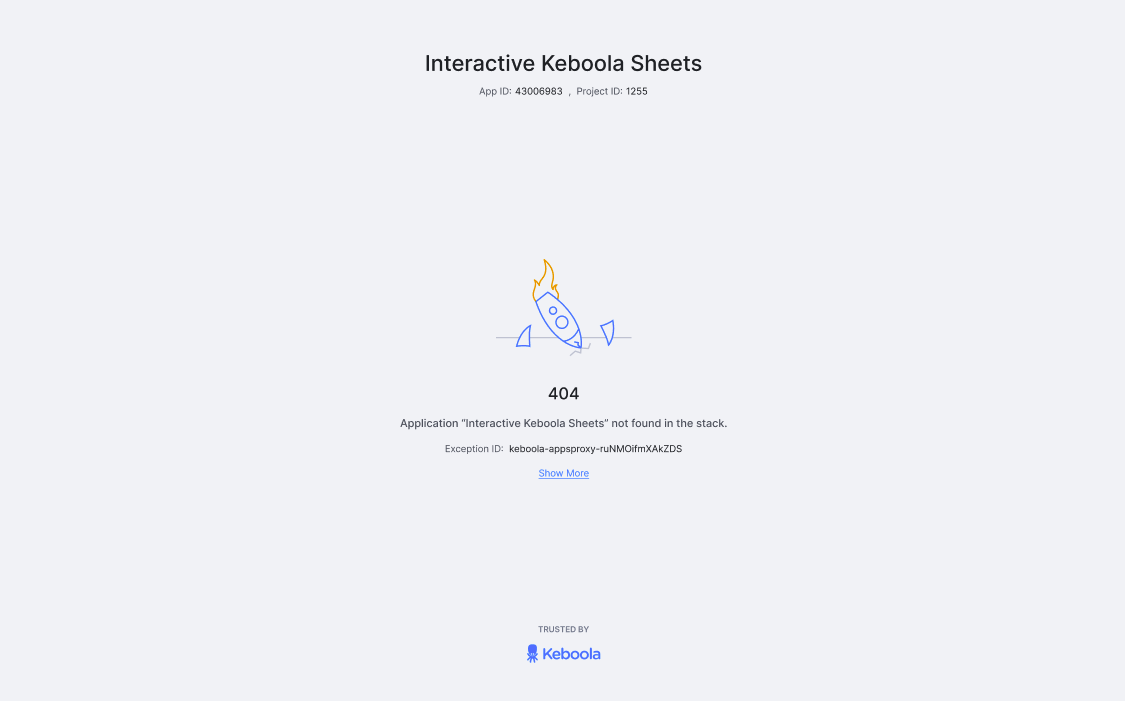
If you enter the URL of a sleeping app, it will trigger its wakeup, and you’ll see a waking up page.
Should anything unexpected occur, a wakeup error page will appear, and you can click Show More to view the error details.
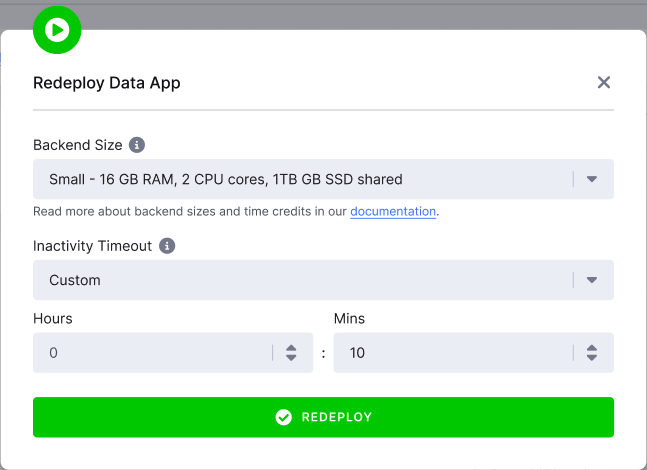
How to Set Up Inactivity Timeout
When you click Deploy or Redeploy for your app, a wizard will appear, prompting you to specify the backend size and the auto-sleep timeout. You can set the duration of inactivity after which the app will go to sleep, with options ranging from five minutes to 24 hours. The default is set to five minutes.
Base Image
When the app is deployed, the code specified in one of the deployment methods will be injected into our base Streamlit Docker image. This image already has Streamlit and a few other basic packages pre-installed:
# Dockerfile
FROM python:3.10-slim
RUN mkdir -m 777 /data \
&& groupadd --gid 1000 appuser \
&& useradd --uid 1000 --gid 1000 -ms /bin/bash appuser
RUN apt-get update && apt-get install -y \
build-essential \
software-properties-common \
git \
jq \
graphviz \
graphviz-dev \
vim \
ssh \
curl \
&& rm -rf /var/lib/apt/lists/*
ENV STREAMLIT_SERVER_PORT=8888
EXPOSE 8888
WORKDIR /home/appuser
USER appuser
ENV PATH="${PATH}:/home/appuser/.local/bin"
# pre install streamlit
RUN mkdir .streamlit \
&& pip install --no-cache-dir \
deepmerge \
graphviz \
keboola.component \
matplotlib \
numpy \
pandas \
plotly \
python-dotenv \
scikit-learn \
seaborn \
streamlit \
streamlit-aggrid \
streamlit-keboola-api \
streamlit_authenticator==0.3.1
COPY src /home/appuser
ENTRYPOINT ["./run.sh"]
# pip list
Package Version
------------------------- -----------
altair 4.2.2
attrs 24.2.0
bcrypt 4.2.1
blinker 1.9.0
cachetools 5.5.0
certifi 2024.8.30
charset-normalizer 3.4.0
click 8.1.7
contourpy 1.3.1
cycler 0.12.1
deepmerge 2.0
entrypoints 0.4
extra-streamlit-components 0.1.71
fonttools 4.55.0
gitdb 4.0.11
GitPython 3.1.43
graphviz 0.20.3
idna 3.10
Jinja2 3.1.4
joblib 1.4.2
jsonschema 4.23.0
jsonschema-specifications 2024.10.1
kiwisolver 1.4.7
markdown-it-py 3.0.0
MarkupSafe 3.0.2
matplotlib 3.9.2
mdurl 0.1.2
numpy 2.1.3
packaging 24.2
pandas 2.2.3
pillow 11.0.0
pip 23.0.1
plotly 5.24.1
protobuf 5.28.3
pyarrow 18.0.0
pydeck 0.9.1
Pygments 2.18.0
PyJWT 2.10.0
pyparsing 3.2.0
python-dateutil 2.9.0.post0
python-decouple 3.8
python-dotenv 1.0.1
pytz 2024.2
PyYAML 6.0.2
referencing 0.35.1
requests 2.32.3
rich 13.9.4
rpds-py 0.21.0
scikit-learn 1.5.2
scipy 1.14.1
seaborn 0.13.2
setuptools 65.5.1
six 1.16.0
smmap 5.0.1
streamlit 1.40.1
streamlit-aggrid 1.0.5
streamlit-authenticator 0.3.1
streamlit-keboola-api 0.2.0
tenacity 9.0.0
threadpoolctl 3.5.0
toml 0.10.2
toolz 1.0.0
tornado 6.4.2
typing_extensions 4.12.2
tzdata 2024.2
urllib3 2.2.3
watchdog 6.0.0
wheel 0.45.0
Please note that the versions of these packages may change, as the newest version of the Streamlit package is used upon deployment unless explicitly specified in the Packages field.
Actions Menu
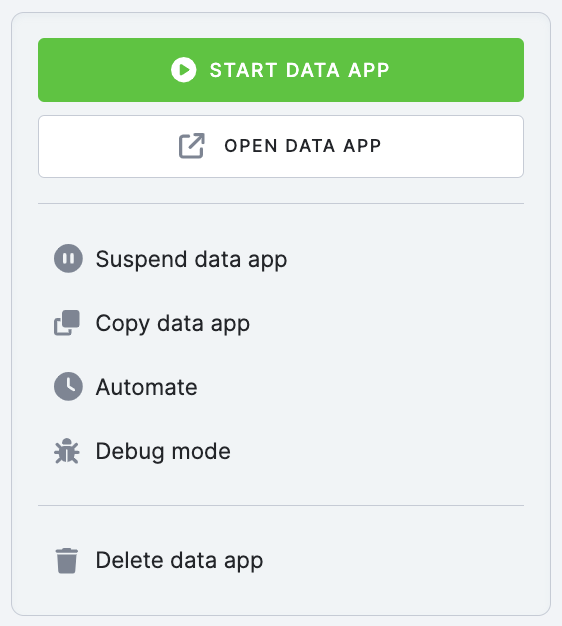
- Deploy Data App – starts the data app. Once the deployment job is finished, you can go to the data app public URL by clicking Open Data App.
- Open Data App – opens a new window with your data app.
- Redeploy – if you made changes in the data app configuration, you have to redeploy it for the changes to take effect.
- Suspend Data App – stops the data app. The container in which the application is running will be stopped, and the app’s URL will no longer be available. The configuration of the app will remain intact.
- Delete Data App – stops the data app deployment and deletes its configuration.
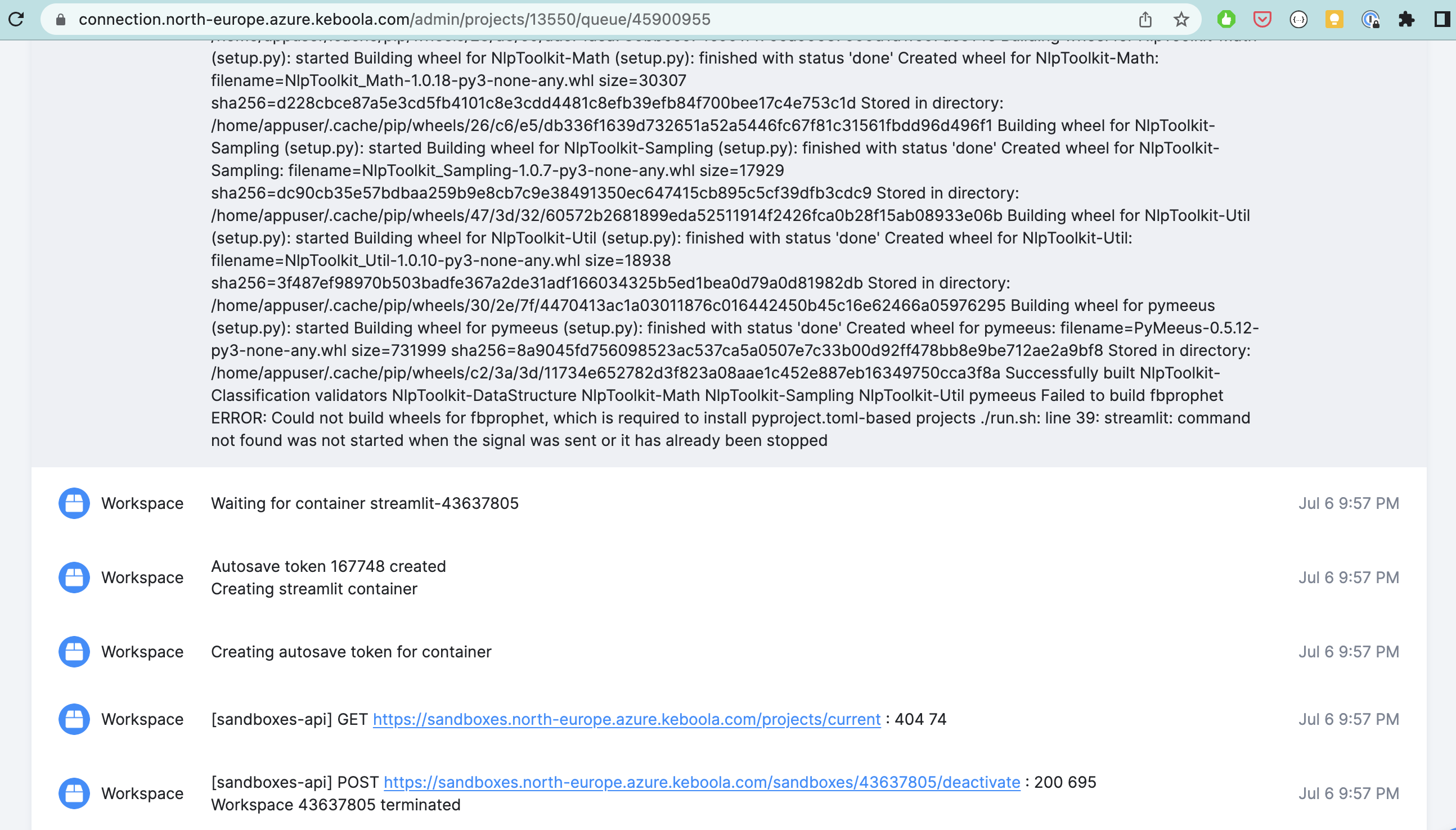
Debugging App Deployment
If the data app’s deployment job fails, you can see the logs from its container in the event log of the deployment job.
For example, there may be a conflict with the specified packages:
AgGrid Enterprise License
The AgGrid Enterprise License is now available for Streamlit Data Apps in Keboola, offering enhanced data manipulation capabilities, including:
- Inline dataset editing.
- Advanced features such as pivoting, filtering, and sorting.
- A professional interface, free from the “trial use only” watermark.
Ensure your data app is configured to use the AgGrid component to take advantage of these enhanced features.
How to Enable the License
The enterprise license is pre-configured for all Keboola stacks, so no additional setup is required for supported applications.
To access the license key in your Streamlit app, use the following code:
import streamlit as st
from keboola_streamlit import KeboolaStreamlit
URL = st.secrets["kbc_url"]
TOKEN = st.secrets["kbc_token"]
keboola = KeboolaStreamlit(URL, TOKEN)
license_key = keboola.aggrid_license_key
You can use this license_key directly in AgGrid.
Reference Implementation:
Keboola Streamlit Integration
Example Data Apps
Hello World
Author: Jordan Burger
This demo data app shows how to create a data app with Streamlit Python code from a code directly in Keboola.
Titanic Demo App
Author: Monika Feigler
This demo data app shows how to create a data app with Streamlit Python code and how to incorporate data and files from an input mapping into your code. This data app allows users to explore and analyze the Titanic dataset using interactive visualizations and filters.
AI-Created Content Checker
Author: Petr Huňka
This demo app offers a cutting-edge solution that leverages Shopify data to supercharge your campaigns. By harnessing the power of artificial intelligence (AI), tailor-made SMS messages are created and delivered through Twilio’s platform. The result? A seamlessly personalized approach that captivates your audience, ensuring your marketing efforts are not only effective but also driven by AI precision.
The complete workflow for this data app can be implemented using the AI SMS Campaign template.
Interactive Keboola Sheets
Author: Petr Huňka
Simplify data editing and management within your company. The data app eliminates the need to export data to external tools, allowing business users to directly access and edit tables stored in Keboola Storage.
This data app, along with the complete workflow, can be implemented using the Interactive Keboola Sheets template.
eCommerce KPI Dashboard
Author: Ondřej Svoboda
This data app provides an interactive display of several business metrics with integrated Slack notifications.
This app, along with the complete workflow, can be implemented using the eCommerce KPI Dashboard template.
Online Marketing Dashboard
Author: Monika Feigler
This demo app provides an overview of the costs for all campaigns across marketing channels.
This data app, along with the complete workflow, can be implemented using the Advertising Platform template.
UA and GA4 Data Comparison
Author: Marketing BI and Keboola
This data app is designed to provide a quick and comprehensive overview of the differences between data gathered by Google’s Universal Analytics (UA) and Google Analytics 4 (GA4).
This app, along with the complete workflow, can be implemented using the UA and GA4 Comparison template.
Kai SQL Bot
Author: Jordan Burger and Pavel Chocholouš
The SQL Bot data app is a dialogue-based AI interface tailored for Snowflake database queries. It allows you to engage in natural conversations and translates your requests into precise SQL commands.
This app, along with the complete workflow, can be implemented using the Kai SQL Bot template.